IPv4协议及VLSM可变长子网划分和CIDR无类域间路由
IPv4协议及VLSM可变长子网划分和CIDR无类域间路由
来源 https://blog.csdn.net/hongse_zxl/article/details/50054817
互联网世界一切通信都将IP化。IT行业无论你用哪种语音(C++,Java,PHP等),无论你偏软件或偏硬件,最大公约数之一可能就有IP。国家在搞三网融合,即Internet,电话网,有线电视网将全用IP数据包传输数据。可以说IP是网络的基石。本篇是我对IP协议包括VLSM和CIDR的理解。
IP的责任简单地说就是将数据从源传送到目的地。IP协议被封装在TCPIP 5层协议中的网络层上,具体格式如下:(以下是我个人对IP包头的理解,权威的请查阅wikipedia或RFC791,另文中出现的IP均指IPv4)
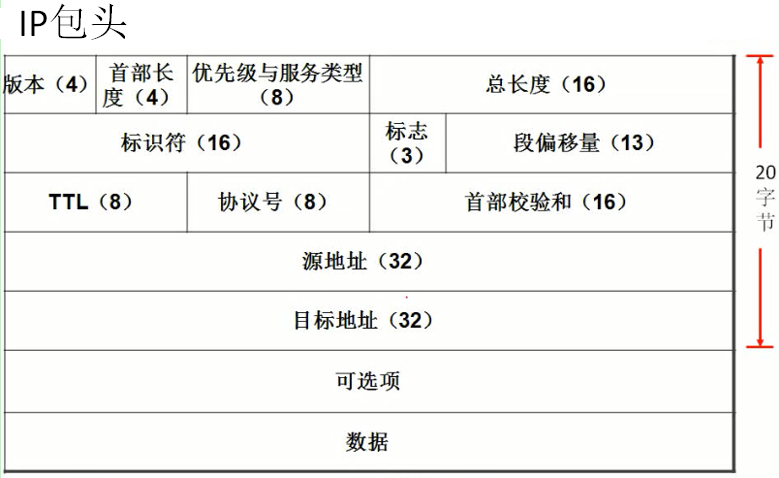
1.版本(4位):
4或6,表示IPv4还是IPv6
2.首部长度(4位):
指明IP包头部长度(不包含数据)。如没有可选项长度是20 byte。可选项最大40 byte,因此IP包头部最大长度是60 byte
3.优先级与服务类型(8位)(直接RFC791上截图了):

4.总长度(16位):
IP包的长度,总长度 - 首部长度 = 数据长度
5.标识符(16位),标志(3位),段偏移量(13位):
三个结合在一起使用,用于数据分包。比如A->B->C,A的MTU是1500,B的MTU是1000,那B收到A的包转发给C时就要分包:第一个包1000,第二个包500。
标识符(16位):分包后,每个包上标记相同的值,以便区分哪些包原本是同一个包拆开来的。
标志(3位):第一位固定是0。第二位DF(Don't Fragment)为1时不切片,这样B收到MTU1500的包就不能分包,无法转发给C只能直接丢弃。第三位MF(More Fragments)为1时表示后面还有切片。
段偏移量(13位)用于分包后合并时确定依次顺序。
6.TTL(8位):
TTL本是想用做统计时间的,后来变为跳数,最大255,一般为64,每过一个路由器减1,到达目的IP前如果减到0,路由器就将该包丢弃,再通过ICMP回传time exceeded信息,这样可以避免无限环路。
7.协议号(8位):
用于区分上层(传输层)数据。例如ICMP是1,TCP是6,UDP是17,EIGRP是88,OSPF是89
8.首部校验和(16位):
校验一下除数据部分外的包头信息以防被篡改。因为TTL值每经过一个路由器都会减1发生变化,因此每经过一个路由器都要重新校验,这很讨厌,所以IPv6里就没有校验和了。
9.源地址(32位),目标地址(32位):
(顾名思义)
10.可选项:
有4个选项:松散源路由选择,严格源路由选择,记录路由,时间戳
松散/严格源路由选择:用于控制沿途路径。比如A->B1->C也可以A->B2->C,具体走哪条你可以将B1或B2的地址写到这里。区别是:严格里必须规定沿途每个路由器,而松散可以只给出沿途必须经过的一些“要点”
记录路由:记录沿途的IP地址
时间戳:没啥用,路由器转发时可以打个时间,但除非所有路由器的时间精确同步,否则没什么用
11.数据:
(顾名思义,里面包含了上一层传输层的TCP/UDP头部)
上面IP协议里,源地址和目标地址就是家喻户晓的IP地址。
IP地址格式是由网络号和主机号(D类E类除外)合并而成,用点分10进制表示,共32位。分为ABCDE 5类IP地址:

A类地址:
前8位为网络号(首位固定0,后7位是网络地址),后24位是主机号。
A类地址范围:1.0.0.0 ~127.255.255.255 掩码:255.0.0.0(掩码的作用是区分网络号和主机号)
网段中主机位全0的是该网段地址,主机位全1的是该网段的广播地址。因此平时可用于单播的A类IP地址范围:1.0.0.1 ~127.255.255.254
B类地址:
前16位为网络号(前2位固定10,后6位是网络地址),后16位是主机号。
B类地址范围:128.0.0.0 ~191.255.255.255 掩码:255.255.0.0
