<机器学习实战>读书笔记--决策树
1、决策树的构造
createBranch伪代码:
检测数据集中的每个子项是否属于同一分类:
IF SO RETURN 类标签
ELSE
寻找划分数据集的最好特征
划分数据集
创建分支节点
FOR 每个划分的子集
调用函数createBranch并增加返回结果到分支节点中
RETURN 分支节点
划分数据集的大原则:将无序的数据变的更加有序。在划分数据集之前之后信息发生的变化称为信息增益,获得信息增益最高的特征就是最好的选择
熵定义为信息的期望值。熵越大越离散。
计算给定数据集的香农熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet: #the the number of unique elements and their occurance
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2) #log base 2
return shannonEnt
2.决策树的构造算法
ID3算法
ID3算法是一种分类决策树算法。他通过一系列的规则,将数据最后分类成决策树的形式。分类的根据是用到了熵这个概念。熵在物理这门学科中就已经出现过,表示是一个物质的稳定度,在这里就是分类的纯度的一个概念。公式为:
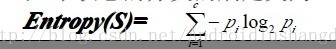
C4.5算法
C4.5与ID3在核心的算法是一样的,但是有一点所采用的办法是不同的,C4.5采用了信息增益率作为划分的根据,克服了ID3算法中采用信息增益划分导致属性选择偏向取值多的属性。信息增益率的公式为:
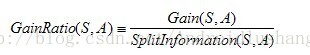
分母的位置是分裂因子,他的计算公式为:
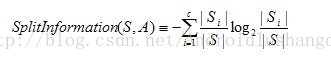
CART算法
CART算法对于属性的值采用的是基于Gini系数值的方式做比较,gini某个属性的某次值的划分的gini指数的值为:

<机器学习实战>读书笔记--决策树的更多相关文章
- 机器学习实战 - 读书笔记(13) - 利用PCA来简化数据
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第13章 - 利用PCA来简化数据. 这里介绍,机器学习中的降维技术,可简化样品数据. ...
- 机器学习实战 - 读书笔记(12) - 使用FP-growth算法来高效发现频繁项集
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第12章 - 使用FP-growth算法来高效发现频繁项集. 基本概念 FP-growt ...
- 机器学习实战 - 读书笔记(11) - 使用Apriori算法进行关联分析
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第11章 - 使用Apriori算法进行关联分析. 基本概念 关联分析(associat ...
- 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习笔记,这次是第7章 - 利用AdaBoost元算法提高分类性能. 核心思想 在使用某个特定的算法是, ...
- 机器学习实战 - 读书笔记(06) – SVM支持向量机
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习笔记,这次是第6章:SVM 支持向量机. 支持向量机不是很好被理解,主要是因为里面涉及到了许多数学知 ...
- 【转载】 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
原文地址: https://www.cnblogs.com/steven-yang/p/5686473.html ------------------------------------------- ...
- 机器学习实战 - 读书笔记(14) - 利用SVD简化数据
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第14章 - 利用SVD简化数据. 这里介绍,机器学习中的降维技术,可简化样品数据. 基 ...
- 机器学习实战读书笔记(二)k-近邻算法
knn算法: 1.优点:精度高.对异常值不敏感.无数据输入假定 2.缺点:计算复杂度高.空间复杂度高. 3.适用数据范围:数值型和标称型. 一般流程: 1.收集数据 2.准备数据 3.分析数据 4.训 ...
- <机器学习实战>读书笔记--朴素贝叶斯
1.朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法, 最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Bayesian Model, ...
随机推荐
- c#格式化字符
1.格式化货币(跟系统的环境有关,中文系统默认格式化人民币,英文系统格式化美元) string.Format("{0:C}",0.2) 结果为:¥0.20 (英文操作系统结果:$0 ...
- EAS_AOP分布式事务
在System.Transactions事务体系中,为事务提供了7种不同的隔离级别.这7中隔离级别分别通过 System.Transactions.IsolationLevel的7个枚举项表示. pu ...
- 记录---IIS显示asp.net程序的具体错误
原来IIS设置成显示单一的错误页面 但是最近的服务器页面报错,但是本地确实完好的:所以想着让服务器显示具体的报错 网上找到两种方法: 先说第一种有效的: 通过 web.config 配置 其实,上面在 ...
- Atom打造优雅的MarkDown 编辑器
1.下载Atom https://atom.io/ 2.安装Atom 双击自动安装,会默认安装到C盘,无法修改. 3.安装simplified-chinese-menu 插件 这是一个可以将软件汉化的 ...
- Exp5 MSF基础应用 20164323段钊阳
网络对抗技术 20164323 Exp5 MSF基础应用 靶机 ip:192.168.1.229 kali ip:192.168.1.216 exploit选取 主动攻击:ms17_010_psexe ...
- ajax1—php(27)
一 简介 web程序工作原理图: 传统的web程序工作原理图: Ajax工作原理图: 1. 关于Ajax l Asynchronous 异步 l JavaScript l And l XML ...
- js正则包含三位
var reg = new RegExp("^(?![A-Za-z]+$)(?![A-Z\\d]+$)(?![A-Z_\\W]+$)(?![a-z\\d]+$)(?![a-z_\\W]+$) ...
- django实战-留言板
对应github链接:https://github.com/pshyms/django/tree/master/liuyanban 第一天 1. 创建一个新项目后,新建一个应用程序 python ma ...
- Ionic2使用TypeScript调用自定义JavaScript脚本
在项目app目录下面写一个.d.ts 里面声明你要引用JS库里面定义的变量,变量名要保持一致 declare var Strophe: any; 然后把JS库放在www目录下面 然后在index.ht ...
- linux之getenv putenv setenv和unsetenv详解
1.getenv函数 头文件:#include<stdlib.h> 函数原型: char * getenv(const char* name); 函数说明:getenv()用来取得参数na ...