Gmapping笔记
2D-slam 激光slam: 开源代码的比较HectorSLAM Gmapping KartoSLAM CoreSLAM LagoSLAM
作者:kint_zhao
原文:https://blog.csdn.net/zyh821351004/article/details/47381135
最近找到一篇论文比较了一下 目前ros下2D激光slam的开源代码效果比较:
详细参见论文: An evaluation of 2D SLAM techniques available in robot operating system
1. 算法介绍
A . HectorSLAM
scan-matching(Gaussian-Newton equation) + 传感器的要求高
要求: 高更新频率小测量噪声的激光扫描仪. 不需要里程计,使空中无人机与地面小车在不平坦区域运行存在运用的可能性.
利用已经获得的地图对激光束点阵进行优化, 估计激光点在地图的表示,和占据网格的概率.
其中扫描匹配利用的是高斯牛顿的方法进行求解. 找到激光点集映射到已有地图的刚体转换(x,y,theta).
( 接触的匹配的方法还有最近邻匹配的方法(ICP) ,gmapping代码中的scanmatcher部分有两种方法选择. )
为避免局部最小而非全局最优的(类似于多峰值模型的,局部梯度最小了,但非全局最优)出现,地图采用多分辨率的形式.
导航中的状态估计可以加入惯性测量,进行EKF滤波.
B. Gmapping: tutorial
proposed by Grisetti et al. and is a Rao-Blackwellized PF SLAM approach.
adaptive resampling technique
目前激光2Dslam用得最广的方法,gmapping采用的是RBPF的方法. 必须得了解粒子滤波(利用统计特性描述物理表达式下的结果)的方法.
粒子滤波的方法一般需要大量的粒子来获取好的结果,但这必会引入计算的复杂度;粒子是一个依据过程的观测逐渐更新权重与收敛的过程,这种重采样的过程必然会代入粒子耗散问题(depletion problem), 大权重粒子显著,小权重粒子会消失(有可能正确的粒子模拟可能在中间的阶段表现权重小而消失).
自适应重采样技术引入减少了粒子耗散问题 , 计算粒子分布的时候不单单仅依靠机器人的运动(里程计),同时将当前观测考虑进去, 减少了机器人位置在粒子滤波步骤中的不确定性. (FAST-SLAM 2.0 的思想,可以适当减少粒子数)
C. KartoSLAM
graph-based SLAM approach developed bySRI International’s Karto Robotics
highly-optimized and non iterative Cholesky matrix decomposition for sparse linear systems as its solver
the Sparse Pose Adjustment (SPA) is responsible for both scan matching and loop-closure procedures
Karto Open Libraries 2.0 SDK(Karto Open Libraries 2.0 is available under the LGPL open source license. You can try the full Karto SDK 2.1 for 30 days.) 后面在详细研究下(比较下MRPT )
图优化的核心思想我认为主要就是 矩阵的稀疏化与最小二乘..参见graphslam学习
KartoSLAM是基于图优化的方法,用高度优化和非迭代 cholesky矩阵进行稀疏系统解耦作为解. 图优化方法利用图的均值表示地图,每个节点表示机器人轨迹的一个位置点和传感器测量数据集,箭头的指向的连接表示连续机器人位置点的运动,每个新节点加入,地图就会依据空间中的节点箭头的约束进行计算更新.
KartoSLAM的ROS版本,其中采用的稀疏点调整(the Spare Pose Adjustment(SPA))与扫描匹配和闭环检测相关.landmark越多,内存需求越大,然而图优化方式相比其他方法在大环境下制图优势更大.在某些情况下KartoSLAM更有效,因为他仅包含点的图(robot pose),求得位置后再求map.
D. CoreSLAM
tinySLAM algorithm: two different steps(distance calculation and update of the map
simple and easy
为了简单和容易理解最小化性能损失的一种slam算法.将算法简化为距离计算与地图更新的两个过程, 第一步,每次扫描输入,基于简单的粒子滤波算法计算距离,粒子滤波的匹配器用于激光与地图的匹配,每个滤波器粒子代表机器人可能的位置和相应的概率权重,这些都依赖于之前的迭代计算. 选择好最好的假设分布,即低权重粒子消失,新粒子生成..在更新步骤,扫描得到的线加入地图中,当障碍出现时,围绕障碍点绘制调整点集,而非仅一个孤立点.