网段中主机位全0的是该网段地址,主机位全1的是该网段的广播地址。因此平时可用于单播的B类IP地址范围:128.0.0.1 ~191.255.255.254
C类地址:
前24位为网络号(前3位固定110,后5位是网络地址),后8位是主机号。
B类地址范围:192.0.0.0 ~223.255.255.255 掩码:255.255.255.0
网段中主机位全0的是该网段地址,主机位全1的是该网段的广播地址。因此平时可用于单播的B类IP地址范围:192.0.0.1 ~223.255.255.254
D类地址:
用于多播,已经没有网络号和主机号了,前4位固定1110,后28位用于多播地址
D类地址范围:224.0.0.0 ~ 239.255.255.255
E类地址:
用于科研。。。太高端一般接触不到。同样已经没有网络号和主机号了
D类地址范围:240.0.0.0~ 255.255.255.255
有一些用于特殊用途的IP地址:
0.0.0.0:未指定IP
127.0.0.1:本地loopback测试地址
255.255.255.255:本地广播地址
还有一些私有IP地址:
A类地址中:10.0.0.0~ 10.255.255.255(即10网段)
B类地址中:172.16.0.0~172.31.255.255(即172的后半网段)
C类地址中:192.168.0.0~192.168.255.255(即192.168网段)
私有IP地址无法在公网上被使用,但可以在本地被使用。可以用NAT将本地使用的私有IP地址转换成公有IP地址来访问公网,以达到节约IP地址的目的。如企业内部不必每台主机都配一个公网IP,大家尽可使用私有IP地址,并共用多个公网IP来上网。
平时常用ABC 3类IP地址,以A类IP地址为例,只有126个网络,但每个网络都有巨量的主机2^24=16777216。如果一个公司只需要100台主机,那分配给该公司一个A类IP网段的话,将造成大量的IP地址浪费。因此通常只分配一个C类地址,C类地址的主机号是8位,可供2^8-2=254台主机用(-2的原因上面说过了,主机号全0是该网段地址,全1是该网段广播地址),虽然够用,但该公司只需求100台主机,仍旧造成IP地址浪费。所以需要VLSM(可变长子网掩码)子网划分来更合理地分配IP地址。
VLSM子网划分的规则:
子网数= 2^子网位数(子网位数 = 掩码 - 主类网络号,例如某B类IP的掩码是27,则子网位数为27-16=11,因此子网数为2^11=2048)
主机数= 2^主机号-2(-2的原因上面说过了,主机位全0为网络地址,全1为广播地址)
块大小=2^八位组内主机号(例如192.168.10.0 掩码:255.255.255.192。C类IP主机号是第四个8位组,现在掩码是192=11000000,意思是问第四个8位组借了前2位作为网络号,因此第四个8位组内主机号是8-2=6位,块大小为2^6=64)。得出块大小后,用块大小数字累加就能得到网络号。
一个C类IP地址子网划分的例子:
例如192.168.10.0 掩码:255.255.255.192 (这种写法很麻烦,192=11000000,即第四个8位组前2位是网络号,总共网络号是26位,可简写为192.168.10.0/26)
子网数为2^2=4,主机数为2^6-2=62,块大小为2^6=64(每个8位组来计算,发生在第三个8位组)。4个子网分别为:
192.168.10.0/26 (单播IP范围:192.168.10.1 ~ 192.168.10.62)
192.168.10.64/26 (单播IP范围:192.168.10.65 ~ 192.168.10.126)
192.168.10.128/26 (单播IP范围:192.168.10.129 ~ 192.168.10.190)
192.168.10.192/26 (单播IP范围:192.168.10.193 ~ 192.168.10.254)
一个B类IP地址子网划分的例子:
172.16.0.0/18
