走进JDK(十一)------LinkedHashMap
概述
LinkedHashMap 继承自 HashMap,在 HashMap 基础上,通过维护一条双向链表,解决了 HashMap 不能随时保持遍历顺序和插入顺序一致的问题。除此之外,LinkedHashMap 对访问顺序也提供了相关支持。
原理
LinkedHashMap在HashMap结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。
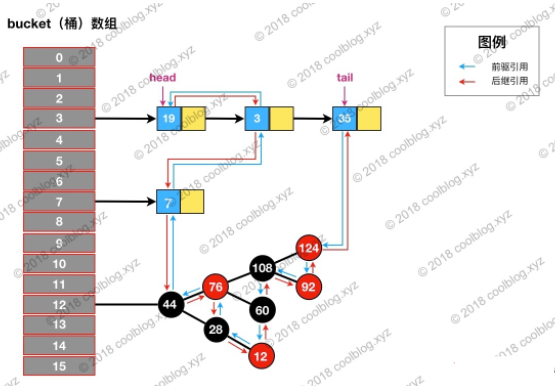
上图中,淡蓝色的箭头表示前驱引用,红色箭头表示后继引用。每当有新键值对节点插入,新节点最终会接在 tail 引用指向的节点后面。而 tail 引用则会移动到新的节点上,这样一个双向链表就建立起来了。
Entry
在对核心内容展开分析之前,这里先插队分析一下键值对节点的继承体系。先来看看继承体系结构图:
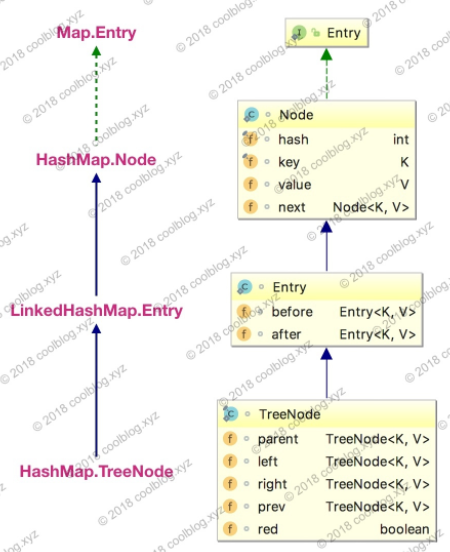
LinkedHashMap 内部类 Entry 继承自 HashMap 内部类 Node,并新增了两个引用,分别是 before 和 after。这两个引用的用途不难理解,也就是用于维护双向链表。同时,TreeNode 继承 LinkedHashMap 的内部类 Entry 后,就具备了和其他 Entry 一起组成链表的能力。
主要方法
1、put()------LinkedHashMap的put()与HashMap保持一致,区别在于newNode()。
// HashMap 中实现
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
} // HashMap 中实现
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0) {...}
// 通过节点 hash 定位节点所在的桶位置,并检测桶中是否包含节点引用
if ((p = tab[i = (n - 1) & hash]) == null) {...}
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode) {...}
else {
// 遍历链表,并统计链表长度
for (int binCount = 0; ; ++binCount) {
// 未在单链表中找到要插入的节点,将新节点接在单链表的后面
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) {...}
break;
}
// 插入的节点已经存在于单链表中
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null) {...}
afterNodeAccess(e); // 回调方法,后续说明
return oldValue;
}
}
++modCount;
if (++size > threshold) {...}
afterNodeInsertion(evict); // 回调方法,后续说明
return null;
} // HashMap 中实现
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
} // LinkedHashMap 中覆写
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
// 将 Entry 接在双向链表的尾部
linkNodeLast(p);
return p;
} // LinkedHashMap 中实现
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
// last 为 null,表明链表还未建立
if (last == null)
head = p;
else {
// 将新节点 p 接在链表尾部
p.before = last;
last.after = p;
}
}
2、remove()------LinkedHashMap的remove()与HashMap保持一致,区别在于afterNodeRemoval()。
// HashMap 中实现