E. LagoSLAM
Linear Approximation for Graph Optimization
the optimization process requires no initial guess
基本的图优化slam的方法就是利用最小化非线性非凸代价函数.每次迭代, 解决局部凸近似的初始问题来更新图配置,过程迭代一定次数直到局部最小代价函数达到. (假设起始点经过多次迭代使得局部代价函数最小). LagoSLAM 是线性近似图优化,不需要初始假设. 优化器的方法可以有三种选择 Tree-based netORK Optimizer(TORO), g2o,LAGO
2. 实验结果比较
分别从大小仿真环境和实际环境以及cpu消耗的情况下对算法进行了比较. CartoSLAM 与gampping占很大优势

说明:能力有限,讲得有问题欢迎指正,暂且粗解到这,后面再具体看看对应算法的详细论文介绍,有问题再改...
slam算法的论文几篇
下载:http://download.csdn.net/detail/zyh821351004/8986339
--------------------------------------------------------------------
补:源码工程整理: https://github.com/kintzhao/laser_slam_openSources
---------------------
GMapping原理分析
作者:豆子爱玩
原文:https://blog.csdn.net/liuyanpeng12333/article/details/81946841
概念:
1、Gmapping是基于滤波SLAM框架的常用开源SLAM算法。
2、Gmapping基于RBpf粒子滤波算法,即将定位和建图过程分离,先进行定位再进行建图。
3、Gmapping在RBpf算法上做了两个主要的改进:改进提议分布和选择性重采样。
优缺点:
优点:Gmapping可以实时构建室内地图,在构建小场景地图所需的计算量较小且精度较高。相比Hector SLAM对激光雷达频率要求低、鲁棒性高(Hector 在机器人快速转向时很容易发生错误匹配,建出的地图发生错位,原因主要是优化算法容易陷入局部最小值);而相比Cartographer在构建小场景地图时,Gmapping不需要太多的粒子并且没有回环检测因此计算量小于Cartographer而精度并没有差太多。Gmapping有效利用了车轮里程计信息,这也是Gmapping对激光雷达频率要求低的原因:里程计可以提供机器人的位姿先验。而Hector和Cartographer的设计初衷不是为了解决平面移动机器人定位和建图,Hector主要用于救灾等地面不平坦的情况,因此无法使用里程计。而Cartographer是用于手持激光雷达完成SLAM过程,也就没有里程计可以用。
缺点:随着场景增大所需的粒子增加,因为每个粒子都携带一幅地图,因此在构建大地图时所需内存和计算量都会增加。因此不适合构建大场景地图。并且没有回环检测,因此在回环闭合时可能会造成地图错位,虽然增加粒子数目可以使地图闭合但是以增加计算量和内存为代价。所以不能像Cartographer那样构建大的地图,虽然论文生成几万平米的地图,但实际我们使用中建的地图没有几千平米时就会发生错误。Gmapping和Cartographer一个是基于滤波框架SLAM另一个是基于优化框架的SLAM,两种算法都涉及到时间复杂度和空间复杂度的权衡。Gmapping牺牲空间复杂度保证时间复杂度,这就造成Gmapping不适合构建大场景地图,试想一下你要构建200乘200米的环境地图,栅格分辨率选择5厘米,每个栅格占用一字节内存,那么一个粒子携带的地图就需要16M内存,如果是100个粒子就需要1.6G内存。如果地图变成500乘500米,粒子数为200个,可能电脑就要崩溃了。翻看Cartographer算法,优化相当于地图中只用一个粒子,因此存储空间比较Gmapping会小很多倍,但计算量大,一般的笔记本很难跑出来好的地图,甚至根本就跑不动。优化图需要复杂的矩阵运算,这也是谷歌为什么还有弄个ceres库出来的原因。
