完全用nosql轻松打造千万级数据量的微博系统(转)
原文:http://www.cnblogs.com/imxiu/p/3505213.html
其实微博是一个结构相对简单,但数据量却是很庞大的一种产品.标题所说的是千万级数据量 也并不是一千万条微博信息而已,而是千万级订阅关系之间发布。在看 我这篇文章之前,大多数人都看过sina的杨卫华大牛的微博开发大会上的演讲.我这也不当复读机了,挑重点跟大家说一下。
大家都知道微博的难点在于明星会员问题,什么是明星会员问题了,就是刘德华来咱这开了微博,他有几百万的粉丝订阅者,他发一条微博信息,那得一下子 把微博 信息发布到几百万的粉丝里去,如果黎明、郭富城等四大天王都来咱来开微博,那咱小站不是死翘翘了.所以这时消息队列上场了。在我的架构里 有一个异步publish集群,publish的任务都去zeromq队列读取队列.zeromq是目前已知开源的消息传递最快的一个。具体关于 zeromq可以自己google。zeromq有一个问题是不能持久化数据,这个自己做持久化存储.回过刚才那个话题, 把明星会员的粉丝按照"活跃度"进行分级。"活跃度"是根据登陆频度,时间,发布微博等因素大致分为铁杆粉丝、爱理不理、半死不活三大类分到不同的发布集 群中去. 铁杆粉丝类型的异步发布集群,发布速度肯定是最快的.微博的信息是用handler socket保存到mysql。这个信息ID,是用rdtsc+2位随机整数拼接而成的 64位整数唯一ID,防止出现自增ID出现的多服务器 id一致性的问题. 在publish的时候,集群只是把微博信息的ID发送给redis的订阅者。所以这个数据是很快的。而且订阅者的list里只保存的是ID.在内存的占 用率上也不是很高.
下面我给大家看一下我的mysql和redis数据结构
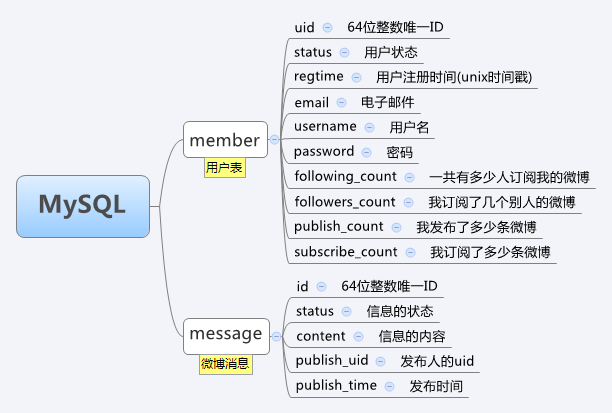

在我的结构中还有一个重要角色就是"Key GPS Server"(简称:KGS)简单来说,这个是分布式数据存储的中心索引服务器.一切数据的存储和获取,都通过KGS来定位. KGS支持多个服务器,多个机房多重备份存储。KGS是以Tokyo Cabinet的hash db为存储的socket server。记录key跟服务器之间的对应关系. KGS的任务就是告知key该存储在哪几台服务器上,或者告知该key存储在哪几台服务器上,并不做其他的服务.这样大大的减轻KGS的压力.
再说一下Redis集群,redis是以纯内存形式模式运行,关闭了热备的功能(redis的热备并不是那么好). 自己写了个backend server.在每台运行redis的机子上都运行着backend socket 进程, backend进程也是以tc的hash db为存储。备份着当前服务器的redis数据。当redis重启的时候,从本机的bakcend db 加载所有数据. Redis的集群是以用户水平切分法来分布的
现在该轮到mysql里, 在这个架构中,基本消除了这边缓存 那边缓存的问题。因为在这个集群中的每个服务都是高速运行的.唯一的一处的cache 就是在php端的eAccelerator local cache. eAccelerator是基于共享内存的,所有速度比基于socket类型的cache快多了. eAccelerator 缓存了用户top N条的微博信息还有从KGS查询的结果。 看到这里有人问了,你把用户信息和微博信息都放在mysql里,怎么能不用cache了.嘿嘿,因为我用了 handler socket。HS 是小日本写的一款mysql插件.HS避开了MySQL通讯协议,直接读取MySQL引擎。在多核、大内存、 InnoDB引擎环境,性能直超memcached.HS能以Key-Value方式直接读写mysql引擎
总结
Google首席科学家讲过一句话,就是一个大的复杂的系统,应该要分解成很多小的服务. 我的这个架构也是由一个个小的集群来共同处理大数据量发布数据。有的人为什么不用mongodb了,因为mongodb是一款大众性的分布式nosql db,我们有自己的key分布策略,不太适合用mongodb. 不理解redis的存储关系的同学,可以先参考一下 Retwis, Retwis是用纯redis实现的简单微博.
