Java集合类根接口:Collection 和 Map
前言
在前文中我们了解了几种常见的数据结构,这些数据结构有着各自的应用场景,并且被广泛的应用于编程语言中,其中,Java中的集合类就是基于这些数据结构为基础。
Java的集合类是一些非常实用的工具类,主要用于存储和装载数据 (包括对象),因此,Java的集合类也被成为容器。在Java中,所有的集合类都位于java.util包下,这些集合类主要是基于两个根接口派生而来,它们就是 Collection和 Map。
Collection接口
Collection派生出三个子接口,Set代表不可重复的无序集合、List代表可重复的有序集合、Queue是java提供的队列实现,通过它们不断的扩展出很多的集合类,例如HashMap、ArrayList、LinkedList、Deque等,其分布图如下:
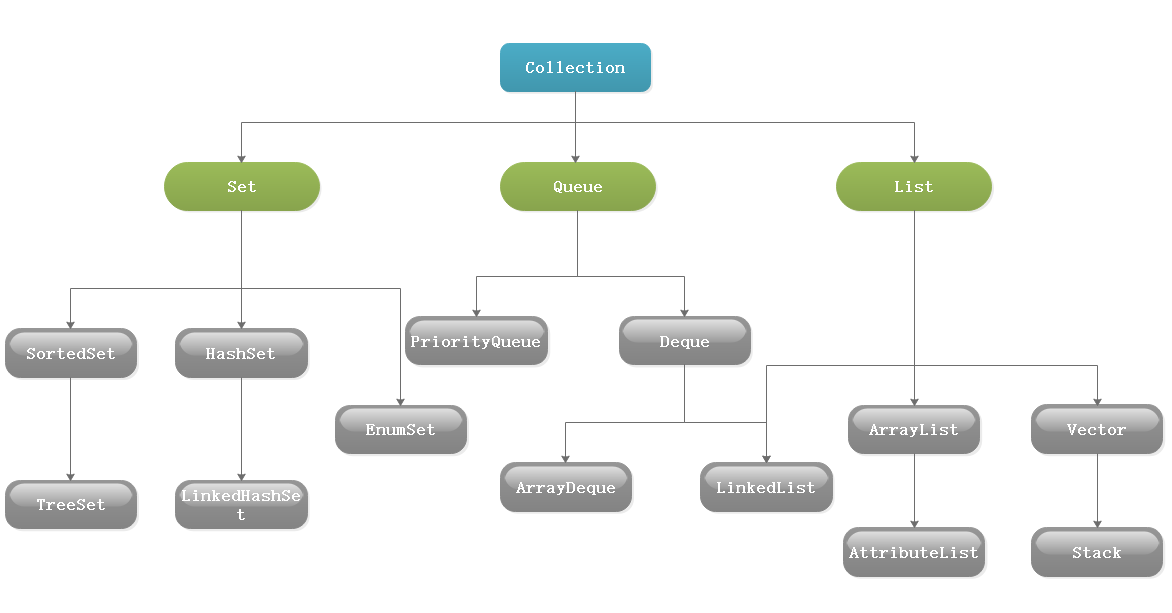
作为最基本的两个根接口之一,Collection提供了很多的基础方法,供它的子类调用。下面是Collection接口的源码:
public interface Collection<E> extends Iterable<E> {
int size();
boolean isEmpty();
boolean contains(Object var1);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] var1);
boolean add(E var1);
boolean remove(Object var1);
boolean containsAll(Collection<?> var1);
boolean addAll(Collection<? extends E> var1);
boolean removeAll(Collection<?> var1);
default boolean removeIf(Predicate<? super E> var1) {
Objects.requireNonNull(var1);
boolean var2 = false;
Iterator var3 = this.iterator();
while(var3.hasNext()) {
if (var1.test(var3.next())) {
var3.remove();
var2 = true;
}
}
return var2;
}
boolean retainAll(Collection<?> var1);
void clear();
boolean equals(Object var1);
int hashCode();
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}
default Stream<E> stream() {
return StreamSupport.stream(this.spliterator(), false);
}
default Stream<E> parallelStream() {
return StreamSupport.stream(this.spliterator(), true);
}
}
从源码可以看出,里面有很多方法是针对集合的基础操作,例如添加,删除,查询。例如:
int size()获取元素个数boolean isEmpty()是否个数为 0boolean contains(Object element)是否包含指定元素boolean add(E element)添加元素,成功时返回 trueboolean remove(Object element)删除元素,成功时返回 trueIterator<E> iterator()获取迭代器
还有一些操作整个集合的方法:
boolean containsAll(Collection<?> c)
是否包含指定集合 c 的全部元素
boolean addAll(Collection<? extends E> c)
添加集合 c 中所有的元素到本集合中,如果集合有改变就返回 true
boolean removeAll(Collection<?> c)
删除本集合中和 c 集合中一致的元素,如果集合有改变就返回 true
boolean retainAll(Collection<?> c)
保留本集合中 c 集合中两者共有的,如果集合有改变就返回 true
void clear()
删除所有元素
值得说明的是,在jdk1.8之后,Collection 接口还提供了从集合获取连续的或者并行流的方法:
Stream<E> stream() 在这个集合上返回一个顺序流 ,单线程
Stream<E> parallelStream() 在这个集合上返回一个并行的代码流 ,多线程
Stream相当于高级版本的iterator,可以对集合做比较,分类,甚至是过滤等操作,一般是结合lambda表达式来使用,这样会使代码变得更加简洁 (有人说会更难理解,这个仁者见仁) ,下面举几个简单的例子:
1、使用顺序流来过滤掉集合中为 “aaa” 的元素并做输出:
List<String> list = Arrays.asList("aaa", "bbb", "ccc");
