python答题辅助
最近直播答题app很热门,由于之前看过跳一跳的python脚本(非常棒),于是也想写一个答题的脚本。
https://github.com/huanmsf/cai
思路:
1、截图
2、文字识别,提取问题和选项(分割后识别准确性会提高)
3、爬取网页数据,根据规则匹配选项
4、根据选项自动点击屏幕该位置(应该循环点击,防止刚好切换到西瓜妹)
5、重复前面步骤
存在的问题:
1、答题时间有限,如果爬去的链接多了,还没解析完时间就到了。爬取的少就缺少分析数据,结果不靠谱。
2、问题和选项需要提取关键字匹配
3、可能要试试其他搜索引擎(百度垃圾信息严重影响正确率)
目录:
├── baidu.py
├── cai.png
├── main.py
├── need
│ └── chi_sim.traineddata
├── README
└── screenshot.py
main.py:
from screenshot import pull_screenshot
import time, urllib.request, baidu, os try:
import Image
except ImportError:
from PIL import Image, ImageDraw import pytesseract # 屏幕顶端到问题的距离/屏幕高度,随分辨率变化(默认1920*1080)
top_off_c = 0.15
# 问题高度
que_h = 300
# 答案高度
ans_h = 170 # 左右偏移量
l_r_off = 40 # 问题过滤器
que_filter = ['.', ' '] # 答案过滤器
ans_filter = ["《", "》", ' '] # 问题列表
que_list = [] # 选项坐标
point_A = (0, 0, 0, 0)
point_B = (0, 0, 0, 0)
point_C = (0, 0, 0, 0) # 辅助找到文字区域
def draw():
img = Image.open('cai.png')
w, h = img.size
draw = ImageDraw.Draw(img)
draw.line((40, h * 0.15, w - 40, h * 0.15), fill="red")
draw.line((40, h * 0.15 + 300, w - 40, h * 0.15 + 300), fill="red") draw.line((40, h * 0.15 + 470, w * 0.7, h * 0.15 + 470), fill="red")
draw.line((40, h * 0.15 + 640, w * 0.7, h * 0.15 + 640), fill="red")
draw.line((40, h * 0.15 + 810, w * 0.7, h * 0.15 + 810), fill="red") img.show() def click(point):
# img = Image.open('cai.png')
# w, h = img.size
# draw = ImageDraw.Draw(img)
# draw.arc(point, 0, 360, fill="red")
# img.show()
cmd = 'adb shell input swipe {x1} {y1} {x2} {y2} {duration}'.format(
x1=point[0],
y1=point[1],
x2=point[2],
y2=point[3],
duration=1
)
os.system(cmd) def main():
while True: print(">>>>>>")
pull_screenshot()
img = Image.open('cai.png')
img = img.convert('L')
w, h = img.size
img_q = img.crop((l_r_off, h * top_off_c, w - l_r_off, h * top_off_c + que_h))
img_a = img.crop((l_r_off, h * top_off_c + que_h, w * 0.7, h * top_off_c + que_h + ans_h))
img_b = img.crop((l_r_off, h * top_off_c + que_h + ans_h, w * 0.7, h * top_off_c + que_h + ans_h * 2))
img_c = img.crop((l_r_off, h * top_off_c + que_h + ans_h * 2, w * 0.7, h * top_off_c + que_h + ans_h * 3)) point_A = (w / 3 - 20, h * top_off_c + que_h + ans_h / 2 - 20, w / 3, h * top_off_c + que_h + ans_h / 2)
point_B = (w / 3 - 20, h * top_off_c + que_h + ans_h / 2 * 3 - 20, w / 3, h * top_off_c + que_h + ans_h / 2 * 3)
point_C = (w / 3 - 20, h * top_off_c + que_h + ans_h / 2 * 5 - 20, w / 3, h * top_off_c + que_h + ans_h / 2 * 5) # need 下的chi文件 复制到/usr/share/tesseract-ocr/4.00/
question = pytesseract.image_to_string(img_q, lang='chi_sim')
ans_a = pytesseract.image_to_string(img_a, lang='chi_sim')
ans_b = pytesseract.image_to_string(img_b, lang='chi_sim')
ans_c = pytesseract.image_to_string(img_c, lang='chi_sim')
ans = ["1", "1", "1"]
for f in que_filter:
question = question.strip().replace(f, "") for f in ans_filter:
ans_a = ans_a.strip().replace(f, "")
ans_b = ans_b.strip().replace(f, "")
ans_c = ans_c.strip().replace(f, "") ans[0] = ans_a
ans[1] = ans_b
ans[2] = ans_c for a in ans:
if not a.strip():
ind = ans.index(a)
ans[ind] = "&*&" print(question)
print(ans) if que_list.__contains__(question):
continue index = baidu.search(question, ans)
# 选第1,2,3个
if index == 0:
click(point_A)
elif index == 1:
click(point_B)
else:
click(point_C) print("index" + str(index))
que_list.append(question) if __name__ == '__main__':
main()
baidu.py:
# -*- coding:utf-8 -*- import urllib, time, re import lxml.etree as etree # 答案积分规则
"""
某个答案首次出现在一篇文章中+10,再次+3
""" def search(question, ans):
cont = {}
q_url = "http://www.baidu.com/s?word=" + urllib.parse.quote(question)
top_page = getdata(q_url)
selector = etree.HTML(top_page)
url_list = selector.xpath('//h3[@class]/a[@data-click]/@href')[0:5]
for url_item in url_list:
if not url_item.startswith('http'):
continue
print(url_item)
sub_page = getdata(url_item)
selector = etree.HTML(sub_page)
try:
content_list = selector.xpath('//div/text()|//span/text()|//p/text()')
except:
return 0
ans_tmp_list = []
for con in content_list:
if con.strip():
for a in ans:
if a in con:
if ans_tmp_list.__contains__(a):
if a in cont.keys():
cont[a] += 3
else:
cont[a] = 3
else:
if a in cont.keys():
cont[a] += 10
else:
cont[a] = 10
ans_tmp_list.append(a) print(con) print(cont)
if not cont:
return 0
else:
l = sorted(cont.items(), key=lambda x: x[1], reverse=True)
return ans.index(l[0][0]) def getdata(url):
req = urllib.request.Request(url)
try:
response = urllib.request.urlopen(req)
except:
return " "
top_page = ""
try:
top_page = response.read().decode("utf-8", 'ignore')
except:
pass
# print(top_page)
return top_page
screenshot.py:
# -*- coding: utf-8 -*-
"""
手机屏幕截图的代码(参考跳一跳外挂源码)
"""
import subprocess
import os
import sys
from PIL import Image SCREENSHOT_WAY = 3 def pull_screenshot():
global SCREENSHOT_WAY
if 1 <= SCREENSHOT_WAY <= 3:
process = subprocess.Popen(
'adb shell screencap -p',
shell=True, stdout=subprocess.PIPE)
binary_screenshot = process.stdout.read()
if SCREENSHOT_WAY == 2:
binary_screenshot = binary_screenshot.replace(b'\r\n', b'\n')
elif SCREENSHOT_WAY == 1:
binary_screenshot = binary_screenshot.replace(b'\r\r\n', b'\n')
f = open('cai.png', 'wb')
f.write(binary_screenshot)
f.close()
elif SCREENSHOT_WAY == 0:
os.system('adb shell screencap -p /sdcard/cai.png')
os.system('adb pull /sdcard/cai.png .')
文字识别
sudo pip3 install pytesseract
sudo apt-get install tesseract-ocr
初级版本效果:
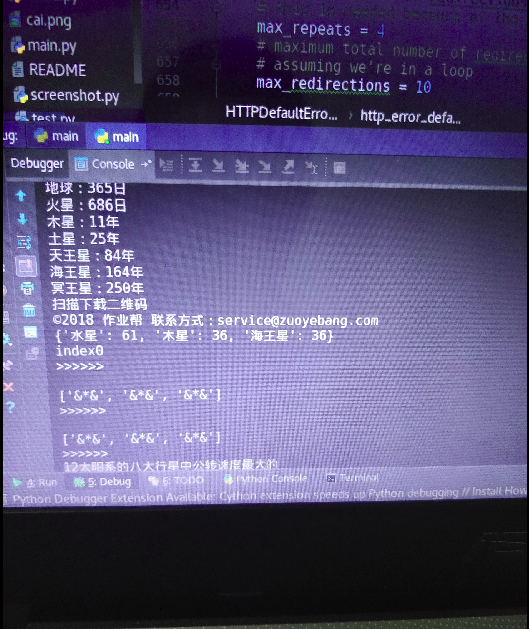
题外话:
最近在浏览FB站看到
文中提到可以提前10秒得到题目(不知是否属实),由于访问权限不能看,如有知道怎么搞的请留言交流下,谢谢
python答题辅助的更多相关文章
- OJ python答题结果"返回非零"
最近在OJ上用python答题,偶尔会遇到结果“放回非零”的情况(Non-zero Exit Code) 总结了以下,目前知道的是这些: 1. 在python2中用了input(),或在python3 ...
