Hadoop生态圈-Ambari控制台功能简介
Hadoop生态圈-Ambari控制台功能简介
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
在经历一系列安装过程之后(部署过HDP后我终于发现为什么大家喜欢用它了,部署比CDH简单是他优势之一!),我们已经新建了一个进群并进入到Ambari到集群控制台首页。Ambari到集群控制台主要分为3个区域,如下图所示:
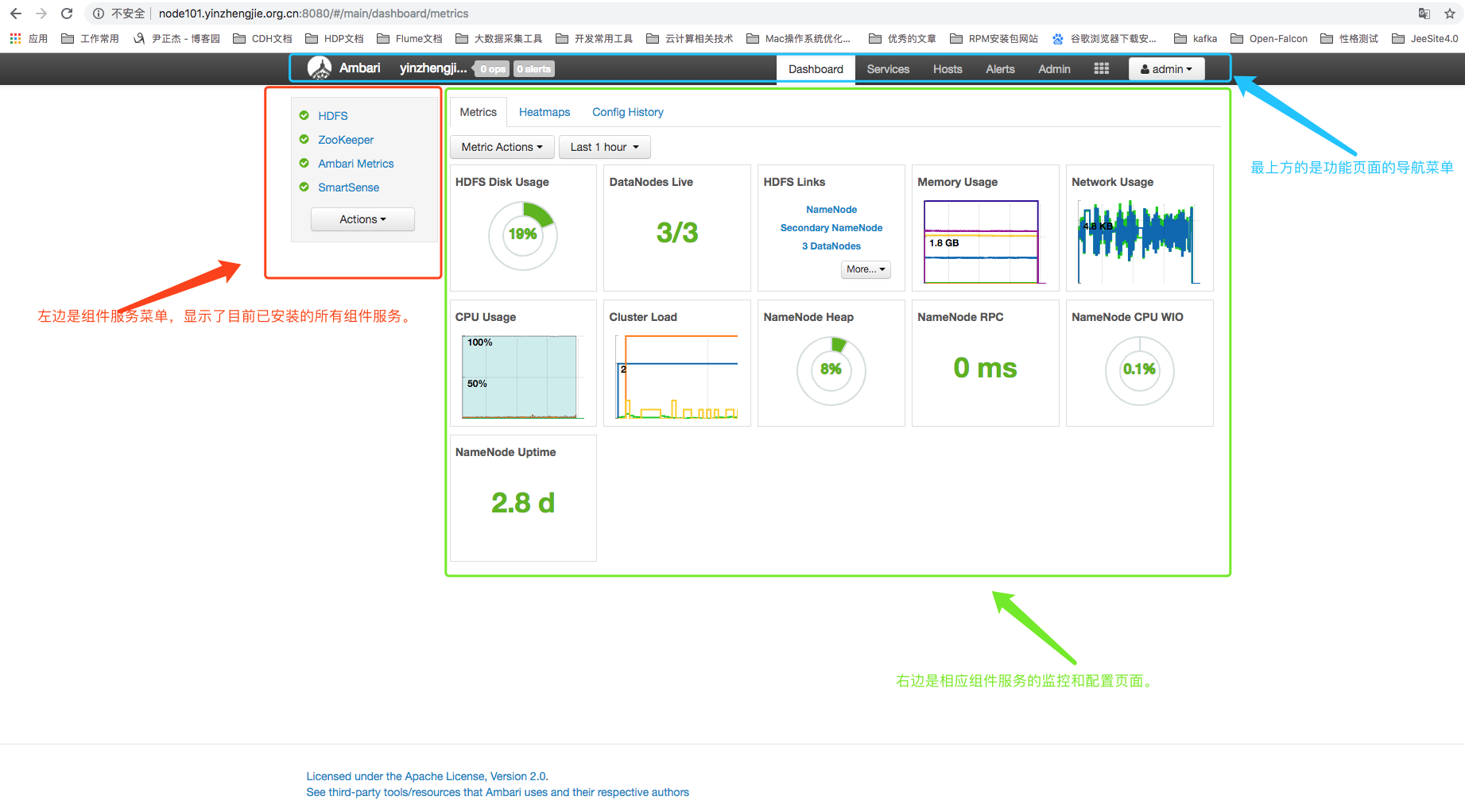
好啦,接下来我会简单介绍一下Ambari到核心功能。
一.集群管服务管理
Ambari 为Hadoop服务提供了一套强大的管理与维护的功能,包括集群用户,服务安装,服务监控等。
1>.集群用户
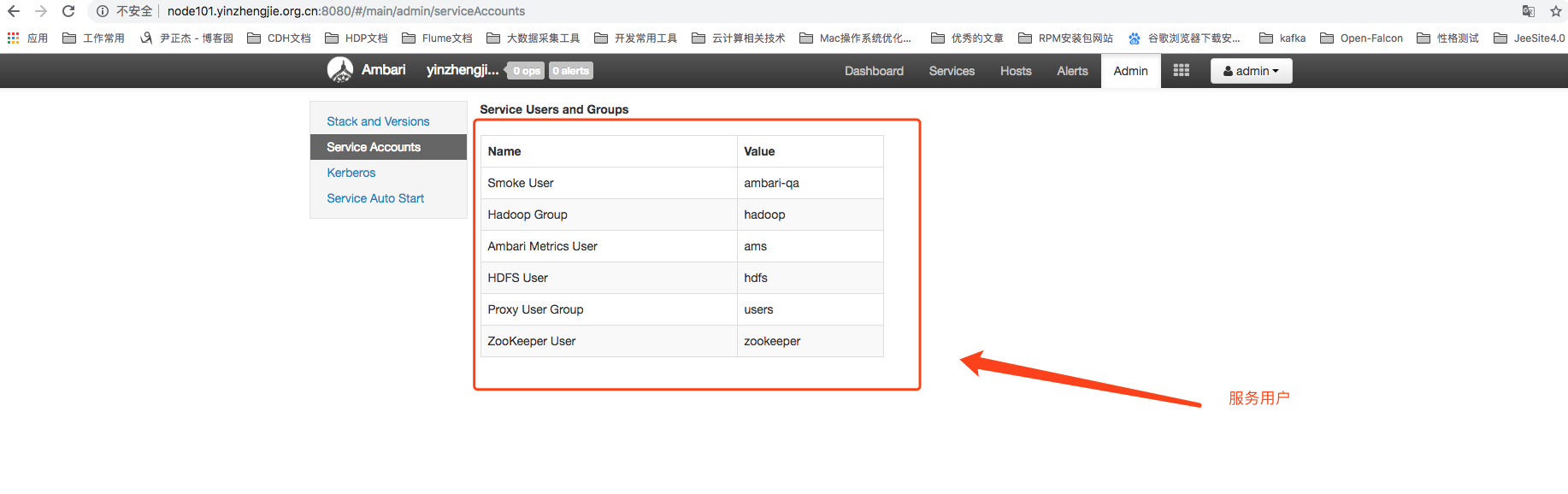
如下图所示,通过右上角Admin菜单进入集群用户页面,我们可以看到Ambari对于已经安装的Hadoop服务都预建了一套用户。这些用户有两层含义:
