爬虫_豆瓣电影top250 (正则表达式)
一样的套路,就是多线程还没弄
import requests
import re
import json headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36' def get_one_page(url):
try:
html = requests.get(url, headers={'User-Agent':'headers'})
if html.status_code == 200:
return html.text
return None except RequestsException:
return None def write_txt(content):
with open('result.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
f.close def parse_one_page(html):
# <em class="">(\d+)</em>
# .*?href="(.*?)/">.*?
# other">(\w+)</span
match = re.compile('.*?<em class="">(.*?)</em>.*?href="(.*?)/">.*?"title">(.*?)</span.*?other">(.*?)</span', re.S)
results = re.findall(match, html)
for item in results:
yield{
'range': item[0],
'movie_main_page': item[1],
'movie_title': item[2],
'other_name': item[3].strip()[13:]
}
# print(results) def main():
for start in range(0, 250, 25):
url = 'https://movie.douban.com/top250?start=' + str(start)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_txt(item) if __name__ == '__main__':
main()
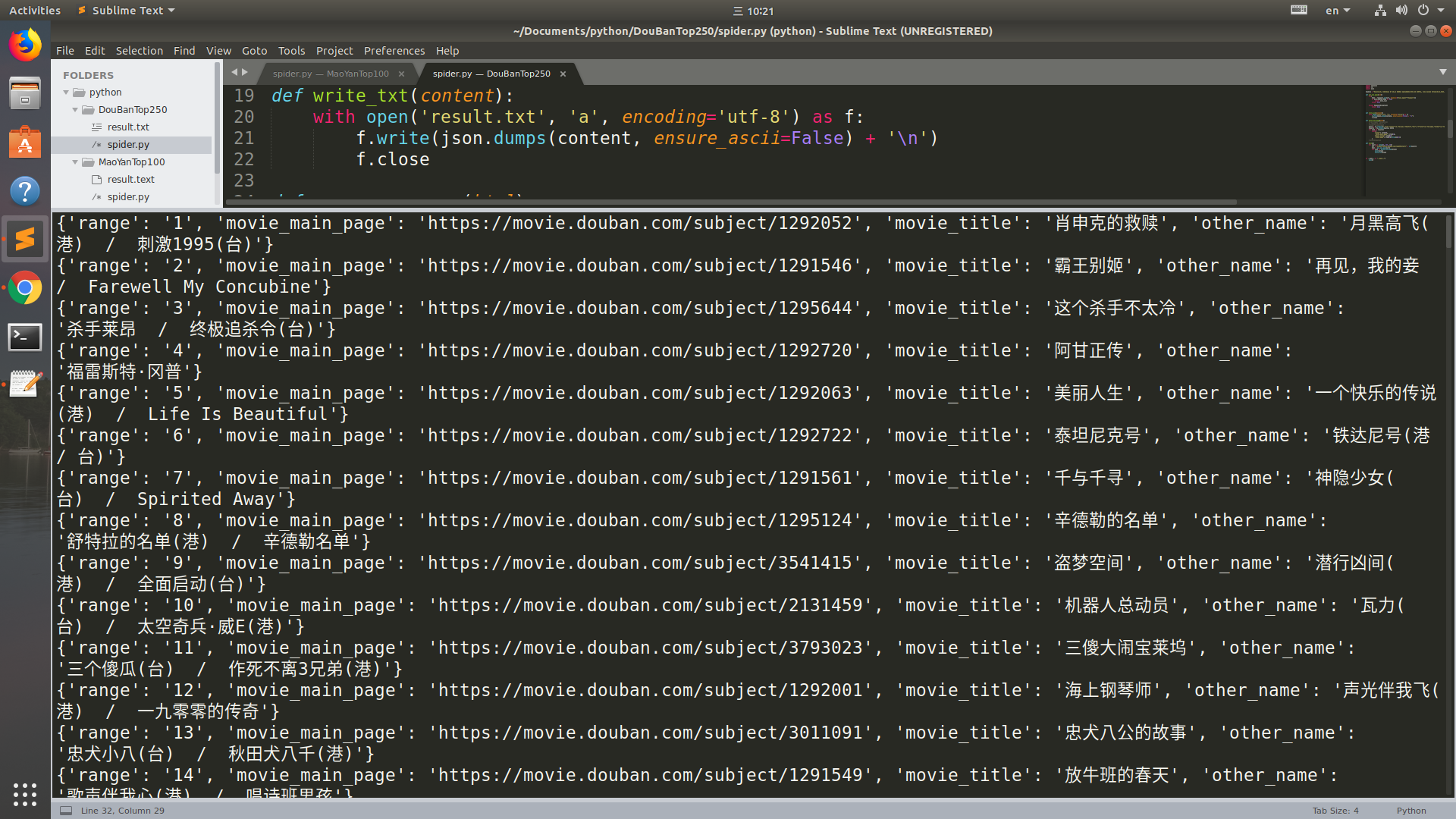
运行结果
爬虫_豆瓣电影top250 (正则表达式)的更多相关文章
- <爬虫实战>豆瓣电影TOP250(三种解析方法)
1.豆瓣电影排行.py # 目标:爬取豆瓣电影排行榜TOP250的电影信息 # 信息包括:电影名字,上映时间,主演,评分,导演,一句话评价 # 解析用学过的几种方法都实验一下①正则表达式.②Beaut ...