- Ocr答题辅助神器 OcrAnswerer4.x,通过百度OCR识别手机文字,支持屏幕窗口截图和ADB安卓截图,支持四十个直播App,可保存题库
http://www.cnblogs.com/Charltsing/p/OcrAnswerer.html 联系qq:564955427 最新版为v4.1版,开放一定概率的八窗口体验功能,请截图体验(多 ...
- python辅助开发模块(非官方)如pil,mysqldb,openpyxl,xlrd,xlwd
官方文档 只是支持win32, 不支持win64 所以很麻烦 民间高人,集中做了一堆辅助库,下载后,用python安装目录下的scripts中,pip和easy_install就可以安装了 pytho ...
- 第一章 Python 基础
1. 为什么学习 Python? 答题路线:a.python的优点,b.python的应用领域广 具体: 优点 1.python语法非常优雅,简单易学 2.免费开源 3.跨平台,可以自由移植 4.可扩 ...
- python leetcode 1
开始刷 leetcode, 简单笔记下自己的答案, 目标十一结束之前搞定所有题目. 提高一个要求, 所有的答案执行效率必须要超过 90% 的 python 答题者. 1. Two Sum. class ...
- Python垃圾回收机制
引用计数Python默认的垃圾收集机制是“引用计数”,每个对象维护了一个ob_ref字段.它的优点是机制简单,当新的引用指向该对象时,引用计数 引用计数 Python默认的垃圾收集机制是“引用计数”, ...
- 史上最全最强Charles截取手机https协议数据包教程(附上利用此技术制作最近微信比较火的头脑王者辅助外挂)!
纯原创,思路也是本人花了半个小时整理出来的,整个完成花费了本人半天时间,由于不才刚大学毕业,所以有的编码方面可能不入大牛们的眼,敬请原谅!如有转载请附上本地址,谢谢! 最近微信朋友圈刚刚被跳一跳血洗, ...
- Python的垃圾回收机制(引用计数+标记清除+分代回收)
一.写在前面: 我们都知道Python一种面向对象的脚本语言,对象是Python中非常重要的一个概念.在Python中数字是对象,字符串是对象,任何事物都是对象,而它们的核心就是一个结构体--PyOb ...
- python之MRO和垃圾回收机制
一.MOR 1.C3算法简介 为了解决原来基于深度优先搜索算法不满足本地优先级,和单调性的问题. python2.3版本之后不管是新式类还是经典类,查找继承顺序都采用C3算法 2.算法原理 C3算法的 ...
随机推荐
- node.js(基础四)_express基础
一.前言 本次内容主要包括: 1.express的基本用法 2.express中的静 ...
- linux c 编程 ------ 通过设备节点调用驱动
驱动程序如下,加载驱动后,会在/dev文件夹下生成一个文件hello_device_node,是此驱动的设备节点 #include <linux/init.h> #include < ...
- python自动化开发-[第七天]-面向对象
今日概要: 1.继承 2.封装 3.多态与多态性 4.反射 5.绑定方法和非绑定方法 一.新式类和经典类的区别 大前提: 1.只有在python2中才分新式类和经典类,python3中统一都是新式类 ...
- angular 中如果表单有相同的name一般会出现如下错误
Unhandled Promise rejection Cannot assign to a reference or variable
- Spring容器初始话原理图
l 主流程入口: ApplicationContext context = new ClassPathXmlApplicationContext(“spring.xml”) l ClassPathXm ...
- Event Recommendation Engine Challenge分步解析第七步
一.请知晓 本文是基于: Event Recommendation Engine Challenge分步解析第一步 Event Recommendation Engine Challenge分步解析第 ...
- java io系列04之 管道(PipedOutputStream和PipedInputStream)的简介,源码分析和示例
本章,我们对java 管道进行学习. 转载请注明出处:http://www.cnblogs.com/skywang12345/p/io_04.html java 管道介绍 在java中,PipedOu ...
- [leetcode-117]填充每个节点的下一个右侧节点指针 II
(1 AC) 填充每个节点的下一个右侧节点指针 I是完美二叉树.这个是任意二叉树 给定一个二叉树 struct Node { int val; Node *left; Node *right; Nod ...
- 2016vijos 1-3 兔子的晚会(生成函数+倍增FWT)
求出序列的生成函数后,倍增FWT #include<cstdio> using namespace std; #define N 2048 ; int inv; ]; int Pow(in ...
- HTML第二耍 列表标签
先复习下上一节 <!doctype html> <html> <head> <meta charset="utf-8"> <t ...