第一:Ambari系统内部的服务用户,这类用户是存储在Ambari自己的元数据数据库中的;
第二:通过Agent服务在目标主机上建立的linux用户,Hadoop在运行期间会使用这些Linux用户。
Ambari高度自动化的集群用户功能,不仅免去了通过原始手工维护集群用户时的种种烦恼,也为日后集成权限,认证系统提供了空间。
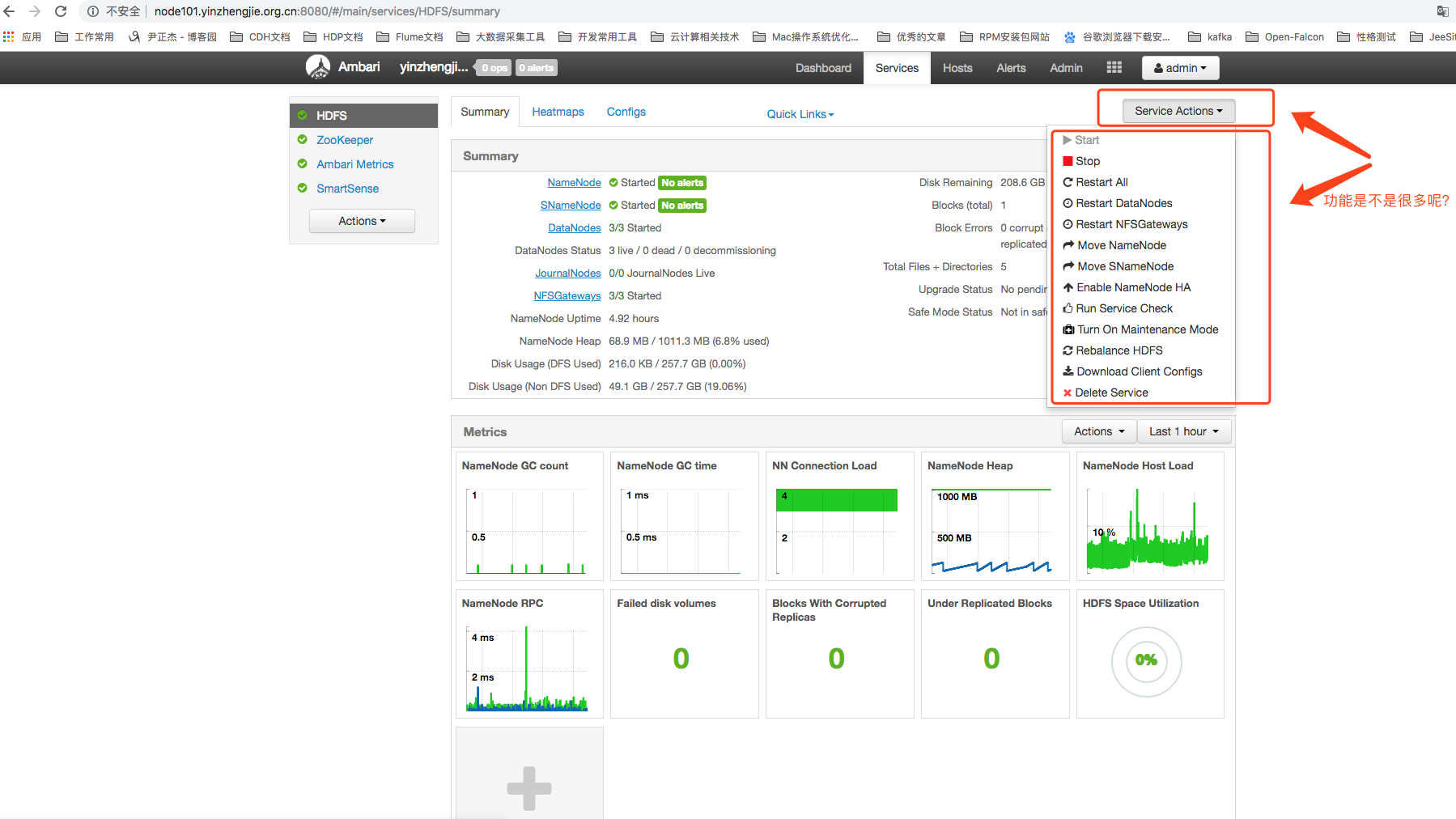
2>.集群服务控制与监控
Ambari 的管理控制台还提供了对集群服务监控的能力。为了便于理解,这里以HDFS位列来举例说明。对于其他服务的监控与HDFS类似。

如上图所示,使用左侧组件菜单点击HDFS,可以看到右边页面切换成了HDFS的整体信息摘要,从摘要页面可以看到HDFS的Namenode和Datanode服务的状态概要信息,同时也能看到一些简单的指标,比如内存垃圾回收次数,连接负载等。不仅如此,如下图所示,通过右上角的“Server Actions”菜单,还能实现对HDFS进行各种操作,例如启动,停止,重启,平衡负载,下载客户端配置和删除服务等等。只需要点点鼠标就能完成集群服务的控制,这些功能和CDH几乎是一样的。对CDH熟悉的小伙伴来看HDP的界面估计会很快就能上手的哟!