子网数为2^2=4,主机数为2^14-2=16382,块大小为2^6=64(每个8位组来计算,发生在第三个8位组)。4个子网分别为:
172.16.0.0/18 (单播IP范围:172.16.0.1 ~ 172.16.63.254)
172.16.64.0/18 (单播IP范围:172.16.64.1 ~ 172.16.127.254)
172.16.128.0/18 (单播IP范围:172.16.128.1 ~ 172.16.191.254)
172.16.192.0/18 (单播IP范围:172.16.192.1 ~ 172.16.255.254)
一个B类IP地址子网划分的例子2:
172.16.0.0/27
子网数为2^11=2048,主机数为2^5-2=30,块大小为2^5=32(每个8位组来计算,发生在第四个8位组)。2048个子网分别为:
172.16.X.0/27
172.16.X.32/27
172.16.X.64/27
172.16.X.96/27
172.16.X.128/27
172.16.X.160/27
172.16.X.192/27
172.16.X.224/27 (第三位可以从0变化到255)
上面这样子网划分,比ABC主类地址能更合理分配IP。下面再介绍一种更能节省IP地址的子网划分方法:
例如172.16.0.0/16,要划分成2个200台主机,3个2台主机,3个24台主机,该怎么划分子网呢?遵从的原则是从大到小:
1.先算200台主机:2^n-2 >= 200,n为8,即主机号为8,网络号为24
172.16.0.0/24变化发生在第3个8位组,因为第3个8位组全是网络位,因此块大小为2^0=1,子网:
172.16.0.0/24 (可以任选2个供200台主机用,例如选前2个。供200台主机用)
172.16.1.0/24 (供200台主机用)
172.16.2.0/24 (未分配)
......
172.16.255.0/24
2.算24个主机:2^n-2 >= 24,n为5,即主机位为5,网络位为27
在172.16.2.0/24基础上划分子网:172.16.2.0/27变化发生在第4个8位组,块大小为2^5=32:
172.16.2.0/27 (可以任选3个供24台主机用,例如选择前3个。供24台主机用)
172.16.2.32/27 (供24台主机用)
172.16.2.64/27 (供24台主机用)
172.16.2.128/27 (未分配)
.....
172.16.2.224/27
3.最后算2个主机:2^n-2 >= 2,n为2,即主机位为2,网络位为30
在172.16.2.128/27基础上划分子网:172.16.2.0/30变化发生在第4个8位组,块大小为2^2=4:
172.16.2.128/30 (这3个供2台主机用)
172.16.2.132/30
172.16.2.136/30
通过上面若干VLSM的例子可用看出,VLSM是从右向左问主机号借用网络号,那CIDR就是网络号向左偏移,相当于主机数扩大了。更官方点说:
CIDR,就是忽略ABC类网络,自定义前缀相同的一条路由。
如192.168.12.0/24
192.168.13.0/24
192.168.14.0/24
192.168.15.0/24
都通过路由器E连接路由器F。如果设4条路由很麻烦,希望汇总一下。如果汇总成主类地址192.168.0.0/16太不精确了,可以汇总成192.168.12.0/22一条路由。
CIDR(发音为“cider”)
从网络位借位给主机,和vlsm正好相反,允许一组ip网络对其他的路由器看来好象为一个实体,只有 网络位 和 主机位 来区别不同的IP 不考虑 分类(A,B,C,D,E),ISP常用这样的方法给客户分配地址,ISP提供给客户1个块,类似192.168.10.32/28
无类域间路由(Classless Inter-Domain Routing,CIDR)在RFC 1517~RFC 1520中都有描述。提出CIDR的初衷是为了解决IP地址空间即将耗尽(特别是B类地址)的问题。CIDR并不使用传统的有类网络地址的概念,即不再区分A、B、C类网络地址。在分配IP地址段时也不再按照有类网络地址的类别进行分配,而是将IP网络地址空间看成是一个整体,并划分成连续的地址块。然后,采用分块的方法进行分配。