问题:
我希望读者可以带着问题去阅读论文,这样才可以真正理解Gmapping中的很多概念。这里问题主要有:
为什么RBpf可以将定位和建图分离;
Gmapping是如何在RBpf的基础改进提议分布的;
为什么要执行选择性重采样;
什么是粒子退化及如何防止粒子退化;
为什么Gmapping严重依赖里程计;
什么是提议分布;
什么是目标分布;
为什么需要提议分布和目标分布;
算法中是如何计算权重;
粒子滤波粒子数和传感器精度的关系;
为什么在有大回环的环境中增加粒子数可以使建出的地图正确闭合;
Gmapping是基于滤波框架的SLAM方法,为什么建图过程中界面上显示的地图在不断调整。
读者如果可以很好地回答这些问题的话就已经明白Gmapping的算法了。
论文:
我先带着读者捋顺论文的结构,在解析论文的过程中回答上面的几个问题。
摘要:
这部分简单解释了Gmapping是基于RBpf。RBpf是一种有效解决同时定位和建图的算法,它将定位和建图分离;并且每一个粒子都携带一幅地图(这也是粒子滤波不适合构建大地图的原因之一)。但PBpf也存在缺点:所用粒子数多和频繁执行重采样(读者可以思考一下什么造成了RBpf需要较多的粒子数,又为什么需要频繁执行重采样)。粒子数多会造成计算量和内存消耗变大;频繁执行重采样会造成粒子退化。因此Gmapping在RBpf的基础上改进提议分布和选择性重采样,从而减少粒子个数和防止粒子退化。改进的提议分布不但考虑运动(里程计)信息还考虑最近的一次观测(激光)信息这样就可以使提议分布的更加精确从而更加接近目标分布。选择性重采样通过设定阈值,只有在粒子权重变化超过阈值时才执行重采样从而大大减少重采样的次数。
这里可以回答第一个问题了:为什么RBpf可以先定位后建图?
这里我们用公式来描述一下SLAM的过程:,这是一个条件联合概率分布,我们有观测和运动控制的数据来同时推测位姿和地图。由概率论可知联合概率可以转换成条件概率即:P(x,y) = p(y|x)p(x)。 通俗点解释就是我们在同时求两个变量的联合分布不好求时可以先求其中一个变量再将这个变量当做条件求解另一个变量。这就是解释了Gmapping为什么要先定位再建图:同时定位和建图是比较困难的,因此我们可以先求解位姿,已知位姿的建图是一件很容易的事情。
第一章 简介:
SLAM是一个鸡生蛋、蛋生鸡的问题。定位需要建图,建图需要先定位,这就造成SLAM问题的困难所在。因此RBpf被引入解决SLAM问题,即先定位再建图。RBpf的主要问题在于其复杂度高,因为需要较多的粒子来构建地图并频繁执行重采样。我们已知粒子数和计算量内存消耗息息相关,粒子数目较大会造成算法复杂度增高。因此减少粒子数是RBpf算法改进的方向之一;同时由于RBpf频繁执行重采样会造成粒子退化。因此减少重采样次数是RBpf算法的另一个改进方向。
这里回答一下什么是粒子退化:
粒子退化主要指正确的粒子被丢弃和粒子多样性减小,而频繁重采样则加剧了正确的粒子被丢弃的可能性和粒子多样性减小速率。这里先涉及一下重采样的知识,我们知道在执行重采样之前会计算每个粒子数的权重,有时会因为环境相似度高或是由于测量噪声的影响会使接近正确状态的粒子数权重较小而错误状态的粒子的权重反而会大。重采样是依据粒子权重来重新采粒子的,这样正确的粒子就很有可能会被丢弃,频繁的重采样更加剧了正确但权重较小粒子被丢弃的可能性。这也就是粒子退化原因之一。