二.集群服务配置
Ambari也提供对集群服务对配置进行维护对功能,免去了手工修改配置对低效和繁琐。为了便于理解,这里还是以HDFS为例来进行举例说明。
1>.查看HDFS常用的一些配置
如下图所示,在HDFS的信息摘要页面点击Config菜单,页面会切换成HDFS的配置页面。映入眼帘的是HDFS最常用的一些配置,例如NameNode和DataNode的文件路径,NameNode和DataNode的堆内存大小等等,我们可以通过图形化交互的方式轻松的修改这些配置参数。

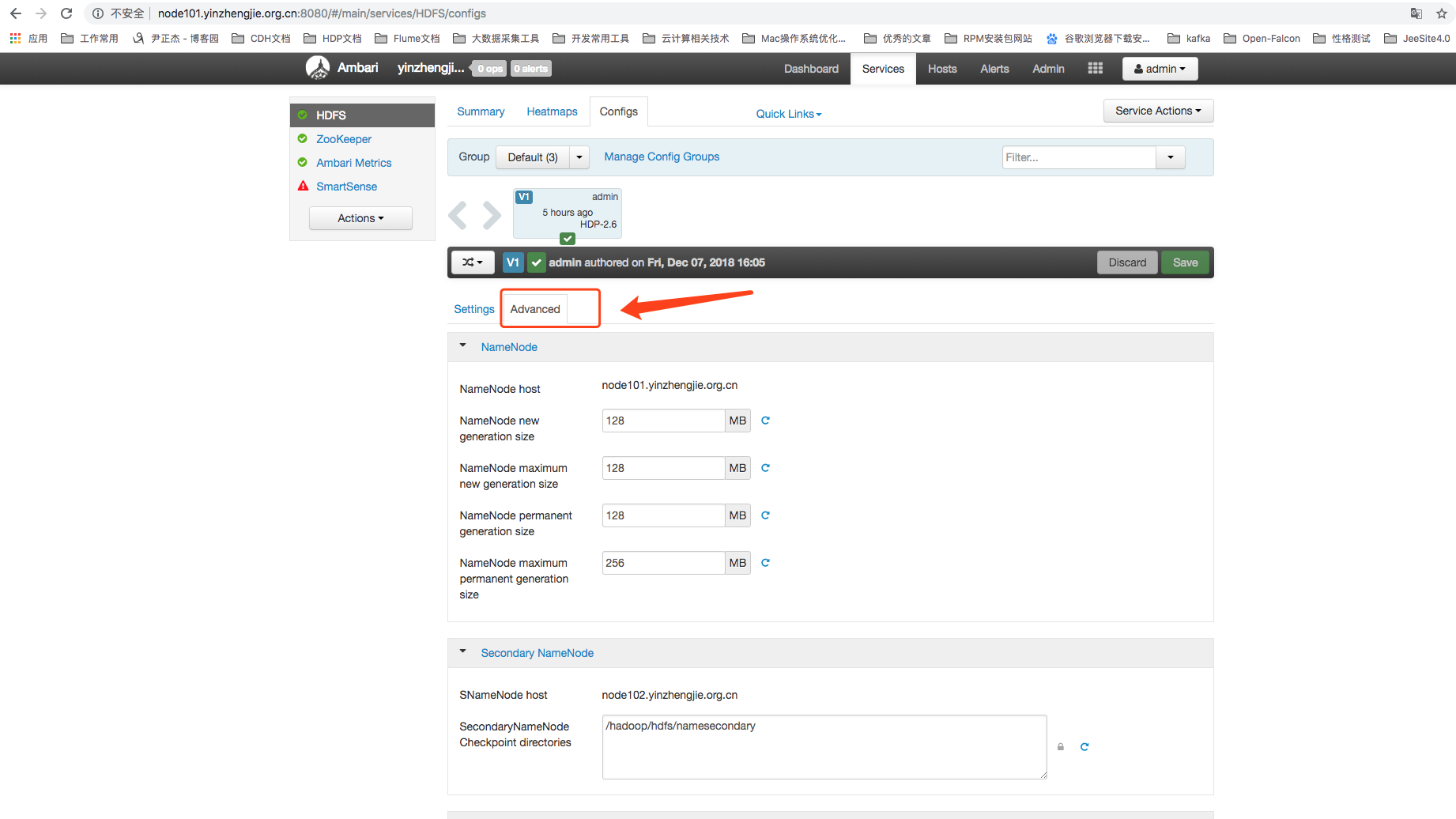
2>.HDFS的高级设置
除了上述这些常用配置之外,还可以进行更进一步的高级设置。如下图所示,点击Advanced按钮切换到高级设置页面,可以看到在高级配置页面已经定义了HDFS所有的可配置项。
在找到需要修改的配置进行修改之后单击Save按钮即可完成修改动作,如下图所所示:
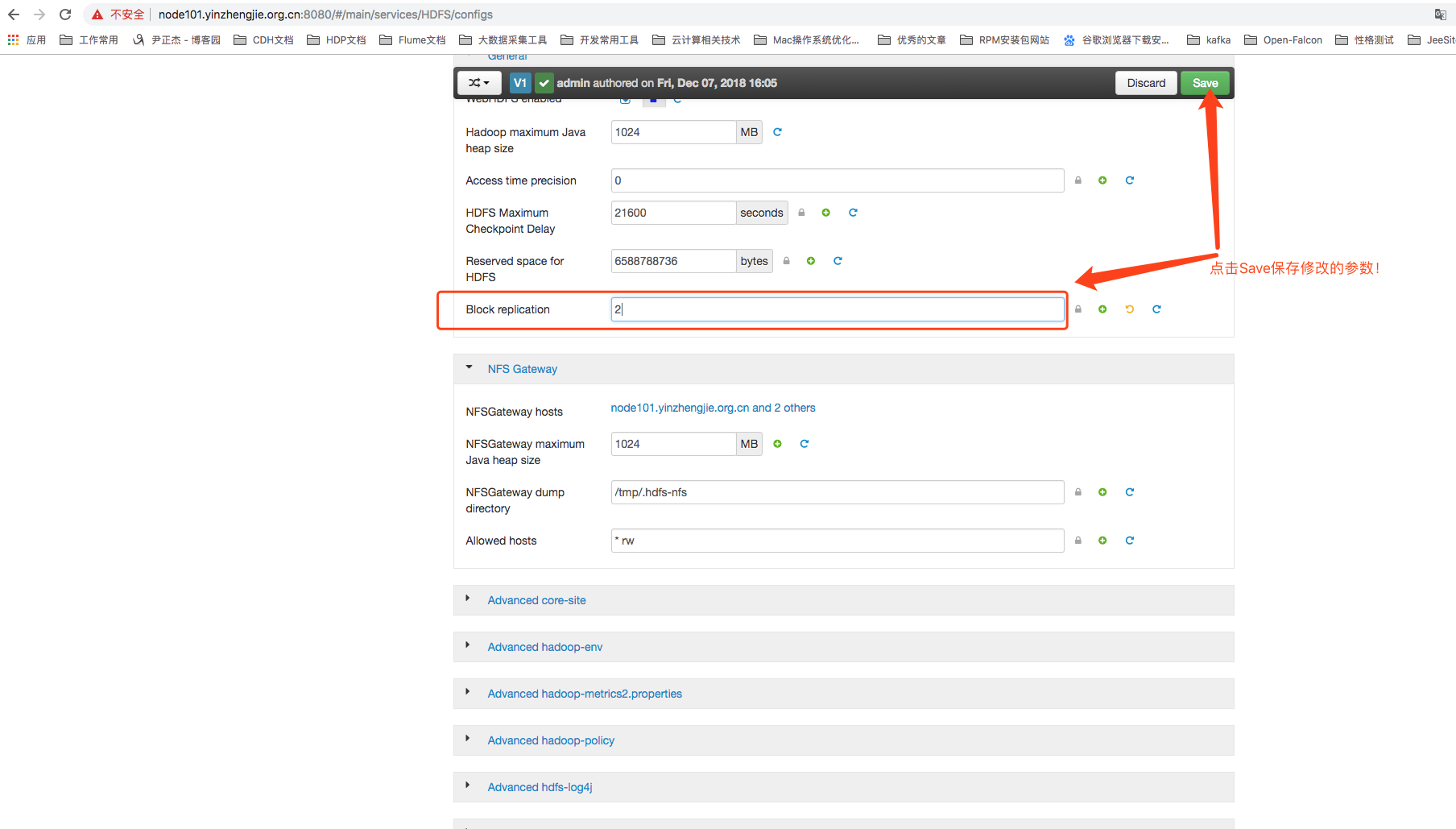
点击保存后,可能要你输入本次修改的一个备注信息!如下图所示:
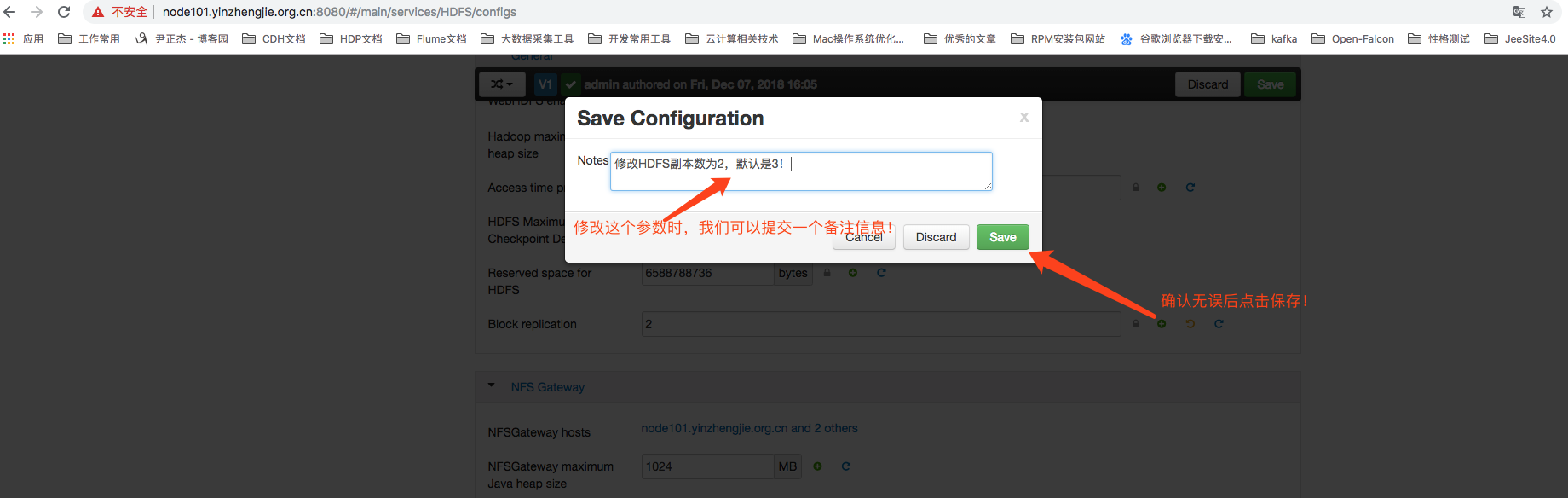
点击上图所示的“Save”成功后,可能会弹出如下图所示的对话框(提示保存配置成功),点击“ok”即可。
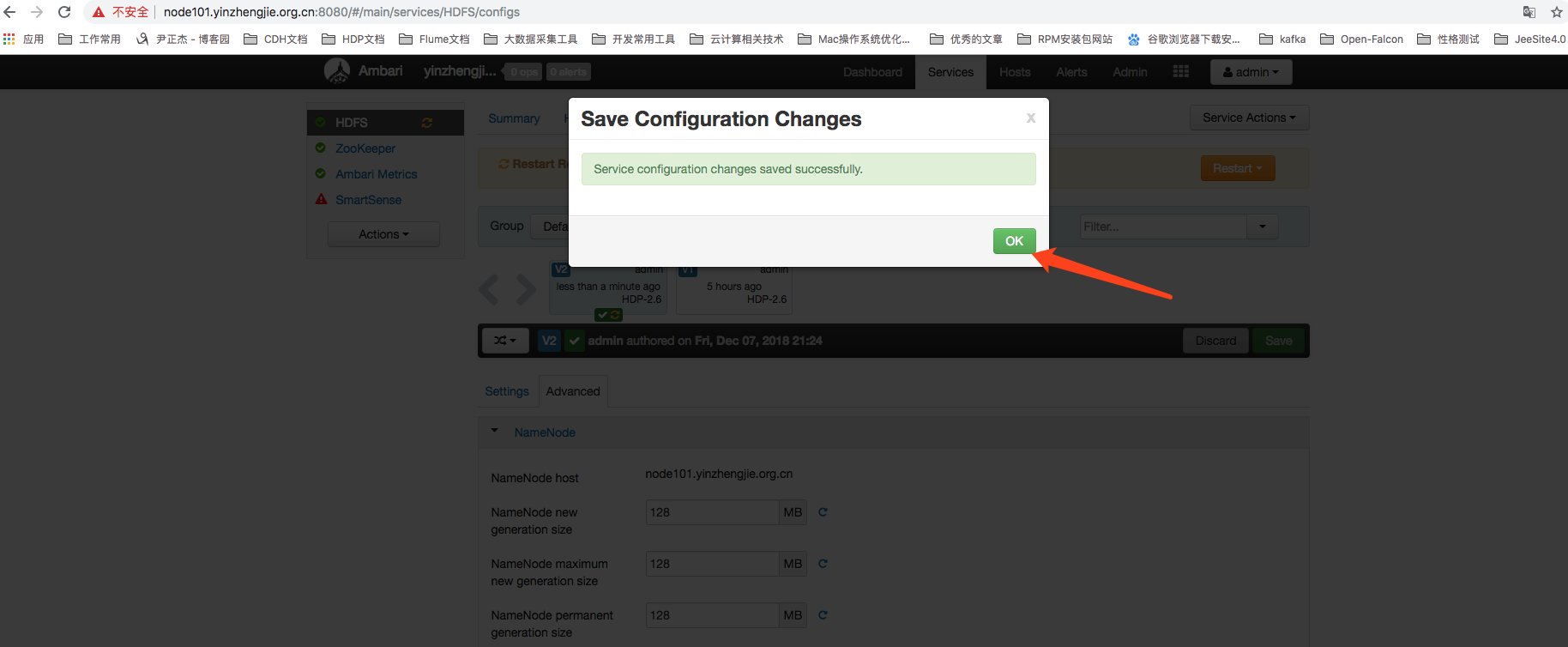
如下图所示,如果修改的配置需要相应的关联服务重启之后才能生效的化,Ambari也会通过提醒的方式让我们快速地进行服务重启。 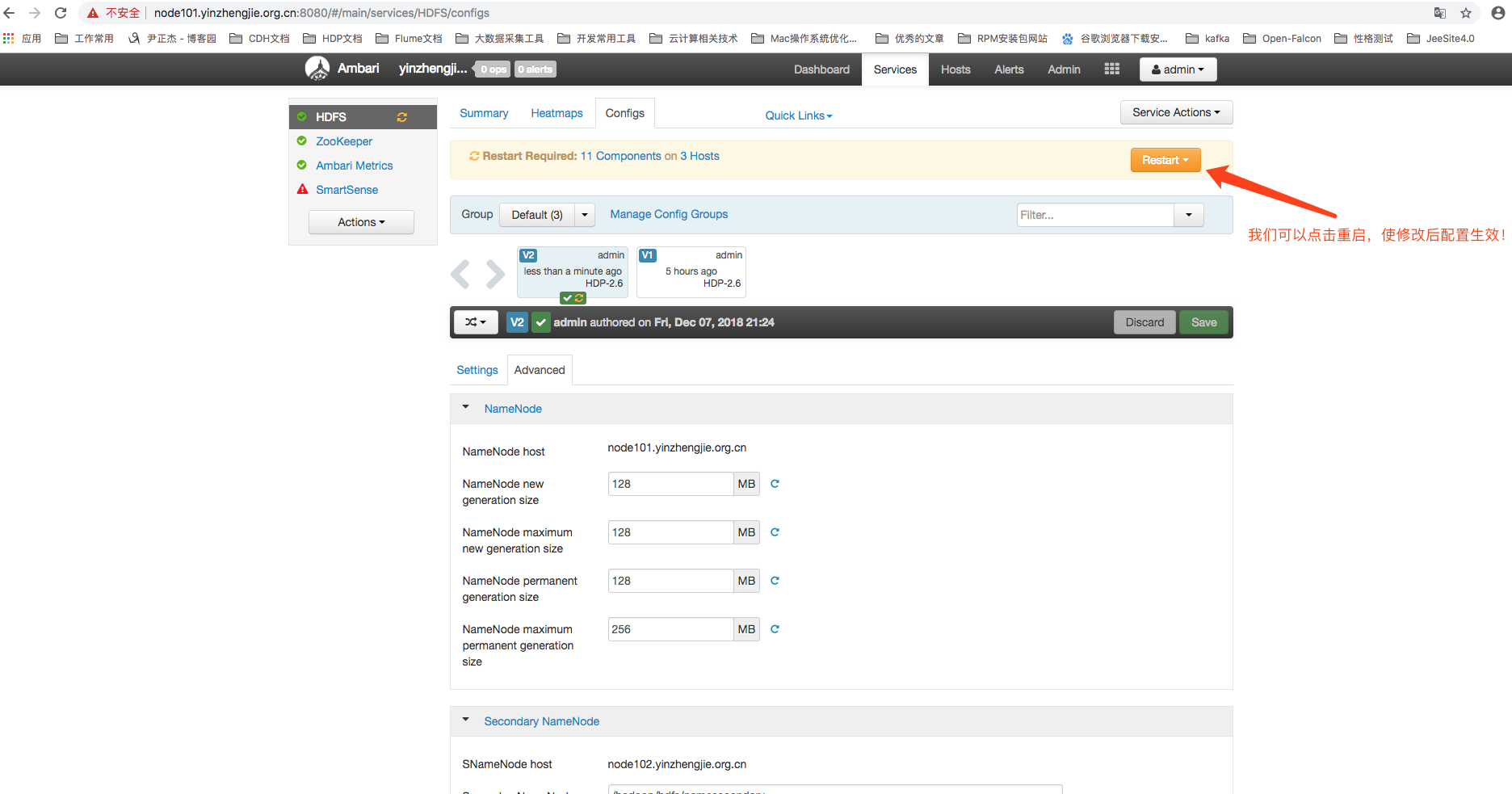
下图是重启过程中的截图:
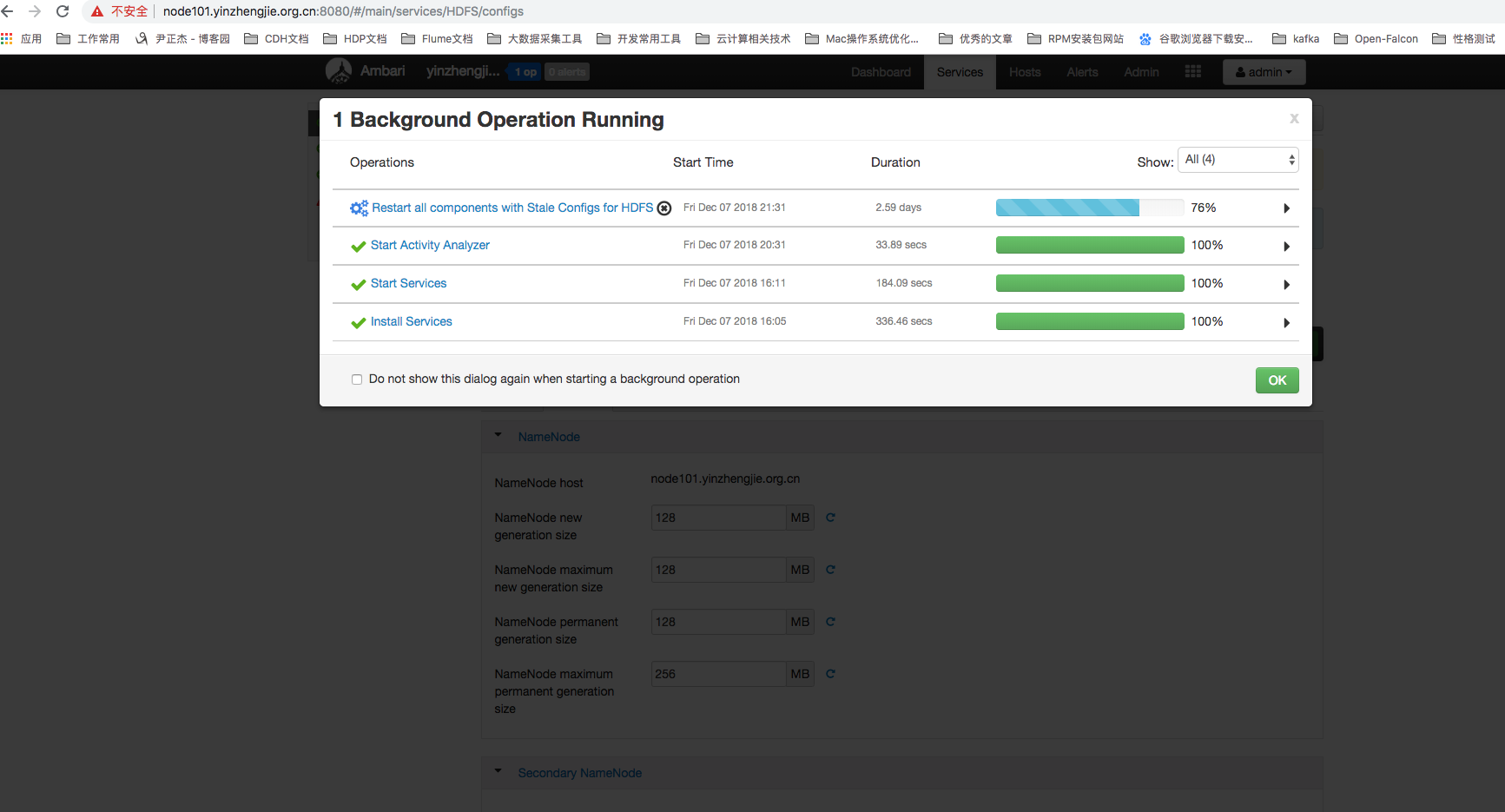
3>.修改版本回退案例
如果配置参数修改错误了怎么办呢?这个也不用咱们担心,Ambari会自动记录配置修改的历史轨迹,每一次的修改都会再生成一个版本。如下图所示:我们在修改之后可以随时浏览历史版本的配置项,还可以对比不同版本的配置内容,甚至还可以恢复到某个版本的配置内容哟!