list.stream().filter(e -> !e.contains("aaa"))
.forEach(e -> System.out.println(e));
2、使用并行流来操作集合:
List<String> list = Arrays.asList("aaa", "bbb", "ccc");
list.parallelStream().filter(e -> !e.contains("aaa"))
.forEach(e -> System.out.println(e));
当使用顺序流去遍历时,每个item读完后再读下一个item。
而使用并行流去遍历时,集合会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出,所以理论上,并行流的效率至少是顺序流的两倍以上。
Map接口
Map接口是和Collection同等级的根接口,它表示一个键值对(key-value)的映射,每一个key对应一个value,查找Map中的数据,总是根据key来获取,所以key是不可重复的,它用于标识集合里的每项数据。跟Collection一样,Map接口派生了很多的集合子类,这是Map的体系架构图:

Map接口提供了很多集合的初识方法,其底层结构是封装一个名为entry的接口,源码如下:
public interface Entry<K, V> {
K getKey();
V getValue();
V setValue(V var1);
boolean equals(Object var1);
int hashCode();
static <K extends Comparable<? super K>, V> Comparator<Map.Entry<K, V>> comparingByKey() {
return (Comparator)((Serializable)((var0x, var1x) -> {
return ((Comparable)var0x.getKey()).compareTo(var1x.getKey());
}));
}
static <K, V extends Comparable<? super V>> Comparator<Map.Entry<K, V>> comparingByValue() {
return (Comparator)((Serializable)((var0x, var1x) -> {
return ((Comparable)var0x.getValue()).compareTo(var1x.getValue());
}));
}
static <K, V> Comparator<Map.Entry<K, V>> comparingByKey(Comparator<? super K> var0) {
Objects.requireNonNull(var0);
return (Comparator)((Serializable)((var1x, var2x) -> {
return var0.compare(var1x.getKey(), var2x.getKey());
}));
}
static <K, V> Comparator<Map.Entry<K, V>> comparingByValue(Comparator<? super V> var0) {
Objects.requireNonNull(var0);
return (Comparator)((Serializable)((var1x, var2x) -> {
return var0.compare(var1x.getValue(), var2x.getValue());
}));
}
}
从源码中可以看出,entry中封装了一系列设值和比较器,这也是Map实现类的元素操作的基础接口,一个entry就相当于一个封装了键值对的元素,是Map接口里的架构核心。
除此之外,Map中还提供了两个集合来操作自身,这就是 KeySet 和 Values。
Set<K> keySet();
Collection<V> values();
KeySet 是一个 Map 中 key 的集合,以 Set 的形式保存,不允许重复,因此键存储的对象需要重写 equals() 和 hashCode() 方法。
Values 是一个 Map 中 value 的集合,以 Collection 的形式保存,可以重复。
通过这三种视图,Map可以对自身结构以及内部元素做操作,在集合中非常常用,建议读者们可以多看看源码,作深入的了解。
Java集合类根接口:Collection 和 Map的更多相关文章
- JAVA集合详解(Collection和Map接口)
原文地址http://blog.csdn.net/lioncode/article/details/8673391 在JAVA的util包中有两个所有集合的父接口Collection和Map,它们的父 ...
- Java集合排序及java集合类详解--(Collection, List, Set, Map)
1 集合框架 1.1 集合框架概述 1.1.1 容器简介 到目前为止,我们已经学习了如何创建多个不同的对象,定义了这些对象以后,我们就可以利用它们来做一 ...