- 【Python爬虫】:使用高性能异步多进程爬虫获取豆瓣电影Top250
在本篇博文当中,将会教会大家如何使用高性能爬虫,快速爬取并解析页面当中的信息.一般情况下,如果我们请求网页的次数太多,每次都要发出一次请求,进行串行执行的话,那么请求将会占用我们大量的时间,这样得不偿 ...
- 第一个爬虫经历----豆瓣电影top250(经典案例)
因为要学习数据分析,需要从网上爬取数据,所以开始学习爬虫,使用python进行爬虫,有好几种模拟发送请求的方法,最基础的是使用urllib.request模块(python自带,无需再下载),第二是r ...
- Python 爬虫:豆瓣电影Top250,包括电影导演、类型、年份、主演
结果输出到文本文件中. import codecs import requests from bs4 import BeautifulSoup headers={'User-Agent': 'Mozi ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- 利用python2.7正则表达式进行豆瓣电影Top250的网络数据采集及MySQL数据库操作
转载请注明出处 利用python2.7正则表达式进行豆瓣电影Top250的网络数据采集 1.任务 采集豆瓣电影名称.链接.评分.导演.演员.年份.国家.评论人数.简评等信息 将以上数据存入MySQL数 ...
- 练习:一只豆瓣电影TOP250的爬虫
练习:一只豆瓣电影TOP250爬虫 练习:一只豆瓣电影TOP250爬虫 ①创建project ②编辑items.py import scrapyclass DoubanmovieItem(scrapy ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
随机推荐
- python中Metaclass的理解
今天在学习<python3爬虫开发实战>中看到这样一段代码3 class ProxyMetaclass(type): def __new__(cls, name, bases, attrs ...
- codeforces#1097 D. Makoto and a Blackboard(dp+期望)
题意:现在有一个数写在黑板上,它以等概率转化为它的一个约数,可以是1,问经过k次转化后这个数的期望值 题解:如果这个数是一个素数的n次方,那么显然可以用动态规划来求这个数的答案,否则的话,就对每个素因 ...
- 文本文档中各字母出现次数汇总(java)
package 字母频率统计; import java.io.*; public class Inputfile { public static void main(String args[]) { ...
- JavaScript动态修改html组件form的action属性
用javaScript动态修改html组件form的action属性,可以在提交时再决定处理表单的页面. <%--JavaScript部分--%><script language=& ...
- 结对项目3-功能增强型带基本函数计算java计算器
-----------------------------------------------------实验报告------------------------------------------- ...
- Python之加环境变量
1.python找文件是先去当前文件所在的文件夹下找,也就是bin目录下找 2.如果bin目录里找不到,再去python的环境变量里找 如果有pycharm,那么直接点右键-选择Mark Direct ...
- 【学习总结】Git学习-参考廖雪峰老师教程一-Git简介
学习总结之Git学习-总 目录: 一.Git简介 二.安装Git 三.创建版本库 四.时光机穿梭 五.远程仓库 六.分支管理 七.标签管理 八.使用GitHub 九.使用码云 十.自定义Git 期末总 ...
- js-cookie和session
###1.cookie 含义: 存储在访问者的计算机中的变量,即存储在客户端 创建一个cookie /* getCookie方法判断document.cookie对象中是否存有cookie,若有则判断 ...
- centOS7搭建NFS服务器
借鉴别人这篇博客搭建成功的:http://blog.51cto.com/mrxiong2017/2087001 NFS系统:用来共享文件.图片.视频 准备两个centOS7服务器,一个作NFS ser ...
- C# Note26: [MethodImpl(MethodImplOptions.Synchronized)]与lock机制
在进行.NET开发时,经常会遇见如何保持线程同步的情况.在众多的线程同步的可选方式中,加锁无疑是最为常用的.如果仅仅是基于方法级别的线程同步,使用System.Runtime.CompilerServ ...