Spark大数据平台安装教程
一.Spark介绍
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是开源的类Hadoop MapReduce的通用并行框架,Spark拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
二.安装Spark
环境:Docker(17.04.0-ce)、镜像Ubuntu(16.04.3)、JDK(1.8.0_144)、Hadoop(3.1.1)、Spark(2.3.2)
1.安装Hadoop
参考:Hadoop伪分布式模式安装
2.解压Spark
bigdata@lab-bd:~$ tar -xf spark-2.3.-bin-without-hadoop.tgz
3.重名名conf/spark-env.sh.template为spark-env.sh
bigdata@lab-bd:~$ mv spark-2.3.-bin-without-hadoop/conf/spark-env.sh.template spark-2.3.-bin-without-hadoop/conf/spark-env.sh
4.编辑conf/spark-env.sh文件,增加如下变量
export JAVA_HOME=/home/hadoop/jdk1..0_144
export SPARK_DIST_CLASSPATH=$(/home/hadoop/hadoop-3.1./bin/hadoop classpath)
export HADOOP_CONF_DIR=/home/hadoop/hadoop-3.1./etc/hadoop
export PYSPARK_PYTHON=/usr/bin/python3.
三.运行Spark
1.启动Hdfs服务
bigdata@lab-bd:~$ hadoop-3.1./sbin/start-dfs.sh
2.启动Yarn服务
bigdata@lab-bd:~$ hadoop-3.1./sbin/start-yarn.sh
3.交互模式运行pyspark
bigdata@lab-bd:~$ spark-2.3.-bin-without-hadoop/bin/pyspark --master yarn --deploy-mode client 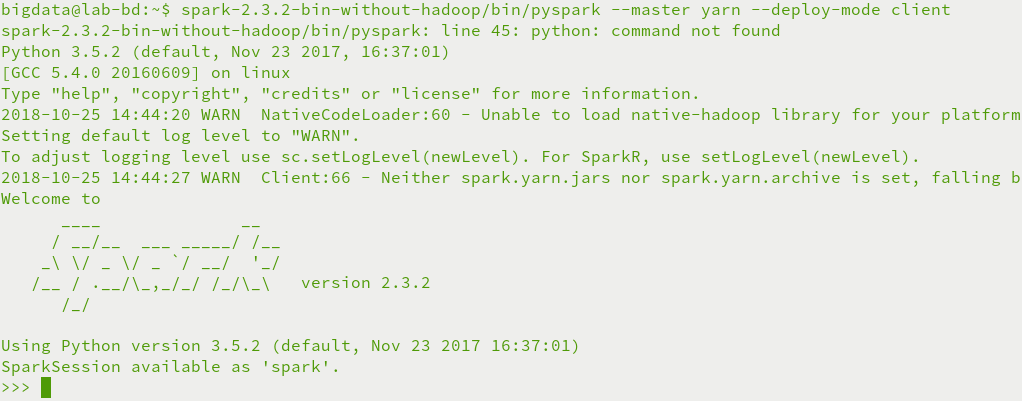
4.提交模式运行spark-submit
bigdata@lab-bd:~$ spark-2.3.-bin-without-hadoop/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client \