- Java集合类——Set、List、Map、Queue接口
目录 Java 集合类的基本概念 Java 集合类的层次关系 Java 集合类的应用场景 一. Java集合类的基本概念 在编程中,常需要集中存放多个数据,数组是一个很好的选择,但数组的长度需提前指定 ...
- 单列集合类的根接口Collection
Collection接口 Collection是所有单列集合的父接口,因此在Collection中定义了单列集合(List和Set)通用的一些方法,这些方法可用于操作所有的单列集合.JDK 不提供此接 ...
- 【转载】Java集合类Array、List、Map区别和联系
Java集合类主要分为以下三类: 第一类:Array.Arrays第二类:Collection :List.Set第三类:Map :HashMap.HashTable 一.Array , Arrays ...
- Java集合类: Set、List、Map、Queue使用场景梳理
本文主要关注Java编程中涉及到的各种集合类,以及它们的使用场景 相关学习资料 http://files.cnblogs.com/LittleHann/java%E9%9B%86%E5%90%88%E ...
- Java集合类: Set、List、Map、Queue使用
目录 1. Java集合类基本概念 2. Java集合类架构层次关系 3. Java集合类的应用场景代码 1. Java集合类基本概念 在编程中,常常需要集中存放多个数据.从传统意义上讲,数组是我们的 ...
- 基础知识《六》---Java集合类: Set、List、Map、Queue使用场景梳理
本文转载自LittleHann 相关学习资料 http://files.cnblogs.com/LittleHann/java%E9%9B%86%E5%90%88%E6%8E%92%E5%BA%8F% ...
- java 集合类Array、List、Map区别和优缺点
Java集合类主要分为以下三类: 第一类:Array.Arrays 第二类:Collection :List.Set第三类:Map :HashMap.HashTable 一.Array , Array ...
随机推荐
- SQL Server 深入解析索引存储(堆)
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/索引体系结构/堆 概述 本篇文章是关于堆的存储结构.堆是不含聚集索引的表(所以只有非聚集索引的表也是堆).堆的 sys.parti ...
- My Feedback for Windows 10 IoT Core on Feedback Hub App (4/1/2017-1/23/2018)
- 【高速接口-RapidIO】2、RapidIO串行物理层的包与控制符号
一.RapidIO串行物理层背景介绍 上篇博文提到RapidIO的物理层支持串行物理层与并行物理层两种,由于Xilinx 部分FPGA内部已经集成了串行高速收发器,所以用FPGA实现RapidIO大多 ...
- 基于TensorFlow的深度学习系列教程 2——常量Constant
前面介绍过了Tensorflow的基本概念,比如如何使用tensorboard查看计算图.本篇则着重介绍和整理下Constant相关的内容. 基于TensorFlow的深度学习系列教程 1--Hell ...
- 为什么使用 Spring Boot?
Spring 是一个非常流行的基于Java语言的开发框架,此框架用来构建web和企业应用程序.与许多其他仅关注一个领域的框架不同,Spring框架提供了广泛的功能,通过其组合项目满足现代业务需求. S ...
- Javascript高级编程学习笔记(35)—— DOM(1)节点
DOM JS由三部分组成 1.BOM 2.DOM 3.ECMAScript ES和BOM在前面的文章已经介绍过了 今天开始JS组成的最后一部分DOM(文档对象模型) 我们知道,JS中的这三个部分实际上 ...
- 吴恩达机器学习笔记35-诊断偏差和方差(Diagnosing Bias vs. Variance)
当你运行一个学习算法时,如果这个算法的表现不理想,那么多半是出现两种情况:要么是偏差比较大,要么是方差比较大.换句话说,出现的情况要么是欠拟合,要么是过拟合问题.那么这两种情况,哪个和偏差有关,哪个和 ...
- 移动端调试神器-vConsole
什么是vConsole? 官方说明是一个web前端开发者面板,可用于展示console日志,方便日常开发,调试. 简单来说相当于移动版的Chrome调试控制台,就是我们在PC端常用的F12 vCo ...
- Linux rpm包安装不了
有时候会发现安装rpm包时会报错,解决办法: 到rpm包所在目录执行 createrepo -v ./ 这个命令 然后会生成一个repodate这个目录,然后在进行安装rpm就可以了!
- 【面试题】java中高以上必会技能
java基础 1.集合相关 1.1 java中常见的集合 答:Arraylist,LinkedList,ListedList,HashMap,HashSet. 1.2 arraylist和linked ...