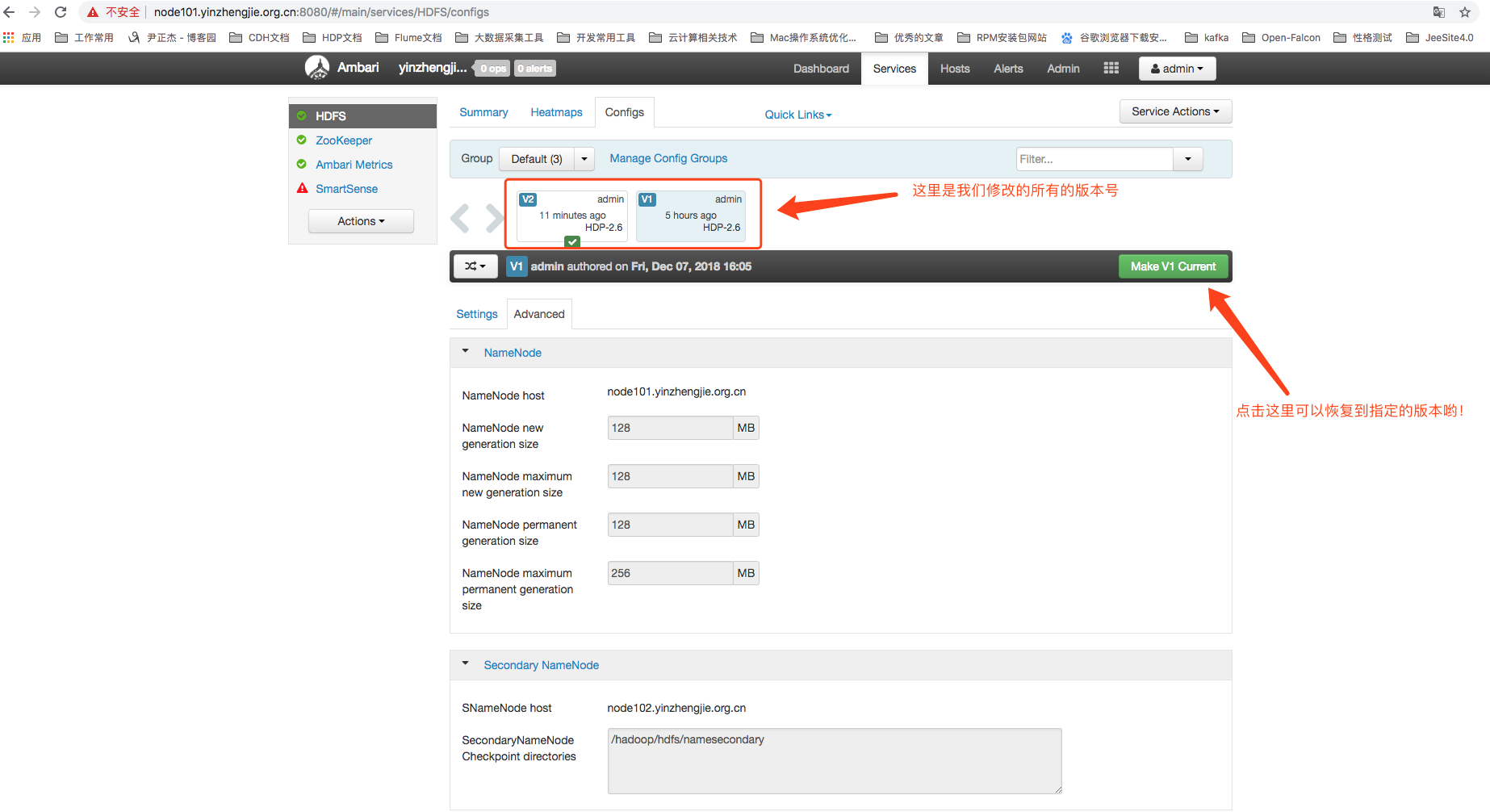
如下图说是,我们将之前到配置修复回去,即将副本数为2恢复到之前到副本数为3到配置(因为在本篇博客中我只修改到了这一处参数!):
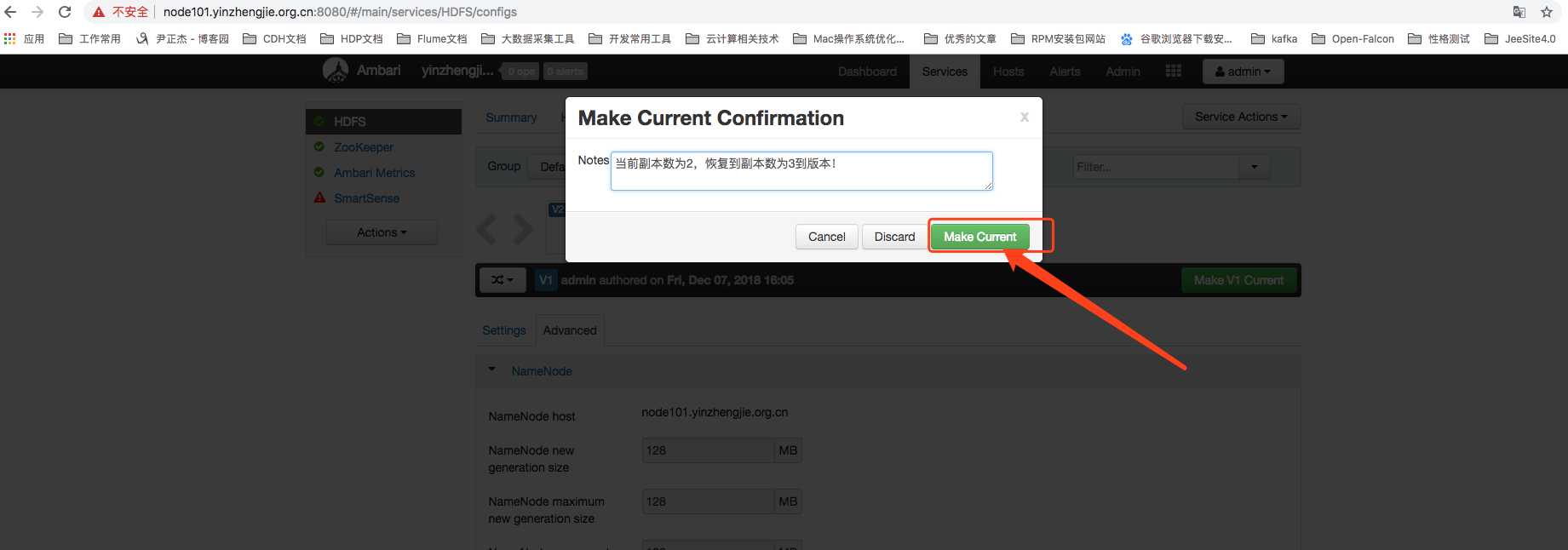
如下图所示,我们在V2的版本上恢复到V1的配置,那么会自动生成一个新的版本,修改后,我们依旧需要重启服务哟!