> spark-2.3.-bin-without-hadoop/examples/jars/spark-examples_2.-2.3..jar
5.浏览器访问http://10.0.0.3:8088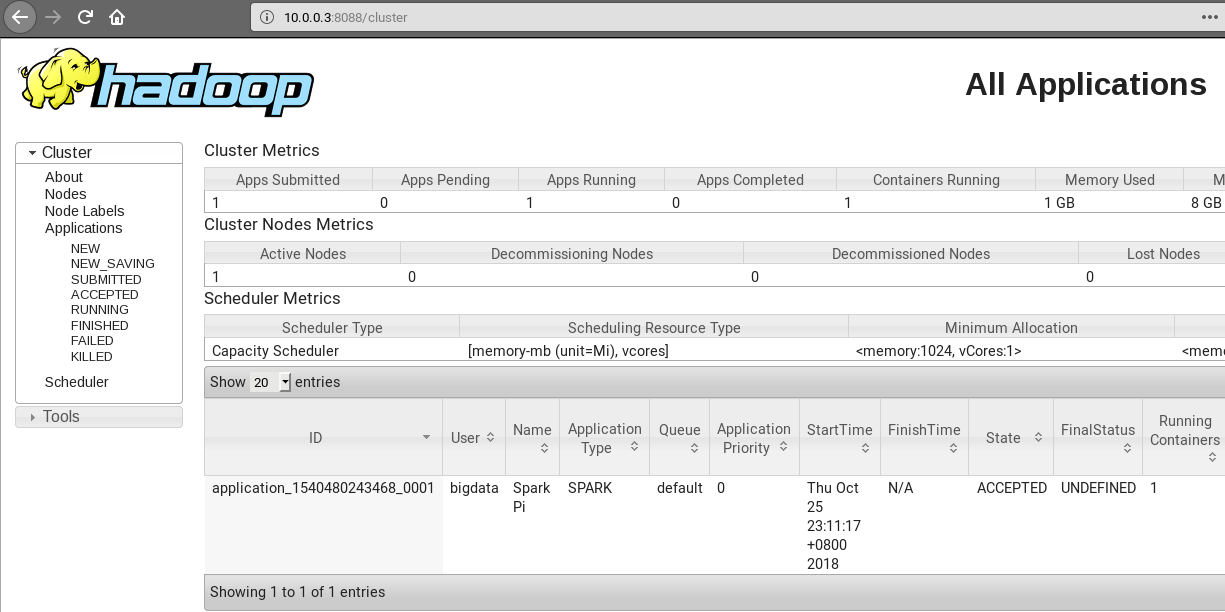
四.启动异常
1.Caused by: java.lang.ClassNotFoundException: org.slf4j.Logger异常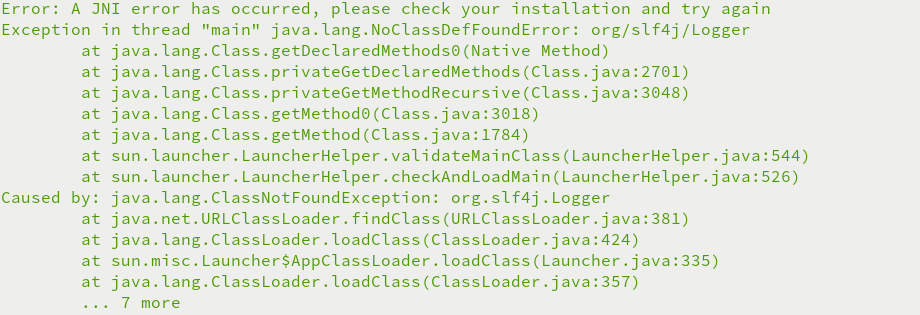
Hadoop和Spark独立安装,Spakr运行需要Hadoop,无SPARK_DIST_CLASSPATH变量,无法关联hadoop
编辑conf/spark-env.sh文件,配置SPARK_DIST_CLASSPATH变量
export SPARK_DIST_CLASSPATH=$(/home/bigdata/hadoop-3.1./bin/hadoop classpath)
2.Exception in thread "main" java.lang.Exception: When running with master 'yarn' either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment异常
Hadoop和Spark独立安装,Spakr运行需要Hadoop,无HADOOP_CONF_DIR变量,无法关联YARN
编辑conf/spark-env.sh文件,配置HADOOP_CONF_DIR变量
export HADOOP_CONF_DIR=/home/bigdata/hadoop-3.1./etc/hadoop
3.org.apache.spark.rpc.RpcEnvStoppedException: RpcEnv already stopped异常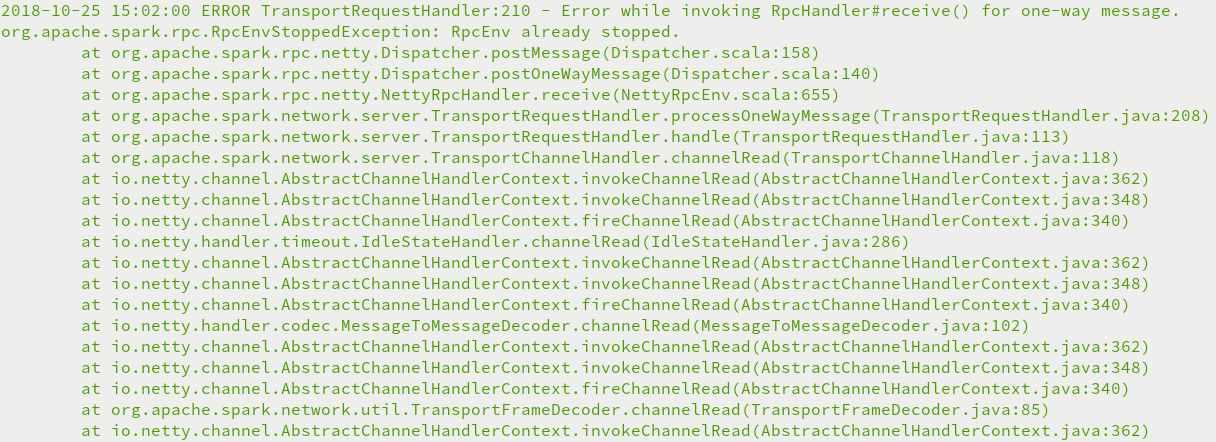
物理内存或者虚拟内存分配不够,Yarn直接杀死进程,需要禁止内存检查
编辑Hadoop中的etc/hadoop/yarn-site.xml文件,添加如下配置
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
4.env: 'python': No such file or directory错误
pyspark需要使用python,未配置PYSPARK_PYTHON变量
export PYSPARK_PYTHON=/usr/bin/python3.
