Spark RDD理解
目录
RDD简介
RDD是弹性分布式数据集(Resilient Distributed Dataset),能在并行计算阶段进行高效的数据共享;RDD还提供了一种粗粒度接口,该接口会将相同的操作应用到多个数据集上并记录创建数据集的‘血统’,从而在不需要存储真正的数据的情况下,达到高效的容错性。
RDD操作类别
RDD操作大致可分为四类:创建操作、转换操作、控制操作、行动操作;在这些大类的基础上还能划为些细类,下面是大部分的RDD操作,以及其细类划分情况。

RDD分区
分区的多少决定RDD的并行粒度;分区是逻辑概念,分区前后可能存储在同一内存;RDD分区之间存在依赖关系,分为宽依赖和窄依赖
宽依赖:多个子RDD分区依赖一个父RDD分区;如join,groupBy操作;
窄依赖:窄依赖:每个父RDD的分区都至多被被一个子RDD的分区使用;如map操作一对一关系
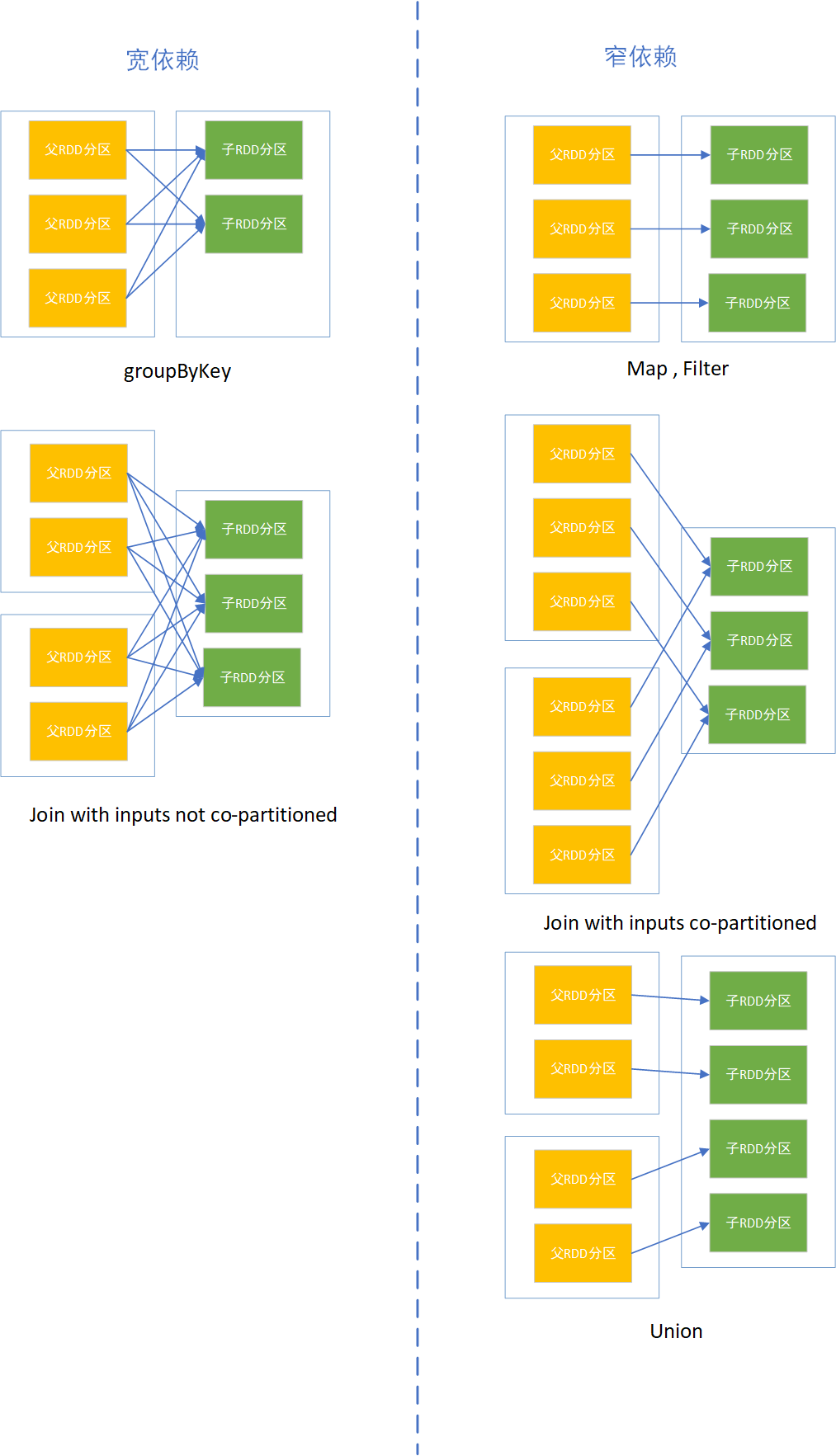
宽依赖和窄依赖作用
窄依赖允许在单个集群节点上流水线式执行,这个节点可以计算所有父级分区;而且,在窄依赖中,节点失败后的恢复更加高效
宽依赖的继承关系中,单个失败节点可能导致一个RDD的所有祖先RDD中的一些分区丢失,导致计算重新执行
RDD分区划分器
spark中RDD计算是以分区为单位的,而计算函数都是在迭代器中复合;分区计算一般使用mapPartitions等计算。
spark提供了两种默认的分区划分器,一种是HashPartitioner(哈希分区划分器),另一种是RangePartitioner(范围分区划分器)
RDD到调度
RDD转换操作属于lazy级别,会延迟执行,作业的提交是由行动操作触发。当执行RDD行动操作时触发作业的提交,然后会根据RDD之间的关系构建DAG(有向无环图),再提交给DAGScheduler进行解析;解析之后会得到调度阶段Stage,也就是taskSet;最后TashScheduler进一步解析得到task,task将会在Worker中Executor里面执行。
Spark RDD理解的更多相关文章
- Spark RDD理解-总结
1.spark是什么 快速.通用.可扩展的分布式计算引擎. 2. 弹性分布式数据集RDD RDD(Resilient Distributed Dataset),是Spark中最基本的数据抽象结构,表示 ...