另外一个原因就是频繁重采样导致的粒子多样性减小的速率加大,什么是粒子多样性呢?就是粒子的不同,就像最开始有十个粒子,如果发生重采样后其中有五个粒子被丢弃,剩下的五个粒子复制出五个粒子,这时十个粒子中只有五个粒子是不同的也就是粒子多样性减小。再通俗点解释,比如兔子生兔子这个问题。我们的笼子只能装十个兔子,所以在任意时刻我们只能有十只兔子,但兔子是会繁殖的,那么怎么办呢?索性把长的不好看的兔子干掉(这里的好看就是粒子权重,好看的权重就高不好看的权重就低,哈哈作者就是这么任性)。让好看的兔子多生一只补充干掉的兔子。我们假设兔子一月繁殖一回,这样的话在多年后这些兔子可能就都是一个兔子的后代。就是说兔子们的DNA都是一样的了,也就是兔子DNA的多样性减小。为什么频繁执行重采样会使粒子多样性减小呢,这就好比我兔子一月繁殖一会我可能五年后这些兔子的才会共有一个祖先。但如果让兔子一天繁殖一会呢?可能一个月后这些兔子就全是最开始一只兔子的后代了,兔子们的DNA就成一样了。因此为了防止粒子退化就要减少重采样的次数。
回到论文,为了减小粒子数Gmapping提出了改进提议分布,为了减少重采样的次数Gmapping提出了选择性重采样。现在问题到了如何改进提议分布了,先简单说一下后面会有详细介绍。就以下图为例,图中虚线为p(x|x’,u)的概率分布也就是我们里程计采样的高斯分布,这里只是一维的情况。实线为p(z|x)的概率分布也就是使用激光进行观测后获得状态的高斯分布。由图可知观测提供的信息的准确度(方差小)相比控制的准确度要高的很多。这就是Gmapping改进提议分布的动因。但问题是我们无法对观测建模,这就造成了我们想用观测但是呢观测的模型又无法直接获得,后面论文中改进提议分布就是围绕如何利用最近的一次观测来模拟目标分布。
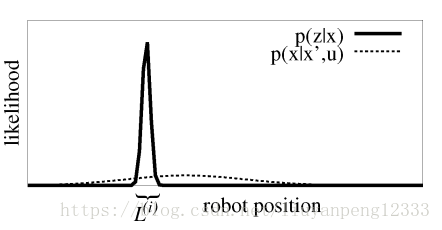
第二章 使用RBpf建图:
这节主要讲RBpf建图的过程,首先RBpf是个什么东西?SALM要解决的问题就是有控制数据u1:t和观测数据z1:t来求位姿和 地图的联合分布。问题是这两个东西在一起并不太好求,怎么办使用条件概率把它俩给拆开先来求解位姿,我们知道有了位姿后建图是一件很容易的事情。这就是RB要做的事情:先进行定位在进行建图。公式就变成了下面的形式:

为了估计位姿,RBpf使用粒子滤波来估计机器人位姿,而粒子滤波中最常用的是重要性重采样算法。这个算法通过不断迭代来估计每一时刻机器人的位姿。算法总共包括四个步骤:采样- 计算权重-重采样-地图估计。这些没什么好讲的看论文就会明白。
这里读者可能对论文中的权重计算的迭代公式不太清楚,这里我贴一张我注释过的公式图片

下面会用到提议分布和目标分布的知识,这里我先回答一下什么是提议分布和目标分布以及为什么需要这两个概念?
目标分布:什么是目标分布,就是我根据机器人携带的所有传感器的数据能确定机器人状态置信度的最大极限。我们知道机器人是不能直接进行测量的,它是靠自身携带的传感器来获得对自身状态的估计。比如说我们想要估计机器人的位姿,而机器人只有车轮编码器和激光雷达,两者的数据结合就会形成机器人位姿估计,由于传感器是有噪声的,所以估计的机器人位姿就会有一个不确定度,而这个不确定度是机器人对当前位姿确定性的最大极限,因为我没有数据信息来对机器人的状态进行约束了。机器人位姿变量通常由高斯函数来表示,不确定度就对应变量的方差。