Spark大数据平台安装教程的更多相关文章
- 【福利】送Spark大数据平台视频学习资料
没有套路真的是送!! 大家都知道,大数据行业spark很重要,那话我就不多说了,贴心的大叔给你找了份spark的资料. 多啰嗦两句,一个好的程序猿的基本素养是学习能力和自驱力.视频给了你们,能不能 ...
- 最新版大数据平台安装部署指南,HDP-2.6.5.0,ambari-2.6.2.0
一.服务器环境配置 1 系统要求 名称 地址 操作系统 root密码 Master1 10.1.0.30 Centos 7.7 Root@bidsum1 Master2 10.1.0.105 Cent ...
- GreenPlum 大数据平台--安装
1. 环境准备 01, 安装包准备: Greenplum : >>>>链接地址 Pgadmin客户端 : >>>链接地址 greenplum-cc-web ...
- Spark 大数据平台 Introduction part 2 coding
Basic Functions sc.parallelize(List(1,2,3,4,5,6)).map(_ * 2).filter(_ > 5).collect() *** res: Arr ...
- Spark 大数据平台
Apache Spark is an open source cluster computing system that aims to make data analytics fast - both ...
- 大数据平台R语言web UI应用架构 设计与开发
1. 系统拓扑图 在日常业务分析中,R是非常常用的分析工具,而当数据量较大时,用R语言需要需用更多的时间来完成训练模型,spark作为大规模数据处理框架,采用内存计算,可以短时间内完成大量的数据的处理 ...
- HDP 企业级大数据平台
一 前言 阅读本文前需要掌握的知识: Linux基本原理和命令 Hadoop生态系统(包括HDFS,Spark的原理和安装命令) 由于Hadoop生态系统组件众多,导致大数据平台多节点的部署,监控极其 ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- Spark大型项目实战:电商用户行为分析大数据平台
本项目主要讲解了一套应用于互联网电商企业中,使用Java.Spark等技术开发的大数据统计分析平台,对电商网站的各种用户行为(访问行为.页面跳转行为.购物行为.广告点击行为等)进行复杂的分析.用统计分 ...
随机推荐
- [PHP] PHP闭包(closures)
1.闭包函数也叫匿名函数,一个没有指定名称的函数,一般会用在回调部分 2.闭包作为回调的基本使用, echo preg_replace_callback('~-([a-z])~', function ...
- 慢查询日志工具mysqlsla的使用
安装mysqlsla源码路径:https://github.com/daniel-nichter/hackmysql.com源码存放路径:/usr/local/src1.获取源码如果没有git命令,请 ...
- 改变Tomcat在地址栏上显示的小猫图标
部署在Tomcat上的项目通常在地址栏会显示一个小猫的图标,那么如何改变这个图标呢? 第一步.制作自己显示的图标 这里使用的是在线制作的方式,推荐一个在线制作的网站---比特虫:http://www. ...
- 洛谷P2234 [HNOI2002]营业额统计
题目描述 Tiger最近被公司升任为营业部经理,他上任后接受公司交给的第一项任务便是统计并分析公司成立以来的营业情况. Tiger拿出了公司的账本,账本上记录了公司成立以来每天的营业额.分析营业情况是 ...
- openEntityForm如何给关于(regardingobjectid)类型查找字段赋值?
本人微信和易信公众号: 微软动态CRM专家罗勇 ,回复264或者20170924可方便获取本文,同时可以在第一间得到我发布的最新的博文信息,follow me!我的网站是 www.luoyong.me ...
- TFS 2017 持续集成速记
VS2017许多激动人 心的功能,升级! TFS2017也升级,不支持SQL2012,升级!不过貌似开发版不能升级,好吧,开发版升2014企业版! 2017据说不支持XAML生成了,但后台菜单中还 ...
- vue-cil和webpack中本地静态图片的路径问题解决方案
1 本地图片动态绑定img的src属性 一般我们在html中或者vue组件文件中引用图片是这样,这是不需要做特别处理的 我们将图片放入assets中或者重新建立个文件夹img什么的都可以,随意- 但是 ...
- Python 利用Python操作excel表格之openyxl介绍Part2
利用Python操作excel表格之openyxl介绍 by:授客 QQ:1033553122 欢迎加入全国软件测试交流qq群(群号:7156436) ## 绘图 c = LineChart() ...
- Testlink1.9.17使用方法(第五章 测试用例管理)
第五章 测试用例管理 QQ交流群:585499566 TestLink支持的测试用例的管理包含二层:分别为新建测试用例集(Test Suites).创建测试用例(Test Cases).可以把测试用例 ...
- 深圳共创力“研发管理&知识管理”高端研讨交流会在深圳举办!
2017/4/8,由深圳市共创力企业管理咨询公司举办的“研发管理&知识管理”高端研讨会在深圳市南山区圣淘沙国际酒店(翡翠店)隆重召开.此次研讨会由共创力总经理.首席顾问杨学明先生主持.研讨会先 ...