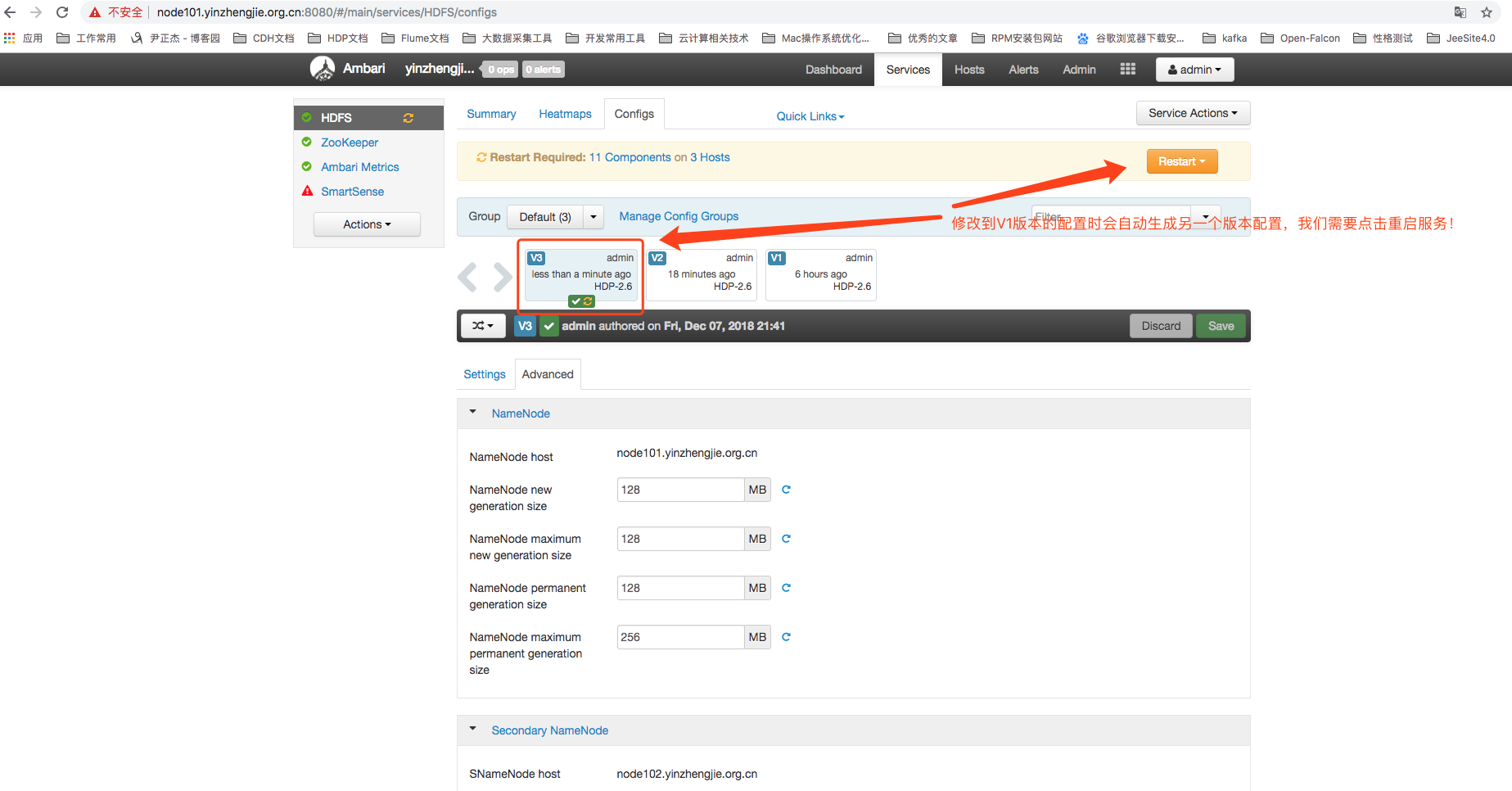
重启时,会有2个参数,一般情况下,我们应该选择第一个参数,如果你修改的参数是只针对Datanode节点生效的化,咱们也是可以只重启DataNode节点的哟!
4>.通过HDFS原声管理系统访问NameNode UI系统
大多数组件服务都会拥有自己的一套原生管理系统,这里还是以HDFS为例来进行举例说明。如下图说是,HDFS就有NameNode UI系统用来观察集群状态和查看文件。如果想快速链接到组件服务相应的原声UI系统可以通过“Quick Links”功能进行便捷的页面链接。
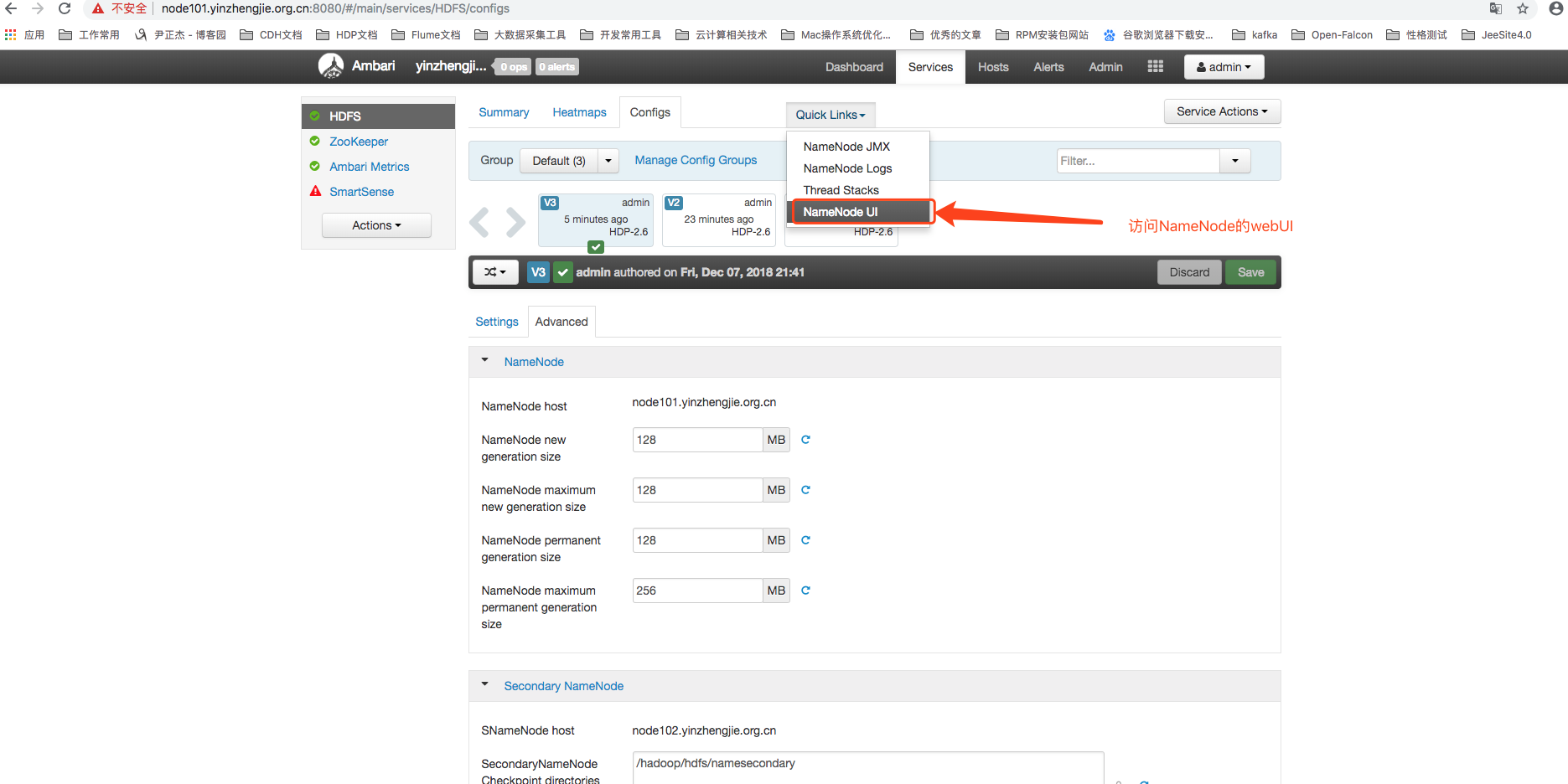
如下图所示,点击上图中的“NameNode UI”按钮就可以访问NameNode 的WebUI界面。
三.Ambari提供的辅助工具
Ambari 在提供了集群的安装,管理和监控功能的同时,还附带了一些十分有用的辅助工具,用于提示Hadoop服务使用的易用性。
1>.HDFS文件管理
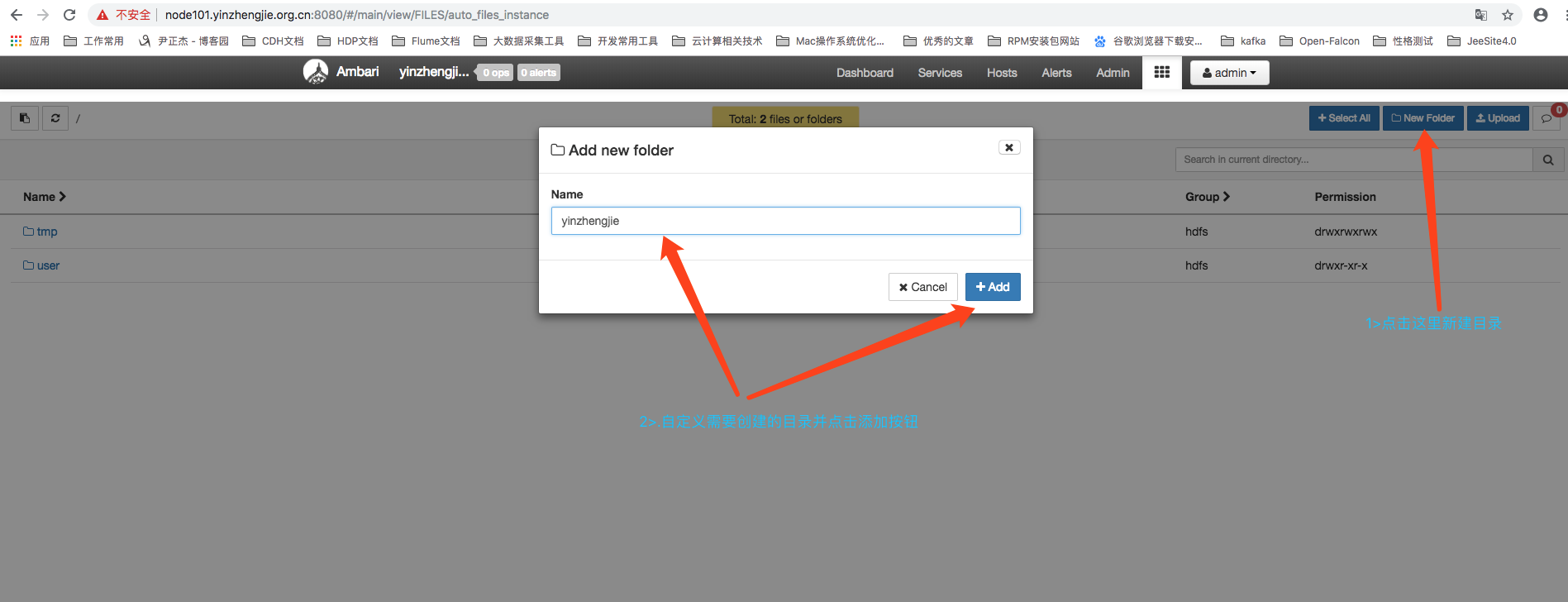
HDFS是一个分布式文件系统,默认的情况下我们只能通过它并提供Shell命令进程日常的维护操作,这种操作方式有一定的使用门槛,并且不直观。Ambari提供了针对HDFS的文件管理功能,让我们通过可视化的方式查看HDFS上的目录和文件列表,同时通过功能按钮还能新建目录和上传文件,如下图所示,这种管理方式十分的方便。

创建新目录,如下:
如果你创建失败时,可能会有以下的提示信息:
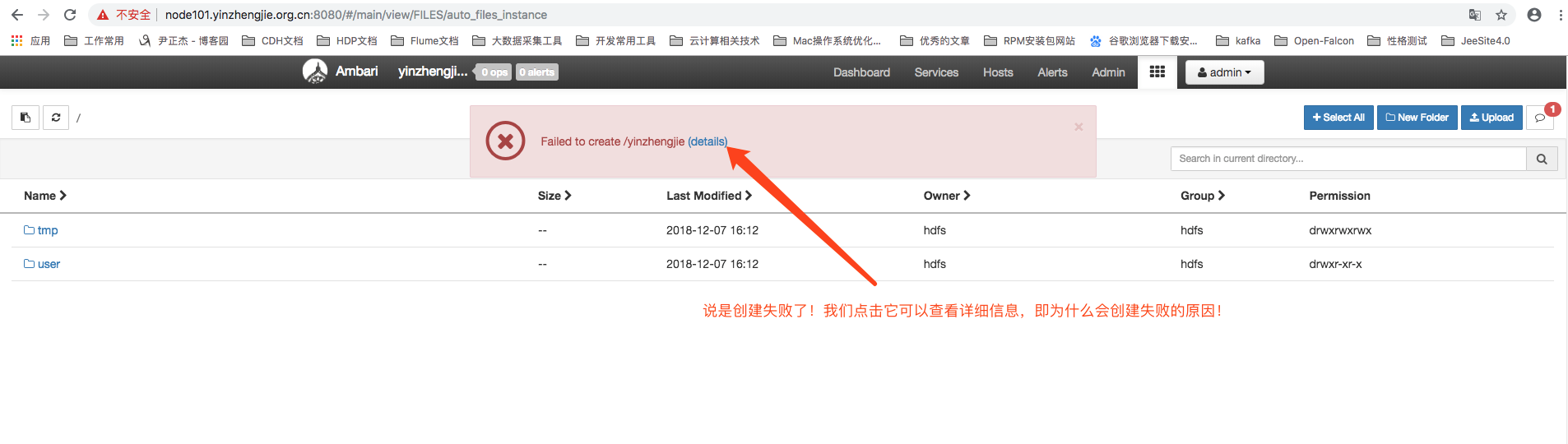
查看创建目录失败的原因(当前用户是admin),如下图所示:
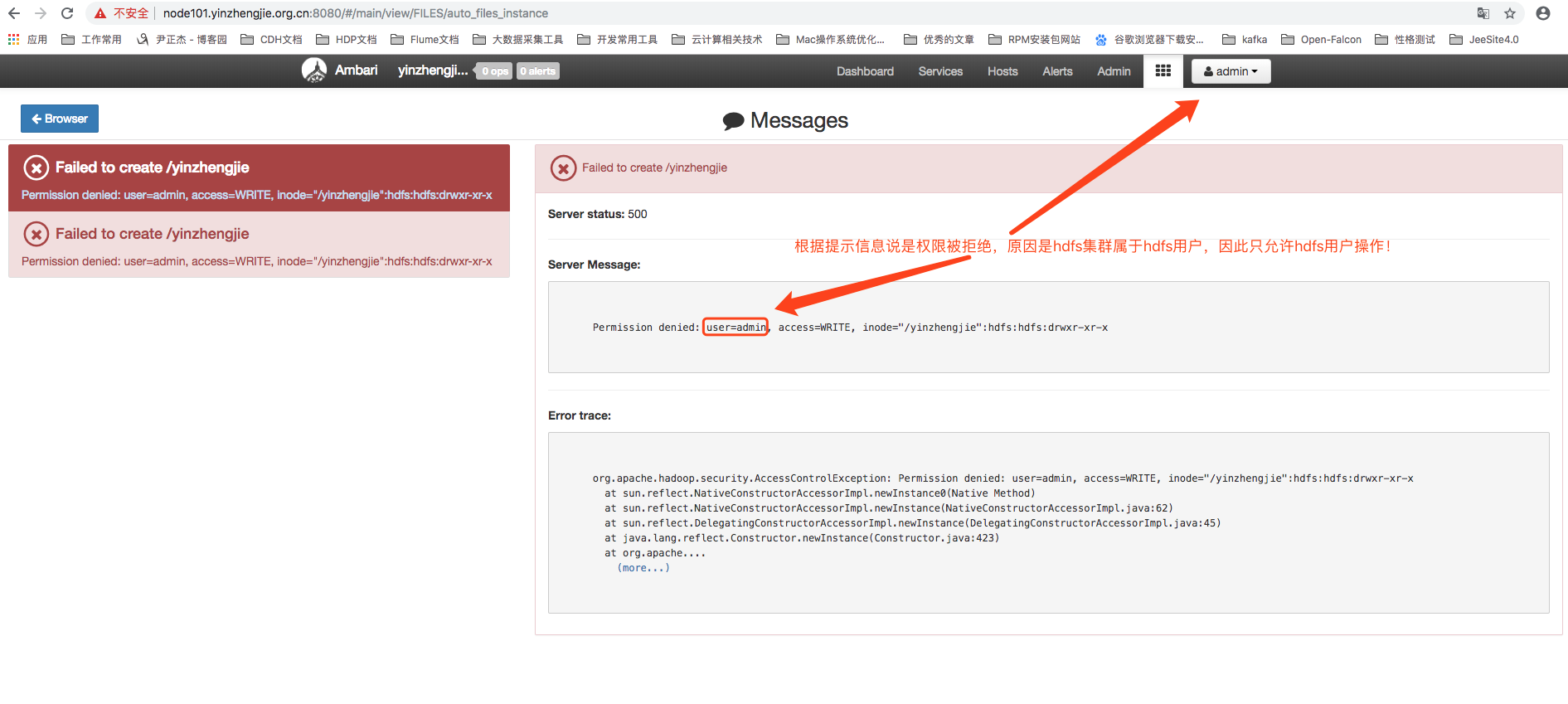
上面的报错是由于hdfs默认是开启用户认证的方式的,我们想要解决这个报错,暴力的方法有两个:第一,关闭掉认证机制;第二,使用hdfs用户创建“/yinzhengjie”目录即可。
[root@node101 ~]# su hdfs
[hdfs@node101 root]$ hdfs dfs -ls /
Found items
drwxrwxrwx - hdfs hdfs -- : /tmp
drwxr-xr-x - hdfs hdfs -- : /user
[hdfs@node101 root]$
[hdfs@node101 root]$ hdfs dfs -mkdir /yinzhengjie
[hdfs@node101 root]$
[hdfs@node101 root]$ hdfs dfs -chmod -R /yinzhengjie
[hdfs@node101 root]$
[hdfs@node101 root]$ hdfs dfs -ls /
Found items
drwxrwxrwx - hdfs hdfs -- : /tmp
drwxr-xr-x - hdfs hdfs -- : /user
drwxrwxrwx - hdfs hdfs -- : /yinzhengjie
[hdfs@node101 root]$
创建对应的用户到hdfs集群上。
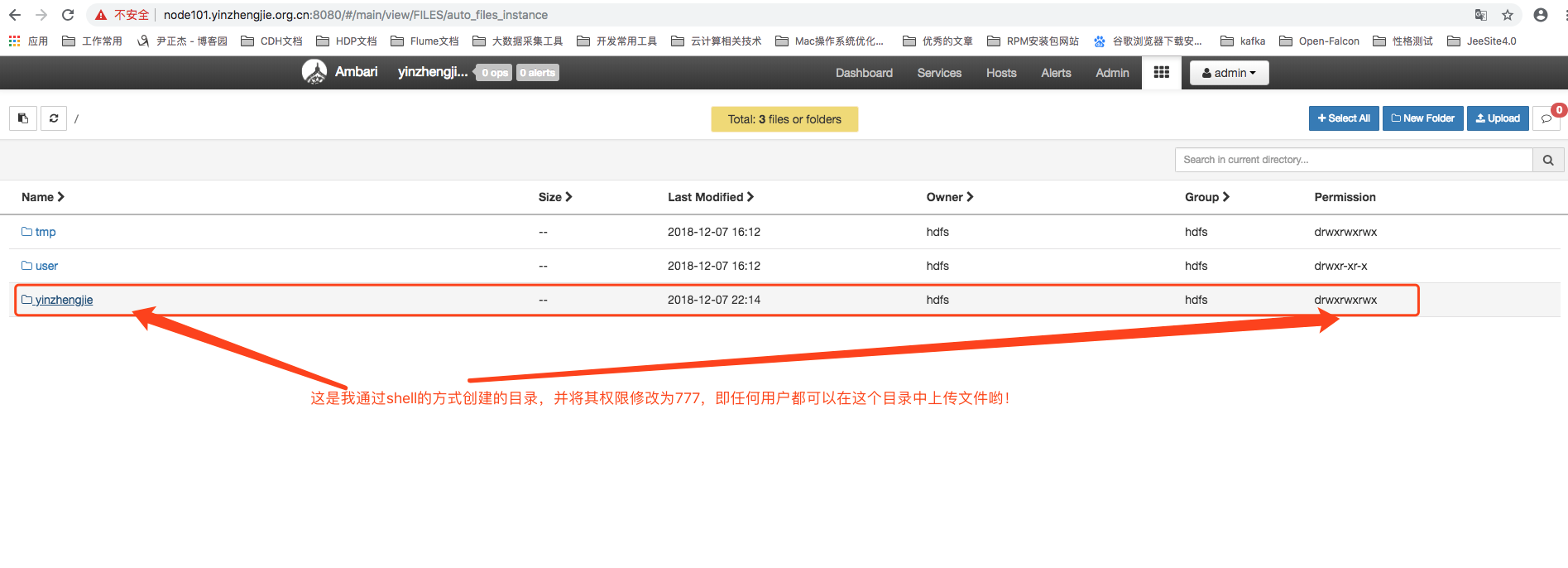