提议分布:为什么要有提议分布?有人会说有了目标分布为什么还要有提议分布进行采样来获取下一时刻机器人位姿信息。答案是没有办法直接对目标分布建模进行采样。知道里程计模型的都明白里程计模型是假设里程计三个参数是服从高斯分布的,因此我们可以从高斯分布中采样出下一时刻即日起的位姿。但对于激光观测是无法进行高斯建模的,这样是激光SLAM使用粒子滤波而不用扩展卡尔曼滤波的原因之一。为什么呢?我们知道基于特征的SLAM算法经常会用扩展卡尔曼,因为基于特征的地图进行观测会返回机器人距离特征的 一个距离和角度值,这时很容易对观测进行高斯建模然后使用扩展卡尔曼进行滤波。而激光的返回的数据是360点的位置信息,每个位置信息都包括一个距离和角度信息,要是对360个点进行高斯建模计算量不言而喻。 但问题是我们希望从一个分布中进行采样来获取对下一时刻机器人位姿的估计,而在计算机中能模拟出的分布也就是高斯分布、三角分布等有限的分布。因此提议分布被提出来代替目标分布来提取下一时刻机器人位姿信息。而提议分布毕竟不是目标分布因此使用粒子权重来表征提议分布和目标分布的不一致性。
第三章 在RBpf的基础上改进提议分布和选择性重采样
主要是围绕如何改进提议分布和选择性重采样展开的。
我们知道我们需要从提议分布中采样得到下一时刻机器人的位姿。那么提议分布与目标分布越接近的话我们用的粒子越少,如果粒子是直接从目标分布采样的话只需要一个粒子就可以获得机器人的位姿估计了。因此我们要做的是改进提议分布,如果我们只从里程计中采样的话粒子的权重迭代公式就成了:

但是由第一幅图片我们可知里程计提供位姿信息的不确定度要比激光大的多,我们知道激光的分布相比里程计分布更接近真正的目标分布,因此如果可以把激光的信息融入到提议分布中的话那样提议分布就会更接近目标分布。文章中说激光的精度相比里程计准确的多,因此使用里程计作为提议分布是次优的。
同时因为粒子要覆盖里程计状态的全部空间,而这其中只有一小部分粒子是正真符合目标分布的,因此在计算权重时粒子的权重变化就会很大。但我们只有有限的粒子来模拟状态分布,因此我们需要把权重小的粒子丢弃,让权重大的粒子复制以达到使粒子收敛到真实状态附近。但这就造成需要频繁重采样,也就造成了RBpf的另一个弊端即:发生粒子退化。这里就解释了RBpf需要大量粒子并执行频繁重采样。
为了改进提议分布,论文中使用最近的一次观测,因此提议分布变成了:

接下来粒子的权重公式变成了:
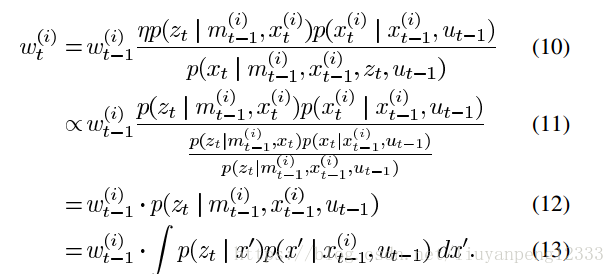
接下来就是到了如何高效计算提议分布,我们知道当用栅格地图表征环境时,准确目标分布的近似形式是没有办法获得的由于观测的概率分布不可获得(原因在前面讲过就是激光360根线我们没法直接建模)。但是我们可以采用采样的思想,我们可以采样来模拟出提议分布。
为了获得改进的提议分布,我们可以第一步从运动模型采集粒子,第二步使用观测对这些粒子加权以选出最好的粒子。然后用这些权重大粒子来模拟出改进后的提议分布。但是如果观测概率比较尖锐则需要更多的粒子数目以能够覆盖观测概率。这样就导致了和从里程计中采样相同的问题。计算量太大。
目标分布通常只有几个峰值并在大多数情况下只有一个峰值。因此我们可以直接从峰值附近采样的话就可以大大简化计算量。因此论文中在峰值附近采K个值来模拟出提议分布。首先使用扫描匹配找出概率大的区域然后进行采样。我们通常使用高斯函数来构建提议分布,因此有了K个数据后我们就可以模拟出一个高斯函数作为提议分布:
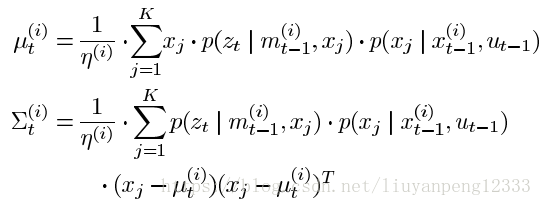
有了模拟好的提议分布我们就可以采样出下一时刻机器人的位姿信息。
这里还有一个问题就是权重计算,我们知道权重描述的是目标分布和提议分布之间的差别。因此我们在计算权重时就是计算我们模拟出的提议分布和目标分布的不同。而这种不同体现在我们是由有限的采样模拟出目标分布,因此权重的计算公式为:
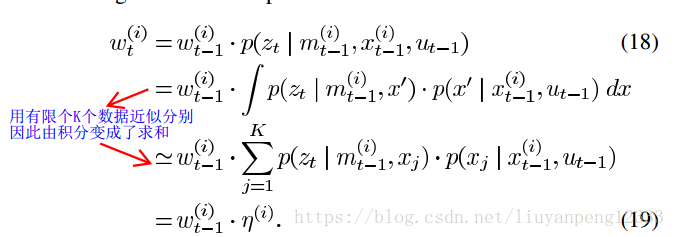
到此改进提议分布就完成了,接下来是选择性重采样。这部分比较简单,就是设定一个阈值,当粒子的权重变化大于我们设定的阈值时就会执行重采样,这样减少了采样的次数,也就减缓了粒子退化。至此理论部分就讲完了!
