SQL Server 分页编号的另一种方式
今天看书讲T-SQL,看到了UNBOUNDED PRECEDING,就想比对下ROW_NUMBER()的运行速度。
sql及相关的结果如下,数据库中的数据有5W+。
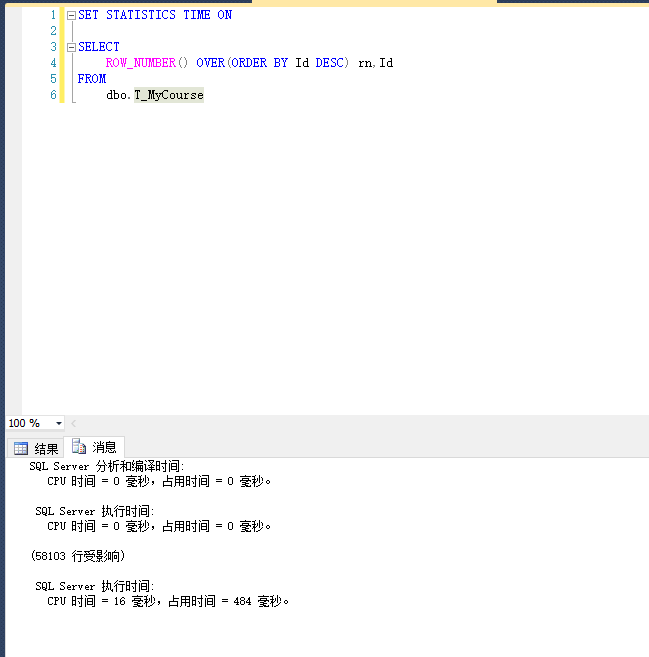
ROW_NUMBER():
SET STATISTICS TIME ON SELECT
ROW_NUMBER() OVER(ORDER BY Id DESC) rn,Id
FROM
dbo.T_MyCourse
运行结果
UNBOUNDED PRECEDING
SET STATISTICS TIME ON SELECT
SUM(1) OVER(ORDER BY Id DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) rn,Id
FROM
dbo.T_MyCourse
运行结果
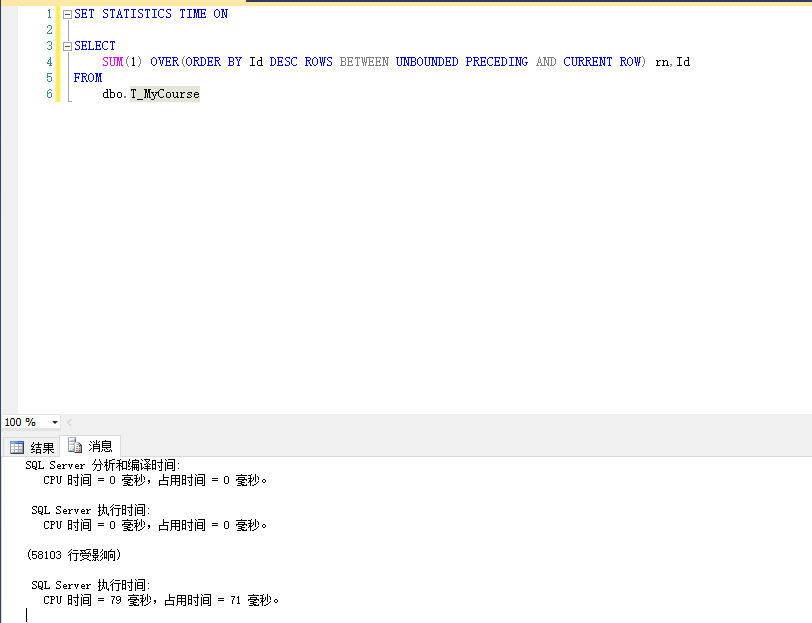
通过运行之后,看到结果,使用微软官方提供的方法进行编号排序,速度明显的提高。
不过我使用上述方法进行分页获取数据的时候结果又有点不一样。
分页获取数据:
ROW_NUMBER() 分页获取数据:
SET STATISTICS TIME ON SELECT
*
FROM
(
SELECT
ROW_NUMBER() OVER(ORDER BY Id DESC) rn,Id
FROM
dbo.T_MyCourse
)a
WHERE
a.rn BETWEEN 55 AND 444

执行sql命令:DBCC DROPCLEANBUFFERS ,清除数据库缓存后的结果

UNBOUNDED分页获取数据:
SET STATISTICS TIME ON SELECT
*
FROM
(
SELECT
SUM(1) OVER(ORDER BY Id DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) rn,Id
FROM
dbo.T_MyCourse
)a
WHERE
a.rn BETWEEN 22 AND 444