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
} // HashMap 中实现
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode) {...}
else {
// 遍历单链表,寻找要删除的节点,并赋值给 node 变量
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode) {...}
// 将要删除的节点从单链表中移除
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node); // 调用删除回调方法进行后续操作
return node;
}
}
return null;
} // LinkedHashMap 中覆写
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 将 p 节点的前驱后后继引用置空
p.before = p.after = null;
// b 为 null,表明 p 是头节点
if (b == null)
head = a;
else
b.after = a;
// a 为 null,表明 p 是尾节点
if (a == null)
tail = b;
else
a.before = b;
}
简单描述下过程:
- 根据 hash 定位到桶位置
- 遍历链表或调用红黑树相关的删除方法
- 从 LinkedHashMap 维护的双链表中移除要删除的节点
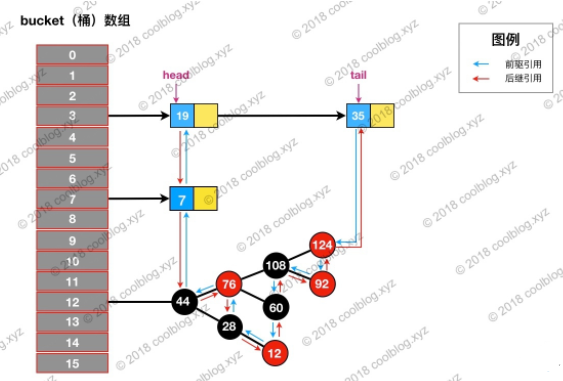
举个例子,假如我们要删除下图键值为 3 的节点。
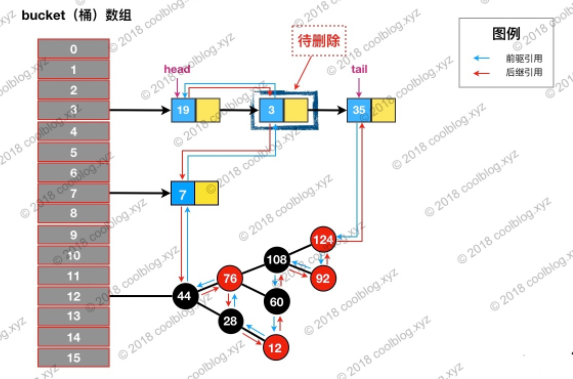
根据 hash 定位到该节点属于3号桶,然后在对3号桶保存的单链表进行遍历。找到要删除的节点后,先从单链表中移除该节点。如下:
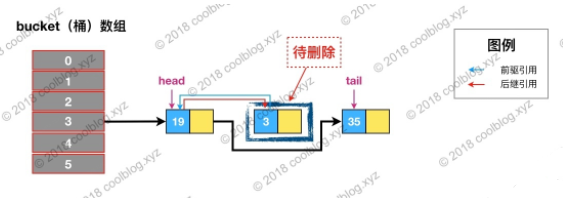
如果是HashMap,remove()的操作就结束了,但是LinkedHashMap还维护了一个双向链表,如下:
3、get()
// LinkedHashMap 中覆写
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
// 如果 accessOrder 为 true,则调用 afterNodeAccess 将被访问节点移动到链表最后
if (accessOrder)
afterNodeAccess(e);
return e.value;
} // LinkedHashMap 中覆写
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
// 如果 b 为 null,表明 p 为头节点
if (b == null)
head = a;
else
b.after = a; if (a != null)
a.before = b;
/*
* 这里存疑,父条件分支已经确保节点 e 不会是尾节点,
* 那么 e.after 必然不会为 null,不知道 else 分支有什么作用
*/
else
last = b; if (last == null)
head = p;
else {
// 将 p 接在链表的最后
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
举个例子,依然访问下图键值为3的节点,访问前结构为:
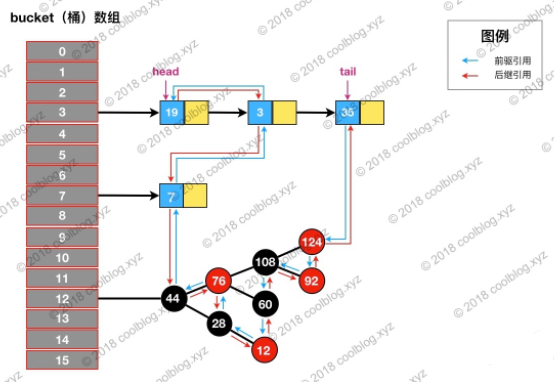
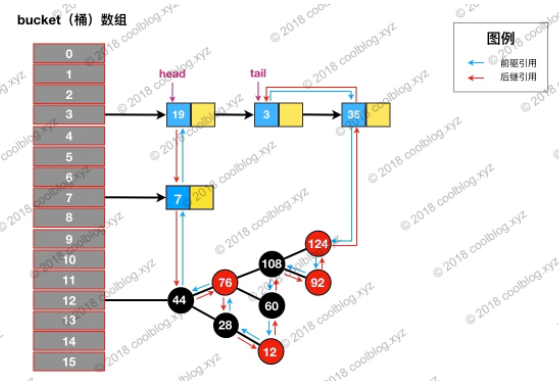
访问后,键值为3的节点将会被移动到双向链表的最后位置,其前驱和后继也会跟着更新。访问后的结构如下:
走进JDK(十一)------LinkedHashMap的更多相关文章
- 调试过程中发现按f5无法走进jdk源码
debug 模式 ,在fis=new FileInputStream(file); 行打断点 调试过程中发现按f5无法走进jdk源码 package com.lzl.spring.test; impo ...