在CIDR技术中,常使用子网掩码中表示网络号二进制位的长度来区分一个网络地址块的大小,称为CIDR前缀。如IP地址210.31.233.1,子网掩码255.255.255.0可表示成210.31.233.1/24;IP地址166.133.67.98,子网掩码255.255.0.0可表示成166.133.67.98/16;IP地址192.168.0.1,子网掩码255.255.255.240可表示成192.168.0.1/28等。
CIDR可以用来做IP地址汇总(或称超网,Super netting)。在未作地址汇总之前,路由器需要对外声明所有的内部网络IP地址空间段。这将导致Internet核心路由器中的路由条目非常庞大(接近10万条)。采用CIDR地址汇总后,可以将连续的地址空间块总结成一条路由条目。路由器不再需要对外声明内部网络的所有IP地址空间段。这样,就大大减小了路由表中路由条目的数量。
例如,某公司申请到了1个网络地址块(共8个C类网络地址):210.31.224.0/24-210.31.231.0/24,为了对这8个C类网络地址块进行汇总,采用了新的子网掩码255.255.248.0,CIDR前缀为/21。如图2所示。
可以看出,CIDR实际上是借用部分网络号充当主机号的方法。在图2中,因为8个C类地址网络号的前21位完全相同,变化的只是最后3位网络号。因此,可以将网络号的后3位看成是主机号,选择新的子网掩码为255.255.248.0 (1111,1000),将这8个C类网络地址汇总成为210.31.224.0/21。
利用CIDR实现地址汇总有两个基本条件:
待汇总地址的网络号拥有相同的高位。如图2-2-8中8个待汇总的网络地址的第3个位域的前5位完全相等,均为11100。待汇总的网络地址数目必须是2n,如2个、4个、8个、16个等等。否则,可能会导致路由黑洞(汇总后的网络可能包含实际中并不存在的子网)。
CIDR作用用于帮助减缓IP地址耗尽和路由表增大问题的一项技术。CIDR的理念是多个C类地址块可以被组合或聚合在一起以生成更大的无类别IP地址集。这些多个C类地址可以在路由表中被归纳,从而减少了路由通告。
CIDR举例从192.168.8.0/24到192.168.15.0/24的C类网络地址被使用,并且被通告到ISP的路由器。当ISP路由器向外界通告路由时,它能够将这些C类网络的路由归纳为一条路由而不必分别通告这8个C类网络。通过通告路由192.168.8.0/21,ISP路由器指明他能够到达与地址192.168.8.0的前21比特相同的所有目的地址。
一个简单的配置示例:

======================== End
IPv4协议及VLSM可变长子网划分和CIDR无类域间路由的更多相关文章
- 第5章 子网划分和CIDR
第5章 子网划分和CIDR 划分网络 根据A类.B类或C类网络ID来识别网段具有一些局限性,主要是在网络级别之下不能对地址空间进行任何逻辑细分 如果一个IP是一个A类网络.数据报到达网关,然后传输到9 ...
- 子网划分与CIDR(斜杠加数字的表示与IP 的关系)(改进)
子网和CIDR 将常规的子网掩码转换为二进制,将发现子网掩格式为连续的二进制1跟连续0,其中子网掩码中为1的部份表示网络ID,子网掩中为0的表示主机ID.比如255.255.0.0转换为二进制为1 ...
- VLSM(可变长子网掩码)
http://blog.sina.com.cn/s/blog_635e1a9e0100yk51.html(转载) VLSM的介绍: VLSM(VLSM(Variable Length Subnetwo ...
- 可变长度子网掩码(VLSM)在子网划分中的应用
在学习可变长度子网掩码时,必须先熟练掌握二进制与十进制的转化.计算机中数据的单位(字节.位)等知识. 一.什么是可变长度子网掩码? 要理解可变长度子网掩码,先要理解子网掩码:要理解子网掩码,先要理解I ...