---------------------
[SLAM] GMapping SLAM源码阅读(草稿)
作者:太一吾鱼水
原文:http://www.cnblogs.com/yhlx125/p/5634128.html
目前可以从很多地方得到RBPF的代码,主要看的是Cyrill Stachniss的代码,据此进行理解。
Author:Giorgio Grisetti; Cyrill Stachniss http://openslam.org/
https://github.com/Allopart/rbpf-gmapping 和文献[1]上结合的比较好,方法都可以找到对应的原理。
https://github.com/MRPT/mrpt MRPT中可以采用多种扫描匹配的方式,可以通过配置文件进行配置。
双线程和程序的基本执行流程
GMapping采用GridSlamProcessorThread后台线程进行数据的读取和运算,在gsp_thread.h和相应的实现文件gsp_thread.cpp中可以看到初始化,参数配置,扫描数据读取等方法。
最关键的流程是在后台线程调用的方法void * GridSlamProcessorThread::fastslamthread(GridSlamProcessorThread* gpt)
而这个方法中最主要的处理扫描数据的过程在428行,bool processed=gpt->processScan(*rr);同时可以看到GMapping支持在线和离线两种模式。
注意到struct GridSlamProcessorThread : public GridSlamProcessor ,这个后台线程执行类GridSlamProcessorThread 继承自GridSlamProcessor,所以执行的是GridSlamProcessor的processScan方法。
GridSlamProcessor::processScan
可以依次看到下面介绍的1-7部分的内容。
1.运动模型
t时刻粒子的位姿最初由运动模型进行更新。在初始值的基础上增加高斯采样的noisypoint,参考MotionModel::drawFromMotion()方法。原理参考文献[1]5.4.1节,sample_motion_model_odometry算法。
p是粒子的t-1时刻的位姿,pnew是当前t时刻的里程计读数,pold是t-1时刻的里程计读数。参考博客:小豆包的学习之旅:里程计运动模型

1 OrientedPoint MotionModel::drawFromMotion(const OrientedPoint& p, const OrientedPoint& pnew, const OrientedPoint& pold) const{
2 double sxy=0.3*srr;
3 OrientedPoint delta=absoluteDifference(pnew, pold);
4 OrientedPoint noisypoint(delta);
5 noisypoint.x+=sampleGaussian(srr*fabs(delta.x)+str*fabs(delta.theta)+sxy*fabs(delta.y));
6 noisypoint.y+=sampleGaussian(srr*fabs(delta.y)+str*fabs(delta.theta)+sxy*fabs(delta.x));
7 noisypoint.theta+=sampleGaussian(stt*fabs(delta.theta)+srt*sqrt(delta.x*delta.x+delta.y*delta.y));
8 noisypoint.theta=fmod(noisypoint.theta, 2*M_PI);
9 if (noisypoint.theta>M_PI)
10 noisypoint.theta-=2*M_PI;
11 return absoluteSum(p,noisypoint);
12 }
2.扫描匹配
扫描匹配获取最优的采样粒子。GMapping默认采用30个采样粒子。
注意ScanMatcher::score()函数的原理是likehood_field_range_finder_model方法,参考《概率机器人》手稿P143页。
ScanMatcher::optimize()方法获得了一个最优的粒子,基本流程是按照预先设定的步长不断移动粒子的位置,根据提议分布计算s,得到score最小的那个作为粒子的新的位姿。
ScanMatcher::likelihoodAndScore()和ScanMatcher::score()方法基本一致,但是是将新获得的粒子位姿进行计算q,为后续的权重计算做了准备。