UNBOUNDED这个方式下执行了DBCC DROPCLEANBUFFERS 清除缓存的sql也没有用,执行时间没有变化。
通过上述结果,看到ROW_NUMBER()获取分页的数据明显更快,我猜测是微软对ROW_NUMBER()这个方法做了优化,可能是有缓存,读取的缓存中的数据然后进行分页。
如果有知道的网友,请评论告诉我,让我学习学习。
SQL Server 分页编号的另一种方式的更多相关文章
- SQL Server 2008 数据库同步的两种方式 (发布、订阅)
参考转载: SQL Server 2008 数据库同步的两种方式 (发布.订阅) 使用Sqlserver事务发布实现数据同步
- sql server中备份数据的几种方式
当我们在写sql脚本要对数据表中的数据进行修改的时候,为了防止破坏数据,通常在开发前都会对数据表的数据进行备份,当我们sql脚本开发并测试完成后,再把数据恢复回来. 目前备份数据,我常用的方法有以下几 ...
- 【转】SQL Server 2008 数据库同步的两种方式 (发布、订阅)
上篇中说了通过SQL JOB的方式对数据库的同步,这一节作为上一节的延续介绍通过发布订阅的方式实现数据库之间的同步操作.发布订阅份为两个步骤:1.发布.2.订阅.首先在数据源数据库服务器上对需要同步的 ...
- SQL server分页的四种方法
SQL server分页的四种方法 1.三重循环: 2.利用max(主键); 3.利用row_number关键字: 4.offset/fetch next关键字 方法一:三重循环思路 先取前20页, ...
- SQL server分页的四种方法(算很全面了)
这篇博客讲的是SQL server的分页方法,用的SQL server 2012版本.下面都用pageIndex表示页数,pageSize表示一页包含的记录.并且下面涉及到具体例子的,设定查询第2 ...
- SQL Server 分页方法汇总
PageSize = 30 PageNumber = 201 方法一:(最常用的分页代码, top / not in) UserId UserId from UserInfo order by Use ...
- SQL SERVER 分页方法
最近项目中需要在SQL SERVER中进行分页,需要编写分页查询语句.之前也写过一些关于分页查询的语句,但是性能不敢恭维.于是在业务时间,在微软社区Bing了一篇老外写的关于SQL SERVER分页的 ...
- SQL Server游标 C# DataTable.Select() 筛选数据 什么是SQL游标? SQL Server数据类型转换方法 LinQ是什么? SQL Server 分页方法汇总
SQL Server游标 转载自:http://www.cnblogs.com/knowledgesea/p/3699851.html. 什么是游标 结果集,结果集就是select查询之后返回的所 ...
- 二、SQL Server 分页
一.SQL Server 分页 --top not in方式 select top 条数 * from tablename where Id not in (select top 条数*页数 Id f ...
随机推荐
- Java变成思想--多线程
Executor :线程池 CatchedThreadPool:创建与所需数量相同的线程,在回收旧线程是停止创建新县城. FixedThreadPool:创建一定数量的线程,所有任务公用这些线程. S ...
- 判断Array/Object
Object.prototype.isPrototypeOf() / Array.prototype.isPrototypeOf()if(typeof items === "object ...
- Android开发者的Anko使用指南(二)之Dialogs
在项目中使用Anko Dialogs dependencies { compile "org.jetbrains.anko:anko-commons:$anko_version" ...
- IEDA的程序调试debug
以前只是浅层面的使用dubug来查看程序运行顺序,排查一些异常的原因, 今天由于要学习一些源码,所以系统的记录一下(借鉴网上资料总结而来) 主要涉及到的功能区为如下: A::重启项目 快捷键 Ctrl ...
- Python编程练习:使用 turtle 库完成正方形的绘制
绘制效果: 源代码: # 正方形 import turtle turtle.setup(650, 350, 200, 200) turtle.penup() turtle.pendown() turt ...
- HBase体系架构和集群安装
大家好,今天分享的是HBase体系架构和HBase集群安装.承接上两篇文章<HBase简介>和<HBase数据模型>,点击回顾这2篇文章,有助于更好地理解本文. 一.HBase ...
- Base 底层库开源项目总结
在Android开发中,我们经常使用一些开源的项目,一般情况下,这些开源项目都是基于开源的底层库进行的开发,以适配各自的用户场景.下面来列举一下本人收藏或Star的项目: 一.JavaCV 项目地址: ...
- Javascript高级编程学习笔记(63)—— 事件(7)鼠标及滚轮事件
鼠标与滚轮事件 鼠标事件是web开发中最常用的一类事件,毕竟鼠标是最主要的定位设备 DOM3级事件中定义了9个鼠标事件: click:在用户单击主鼠标按钮(一般为鼠标左键)或者按下回车时触发,这一点对 ...
- Java核心技术卷一基础知识-第7章-图形程序设计-读书笔记
第7章 图形程序设计 本章内容: * Swing概述 * 创建框架 * 框架定位 * 在组件中显示信息 * 处理2D图形 * 使用颜色 * 文本使用特殊字体 * 显示图像 本章主要讲述如何编写定义屏幕 ...
- 2.Git基础-仓库的获取方式与Git文件的状态变化周期(生命周期)
1.仓库的获取 Git仓库的获取有两种方式: 1.从现有目录或者是项目中导入所有文件到Git中. 2.从一个服务器clone一个现有的Git仓库. 如果使用第一种方式,只需要在你希望被Git进行管理的 ...