- [bigdata] Spark RDD整理
1. RDD是什么RDD:Spark的核心概念是RDD (resilient distributed dataset),指的是一个只读的,可分区的弹性分布式数据集,这个数据集的全部或部分可以缓存在内存 ...
- Spark RDD aggregateByKey
aggregateByKey 这个RDD有点繁琐,整理一下使用示例,供参考 直接上代码 import org.apache.spark.rdd.RDD import org.apache.spark. ...
- Spark RDD概念学习系列之RDD的转换(十)
RDD的转换 Spark会根据用户提交的计算逻辑中的RDD的转换和动作来生成RDD之间的依赖关系,同时这个计算链也就生成了逻辑上的DAG.接下来以“Word Count”为例,详细描述这个DAG生成的 ...
- Spark RDD概念学习系列之RDD的checkpoint(九)
RDD的检查点 首先,要清楚.为什么spark要引入检查点机制?引入RDD的检查点? 答:如果缓存丢失了,则需要重新计算.如果计算特别复杂或者计算耗时特别多,那么缓存丢失对于整个Job的影响是不容 ...
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- Spark RDD整理
参考资料: Spark和RDD模型研究:http://itindex.net/detail/51871-spark-rdd-模型 理解Spark的核心RDD:http://www.infoq.com/ ...
- Spark RDD概念学习系列之rdd持久化、广播、累加器(十八)
1.rdd持久化 2.广播 3.累加器 1.rdd持久化 通过spark-shell,可以快速的验证我们的想法和操作! 启动hdfs集群 spark@SparkSingleNode:/usr/loca ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
随机推荐
- 10 套华丽的 CSS3 按钮推荐
在过去的Web开发中,通常使用Photoshop来设计按钮的样式.不过随着CSS3技术的发展,你完全可以通过几行代码来定制一个漂亮的按钮,并且还可以呈现渐变.框阴影.文字阴影等效果.此类按钮最大的优势 ...
- iOS设计模式 - 外观
iOS设计模式 - 外观 原理图 说明 1. 当客服端需要使用一个复杂的子系统(子系统之间关系错综复杂),但又不想和他们扯上关系时,我们需要单独的写出一个类来与子系统交互,隔离客户端与子系统之间的联系 ...
- linux下安装rar以及rar相关命令参数详解
Linux平台默认是不支持RAR文件的解压,需要安装Linux版本的RAR压缩软件,下载地址:http://www.rarlab.com/download.htm 下载之后进行解压之后,进入rar目录 ...
- 骑士周游问题跳马问题C#实现(附带WPF工程代码)
骑士周游问题,也叫跳马问题. 问题描述: 将马随机放在国际象棋的8×8棋盘的某个方格中,马按走棋规则进行移动.要求每个方格只进入一次,走遍棋盘上全部64个方格. 代码要求: 1,可以任意选定马在棋盘上 ...
- ONOS的安装
ONOS的简介 ONOS(Open Network Operating System)开放网络操作系统,由 ON.Lab 使用 Java 及 Apache 实现发布的首款开源的SDN网络操作系统. O ...
- 异常处理与MiniDump详解(1) C++异常(转)
异常处理与MiniDump详解(1) C++异常 write by 九天雁翎(JTianLing) -- blog.csdn.net/vagrxie 讨论新闻组及文件 一. 综述 我很少敢为自己写 ...
- markdown编辑器安装
打算使用MarkDown了,打算整理自己的知识了. 多年以前,喜欢将自己看到好东西,转载在博客.或者将遇到过的问题以及解决方案,记录在博客.06毕业后为了生活折腾,Tom网上的博客无暇东顾,等稳定闲下 ...
- [SDOI2016]数字配对
题目 发现要求配对的条件是这样 \[a_j|a_i,\frac{a_i}{a_j}=p_1\] 我们考虑一下再来一个\(a_k\),满足 \[a_k|a_j,\frac{a_j}{a_k}=p_2\] ...
- 【bzoj3456】 城市规划
题目 一句话题意,无向连通图计数 技不如人,甘拜下风 设\(f_i\)表示\(i\)个节点构成的无向连通图数量 之后...之后就不会了 于是抄题解 考虑容斥 \[f_i=t_i-\sum_{j=1}^ ...
- 【[HAOI2011]向量】
靠瞎猜的数学题 首先我们先对这些向量进行一顿组合,会发现\((a,b)(a,-b)\)可以组合成\((2a,0)\),\((b,-a)(b,a)\)可以组合成\((2b,0)\),同理\((0,2a) ...