如下图所示,上传本地文件到hdfs集群中。

2>.其他辅助工具
其实Ambari提供了很多辅助工具,比如上述到HDFS文件管理。还有Hive 查询工具,Yarn任务队列管理,自助式分析系统等等。可能有的小伙伴会说:“并没有什么卵用,CDH以及继承了HUE,而HUE上述到这些功能基本上都包括!”,其实工具主要在于使用者本身,有的人喜欢使用CDH,他们更喜欢CDH炫酷都webUI界面!而有的人则喜欢HDP,这一点我并不要求大家使用那块软件,我的建议是:“CDH和HDP两个产品,你熟悉哪个就用哪个比较好!”。由于我们在安装的时候只安装了基础的监控服务,以及HDFS和zookeeper服务,因此其他的功能我暂时就不给大家做一一举例啦~
如果有机会的话我会给大家进行一一的分享操作,时间也不早了,在这里我预祝大家工作顺利!
Hadoop生态圈-Ambari控制台功能简介的更多相关文章
- Hadoop生态圈-开启Ambari的Kerberos安全选项
Hadoop生态圈-开启Ambari的Kerberos安全选项 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在完成IPA-Server服务的安装之后,我们已经了解了他提供的基础功 ...
- Hortworks Hadoop生态圈简介
Hortworks 作为Apache Hadoop2.0社区的开拓者,构建了一套自己的Hadoop生态圈,包括存储数据的HDFS,资源管理框架YARN,计算模型MAPREDUCE.TEZ等,服务于数据 ...
- 基于ambari搭建hadoop生态圈大数据组件
Ambari介绍1Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应.管理和监控.Ambari已支持大多数Hadoop组件,包括HDFS.MapReduce.H ...
- Hadoop生态圈以及各组成部分的简介
1.Hadoop是什么? 适合大数据的分布式存储与计算平台 HDFS: Hadoop Distributed File System分布式文件系统 MapReduce:并行计算框架 解决的问题: HD ...
- Hadoop生态圈-使用FreeIPA安装Kerberos和LDAP
Hadoop生态圈-使用FreeIPA安装Kerberos和LDAP 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 有些大数据平台只是简单地通过防火墙来解决他们的网络安全问题.十分 ...
- Hadoop生态圈-Ranger数据安全管理框架
Hadoop生态圈-Ranger数据安全管理框架 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Ranger简介 Apache Ranger是一款被设计成全面掌握Hadoop生 ...
- Hadoop生态圈-Knox网关的应用案例
Hadoop生态圈-Knox网关的应用案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Knox网关简介 据Knox官网所述(http://knox.apache.org/) ...
- hadoop生态圈介绍