- 走进JDK(十)------HashMap
有人说HashMap是jdk中最难的类,重要性不用多说了,敲过代码的应该都懂,那么一起啃下这个硬骨头吧!一.哈希表在了解HashMap之前,先看看啥是哈希表,首先回顾下数组以及链表数组:采用一段连续的 ...
- 走进JDK(八)------AbstractSet
说完了list,再说说colletion另外一个重要的子集set,set里不允许有重复数据,但是不是无序的.先看下set的整个架构吧: 一.类定义 public abstract class Abst ...
- 走进JDK(一)------Object
阅读JDK源码也是一件非常重要的事情,尤其是使用频率最高的一些类,通过源码可以清晰的清楚其内部机制. 如何阅读jdk源码(基于java8)? 首先找到本地电脑中的jdk安装路径,例如我的就是E:\jd ...
- 走进JDK(十二)------TreeMap
一.类定义 TreeMap的类结构: public class TreeMap<K,V> extends AbstractMap<K,V> implements Navigab ...
- 走进JDK(二)------String
本文基于java8. 基本概念: Jvm 内存中 String 的表示是采用 unicode 编码 UTF-8 是 Unicode 的实现方式之一 一.String定义 public final cl ...
- 走进JDK(九)------AbstractMap
map其实就是键值对,要想学习好map,得先从AbstractMap开始. 一.类定义.构造函数.成员变量 public abstract class AbstractMap<K,V> i ...
- 走进JDK(七)------LinkedList
要学习LinkedList,首先得了解链表结构.上篇介绍ArrayList的文章中介绍了底层是数组结构,查询快的问题,但是删除时,需要将删除位置后面的元素全部左移,因此效率比较低. 链表则是这种机制: ...
- 走进JDK(六)------ArrayList
对于广大java程序员来说,ArrayList的使用是非常广泛的,但是发现很多工作了好几年的程序员不知道底层是啥...这我觉得对于以后的发展是非常不利的,因为java中的每种数据结构的设计都是非常完善 ...
随机推荐
- 让anujs支持rc-select
git clone git@github.com:react-component/select.git cd select npm i babel-plugin-antd --save-dev npm ...
- [原创] debian 9.3 搭建Jira+Confluence+Bitbucket项目管理工具(二) -- 安装jira 7.5.4
[原创] debian 9.3 搭建Jira+Confluence+Bitbucket项目管理工具(二) -- 安装jira 7.5.4 环境都配置好以后, 开始搭建Jira的环境, 这里参考了一篇文 ...
- 开源虚拟化KVM(一)搭建部署与概述
一,KVM概述 1.1 虚拟化概述 在计算机技术中,虚拟化意味着创建设备或资源的虚拟版本,如服务器,存储设备,网络或者操作系统等等 [x] 虚拟化技术分类: 系统虚拟化(我们主要讨论的反向) 存储虚拟 ...
- SourInsight4 配置视野内引用高亮
- linux学习笔记:vim程序编辑器—vim的使用
注:以下是学习<鸟哥的linux私房菜>(第三版)的学习笔记,纯属个人学习记录. 2018-11-19 一.学习vim的原因 很多软件的编辑接口都会主动调用vi 二.vim的使用 (1)v ...
- Zabbix 各种报错信息和遇到的问题处理(持续总结更新~~~~~)
问题1:Zabbix poller processes more than 75% busy 解决: 1.修改配置文件: # vim /etc/zabbix/zabbix_server.conf St ...
- Spring常用注解总结(1)
前言:项目中常用的注解常看常记,总会对自己有些好处,所以在这里分享一下. 使用spring时,可以使用xml配置文件配置相关信息.但是我还是喜欢用注解的方式,因为可以充分利用反射机制获取类结构信息,而 ...
- python添加post请求
1.进入python的安装目录下的Scripts目录 ,利用pip install requests安装第三方模块 2.火狐浏览器自带firebug,打开http://10.148.111.111/q ...
- c#devexpress 窗体控件dock的重要
在设计c# devexpress winform 窗体时, 要建立起dock意识, dock就是子窗体如何靠在父窗体上, 有fill 全覆盖, buttom 底部,top 上部... 如下图 pane ...
- 杨其菊201771010134《面向对象程序设计(java)》第十四周学习总结
第十四周学习总结 第一部分:理论知识 理论知识:本周学习Swing用户界面 内容:Swing与模型-视图-控制器设计模式:布局管理概述:文本输入 :选择组件:菜单:复杂的布局管理:对话框: 第二部分: ...