具体的架构图、流程图、ppt文件。请下载附件来阅读. http://code.google.com/p/php-tokyocabinet/downloads/detail?name=micro-blog-qiye.tar.bz2&can=2&q=#makechanges
我的QQ: 531020471 mail: lijinxing#gmail.com
两个相关项目:Retwis-py Retwis-RB (用 Python 和 Ruby 实现类本文思路的项目)
From:
完全用nosql轻松打造千万级数据量的微博系统(转)的更多相关文章
- 完全用nosql轻松打造千万级数据量的微博系统
其实微博是一个结构相对简单,但数据量却是很庞大的一种产品.标题所说的是千万级数据量也并不是一千万条微博信息而已,而是千万级订阅关系之间发布.在看 我这篇文章之前,大多数人都看过sina的杨卫华大牛的微 ...
- mysql千万级数据量查询出所有重复的记录
查询重复的字段需要创建索引,多个条件则创建组合索引,各个条件的索引都存在则不必须创建组合索引 有些情况直接使用GROUP BY HAVING则能直接解决:但是有些情况下查询缓慢,则需要使用下面其他的方 ...
- (转载)MYSQL千万级数据量的优化方法积累
转载自:http://blog.sina.com.cn/s/blog_85ead02a0101csci.html MYSQL千万级数据量的优化方法积累 1.分库分表 很明显,一个主表(也就是很重要的表 ...
- php+中文分词scws+sphinx+mysql打造千万级数据全文搜索
转载自:http://blog.csdn.net/nuli888/article/details/51892776 Sphinx是由俄罗斯人Andrew Aksyonoff开发的一个全文检索引擎.意图 ...
- MySQL 千万 级数据量根据(索引)优化 查询 速度
一.索引的作用 索引通俗来讲就相当于书的目录,当我们根据条件查询的时候,没有索引,便需要全表扫描,数据量少还可以,一旦数据量超过百万甚至千万,一条查询sql执行往往需要几十秒甚至更多,5秒以上就已经让 ...
- mysql千万级数据量根据索引优化查询速度
(一)索引的作用 索引通俗来讲就相当于书的目录,当我们根据条件查询的时候,没有索引,便需要全表扫描,数据量少还可以,一旦数据量超过百万甚至千万,一条查询sql执行往往需要几十秒甚至更多,5秒以上就已经 ...
- 2020-06-02:千万级数据量的list找一个数据。
福哥答案2020-06-02: 对于千万级长度的数组单值查找:序号小的,单线程占明显优势:序号大的,多线程占明显优势.单线程时间不稳定,多线程时间稳定. go语言测试代码如下: package mai ...
- MYSQL千万级数据量的优化方法积累
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- BayaiM__MYSQL千万级数据量的优化方法积累__初级菜鸟
-----------------------------------------------------------------------------———————-------------- ...
随机推荐
- js上传本地图片遇到的问题
1.改变页面文件上传默认的样式 <input type="text" size="20" id="upfile" style=&quo ...
- c :函数指针具体解释
在研究opencv源码的过程中.处处可见到函数指针,于是翻出来谭浩强的<C程序设计>把函数指针这一块内容再补一补! 1 定义 数据类型 (*指针变量名)(參数表); 注: 数据类型是指的函 ...
- 在loadrunner中使用winsocket协议编写脚步三部曲
这两天写了一个winsocket的脚本,没有通过录制的方式,是直接手写的.下面贴出来和大家分享: 脚本的写法很简单,大体说来,就像把大象放进冰箱一样,总共分三步: 第一步:把冰箱门打开. //建立到服 ...
- 对ChemDraw Professional 16.0你了解多少
ChemDraw Professional 16.0组件为科学家提供了最新的科学智能应用程序组件,绘制化学结构图和分析生物路径图. ChemDraw Professional 16.0 ChemDr ...
- 如何:为 IIS 7.0 配置 <system.webServer> 节
https://technet.microsoft.com/zh-cn/sysinternals/bb763179.aspx https://www.cnblogs.com/tl2f/p/501615 ...
- WebService远程调用(代码调用)
在做多个系统集成的时候,由于各系统厂商采用不同的架构,在项目实施前期,各业务对业务理解不够深入,系统接口可能会有较多变化, 在此背景下,动态调用webserivce就变得灵活了,降低了系统集成的耦合度 ...
- 件测试专家分享III GUI自动化测试相关
GUI自动化:效率为王—脚本与数据解偶 页面对象模型的核心理念是,以页面(Web Page或者Native App Page)为单位来封装页面上的空间以及控件部分操作. 而测试用力,更确切的说是操作函 ...
- linux命令之用户和用户组
知识点: 1.-rwx--x--x (711) 只有所有者才有读,写,执行的权限,组群和其他人只有执行的权限 2.将root用户添加到supergroup用户组 groupadd supergroup ...
- m2014-architecture-imgserver->Lighttpd Mod_Cache很简单很强大的动态缓存
Lighttpd是一个德国人领导的开源软件,其根本的目的是提供一个专门针对高性能网站,安全.快速.兼容性好并且灵活的web server环境.具有非常低的内存开销,cpu占用率低,效能好,以及丰富的模 ...
- Apache nutch1.5 & Apache solr3.6
第1章引言 1.1nutch和solr Nutch 是一个开源的.Java 实现的搜索引擎.它提供了我们运行自己的搜索引擎所需的全部工具. Solr 拥有像 web-services API 的独立的 ...