原文地址:大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用户可以在不了解分 ...
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
随机推荐
- python代码块,小数据池,驻留机制深入剖析
一,什么是代码块. 根据官网提示我们可以获知: 根据提示我们从官方文档找到了这样的说法: A Python program is constructed from code blocks. A blo ...
- jQuery File Upload 图片上传解决方案兼容IE6+
1.下载:https://github.com/blueimp/jQuery-File-Upload 2.命令: npm install bower install ================= ...
- redis主从复制和sentinel配置高可用
一:redis主从配置1.环境准备 master : 192.168.50.10 6179 slave1: 192.168.50.10 6279 slave2: 192.168.50.10 63792 ...
- 【BZOJ3613】[HEOI2014]南园满地堆轻絮(贪心)
[BZOJ3613][HEOI2014]南园满地堆轻絮(贪心) 题面 BZOJ 洛谷 题解 考虑二分的做法,每次二分一个答案,那么就会让所有的值尽可能的减少,那么\(O(n)\)扫一遍就好了. 考虑如 ...
- 【BZOJ3142】[HNOI2013]数列(组合计数)
[BZOJ3142][HNOI2013]数列(组合计数) 题面 BZOJ 洛谷 题解 唯一考虑的就是把一段值给分配给\(k-1\)天,假设这\(k-1\)天分配好了,第\(i\)天是\(a_i\),假 ...
- Paint the Wall ZOJ - 2747
点数很多,坐标值很大,然后离散化一下用一个点表示一小块的面积对应的颜色,然后更新的时候一块一块更新,查询的时候一块一块查询 #include<map> #include<set> ...
- CANOE入门(三)
最好的学习方式是什么?模仿.有人会问,那不是山寨么?但是我认为,那是模仿的初级阶段,当把别人最好的设计已经融化到自己的血液里,变成自己的东西,而灵活运用的时候,才是真正高级阶段.正所谓画虎画皮难画骨. ...
- centos7/centos6修改系统默认语言
应用环境: 一直在使用centos7.x,系统默认的语言也是英文环境,工作内容偶遇中文,顺便搜罗修改一番,小记如下. 测试环境: 测试步骤: CentOS 7.x 1. 查看当前语言环境 [root@ ...
- 20165223 week2学习查漏补缺
标识符.字符集.关键字 基本数据类型 逻辑类型:boolean 常量:true.false 变量:boolean赋值 整数类型:byte.short.long.int 注意long型后缀L Java没 ...
- 洛谷P1477 假面舞会
坑死了...... 题意:给你个有向图,你需要把点分成k种,满足每条边都是分层的(从i种点连向i + 1种点,从k连向1). 要确保每种点至少有一个. 求k的最大值,最小值. n <= 1e5, ...