- HCNP学习笔记之子网划分 VLSM CIDR
子网划分.VLSM可变长子网掩码.CIDR无类域间路由是学习网络知识或者说是学习路由知识所必备的,但很多朋友说这三者理论性太强了,不好掌握.本文将结合实例讲解子网划分的方法并对VLSM和CIDR进行简 ...
- CCNA 之 三 TCP/IP 及 子网划分
TCP/IP TCP/IP 协议集或协议簇 概念: 传输控制协议/IRI特网协议(TCP/IP)组是由美国国防比(DoD)所创建的,主要用来确保数据的完整性及毁灭性战争中维持通信 是有一组不同功能的协 ...
- 第5章 IP地址和子网划分(3)_子网划分
6.子网划分 6.1 地址浪费 (1)IPv4公网地址资源日益紧张,为减少浪费,使IP地址能够充分利用,就要用到子网划分技术. (2)传统上一个C类地址,如212.2.3.0/24,其可用的地址范围为 ...
- 如何对IP地址进行子网划分?
在网络行业,子网划分是必须掌握的的基础知识点,下图是IP地址分类: 子网划分主要掌握的是划分思路,接下来我以192.168.1.72/27的IP划分做为例子: CIDR:无类域间路由. 可以看出192 ...
- 可变长子网掩码 VLSM
2014-05-05 17:26:08 标签:IP地址 路由器 技术部 路由表 长子 VLSM的介绍: VLSM(VLSM(Variable Length Subnetwork Mask,可变长子网掩 ...
随机推荐
- 网络基础知识-bps、Bps、pps的区别
在计算机科学中,bit是表示信息的最小单位,叫做二进制位:一般用0和1表示.Byte叫做字节,由8个位(8bit)组成一个字节(1Byte),用于表示计算机中的一个字符.bit(比特)与Byte(字节 ...
- .net mvc 使用ueditor的开发(官网没有net版本?)
1.ueditor的下载导入 官网下载地址:https://ueditor.baidu.com/website/download.html · 介绍 有两种,一种开发版,一种Mini版,分别长这样: ...
- i3wm随笔 1
快捷键 mod+0 退出 mod+v 垂直分割 mod+h 水平风格
- 【洛谷】题解 P1056 【排座椅】
题目链接 因为题目说输入保证会交头接耳的同学前后相邻或者左右相邻,所以一对同学要分开有且只有一条唯一的通道才能把他们分开. 于是可以吧这条通道累加到一个数组里面.应为题目要求纵列的通道和横列的通道条数 ...
- Python函数标注
Python函数标注 是关于用户自定义函数中使用的类型的完全可选元数据信息. 函数标注 以Python字典的形式存放在函数的 __annotations__ 属性中,并且不会影响函数的任何其他部分. ...
- application/x-www-urlencoded与multipart/form-data
学习ajax时,学到了GET与POST两种HTTP方法,于是去W3C看了二者的区别,里面提到了二者的编码类型不同,就在网上查阅了相关资料, 在这里把我查阅到的相关结果记录在此,方便以后学习,详细了解一 ...
- linux源码学习-for_each_cpu
刚开始读linux源码,第一眼就看到了这个很有意思的函数族,周末好好研究一下 3.13 这个组都是宏定义for循环,分析的时候注意到cpumask_next(),它在一个文件中定义了两次,还不是重载, ...
- JavaScript/Jquery:Validform 验证表单的相关属性解释
当我们写提交表单的时候往往需要验证表单是否填写了内容,是否正确,这个插件可以很方便的完成我们需要的验证! 使用方法: 1.先引用js <script type="text/javasc ...
- 微信小程序---scroll-view在苹果手机上触底或触顶页面闪动问题
在项目开发中遇到一个关于scroll-view的的问题,具体如下: 项目要求是横向滚动,由于直接在scroll-view组件设置display:flex不生效,因此考虑直接在scroll-view下增 ...
- php中注释有关内容
//单行注释 /*多行注释*/ /** 文档注释 (注意 文档注释与前面的那个多行注释不同)文档注释可以和特定的程序元素相关联 例如 类 函数 常量 变量方法 问了将文档注释与元素相关联 只需要在元素 ...