ScanMatcher::optimize()方法——粒子的运动+score()中激光扫描观测数据。
其他的扫描匹配方法也是可以使用的:比如ICP算法(rbpf-gmapping的使用的是ICP方法,先更新了旋转角度,然后采用提议分布再次优化粒子)、Cross Correlation、线特征等等。
3.提议分布 (Proposal distribution)
注意是混合了运动模型和观测的提议分布,将扫描观测值整合到了提议分布中[2](公式9)。因此均值和方差的计算与单纯使用运动模型作为提议分布的有所区别。提议分布的作用是获得一个最优的粒子,同时用来计算权重,这个体现在ScanMatcher::likelihoodAndScore()和ScanMatcher::score()方法中,score方法中采用的是服从0均值的高斯分布近似提议分布(文献[1] III.B节)。关于为什么采用混合的提议分布,L(i)区域小的原理在文献[1]中III.A节有具体介绍。
rbpf-gmapping的使用的是运动模型作为提议分布。
4.权重计算
在重采样之前进行了一次权重计算updateTreeWeights(false);
重采样之后又进行了一次。代码在gridslamprocessor_tree.cpp文件中。
1 void GridSlamProcessor::updateTreeWeights(bool weightsAlreadyNormalized)
2 {
3 if (!weightsAlreadyNormalized)
4 {
5 normalize();
6 }
7 resetTree();
8 propagateWeights();
9 }
5.重采样
原理:粒子集对目标分布的近似越差,则权重的方差越大。
因此用Neff作为权重值离差的量度。
6.占用概率栅格地图
此处的方法感觉有点奇怪,在resample方法中执行ScanMatcher::registerScan()方法,计算占用概率栅格地图。采样两种方式,采用信息熵的方式和文献[1] 9.2节的计算方法不一样。
rbpf-gmapping的使用的是文献[1] 9.2节的计算方法,在Occupancy_Grid_Mapping.m文件中实现,同时调用Inverse_Range_Sensor_Model方法。
gridlineTraversal实现了beam转成栅格的线。对每一束激光束,设start为该激光束起点,end为激光束端点(障碍物位置),使用Bresenham划线算法确定激光束经过的格网。
7.计算有效区域
第一次扫描,count==0时,如果激光观测数据超出了范围,更新栅格地图的范围。同时确定有效区域。
每次扫描匹配获取t时刻的最优粒子后会计算有效区域。
重采样之后,调用ScanMatcher::registerScan() 方法,也会重新计算有效区域。
参考文献:
[1]Sebastian Thrun et al. "Probabilistic Robotics(手稿)."
[2]Grisetti, G. and C. Stachniss "Improved Techniques for Grid Mapping with Rao-Blackwellized Particle Filters."
---------------------
[SLAM]2D激光扫描匹配方法
作者:太一吾鱼水
原文:http://www.cnblogs.com/yhlx125/p/5586499.html
1.Beam Model
Beam Model我将它叫做测量光束模型。个人理解,它是一种完全的物理模型,只针对激光发出的测量光束建模。将一次测量误差分解为四个误差。
ph hit phhit ,测量本身产生的误差,符合高斯分布。
ph xx phxx ,由于存在运动物体产生的误差。
...
2.Likehood field
似然场模型,和测量光束模型相比,考虑了地图的因素。不再是对激光的扫描线物理建模,而是考虑测量到的物体的因素。
似然比模型本身是一个传感器观测模型,之所以可以实现扫描匹配,是通过划分栅格,步进的方式求的最大的Score,将此作为最佳的位姿。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
for k=1:size(zt,1) if zt(k,2)>0 d = -grid_dim/2; else d = grid_dim/2; end phi = pi_to_pi(zt(k,2) + x(3)); if zt(k,1) ~= Z_max ppx = [x(1),x(1) + zt(k,1)*cos(phi) + d]; ppy = [x(2),x(2) + zt(k,1)*sin(phi) + d]; end_points = [end_points;ppx(2),ppy(2)]; wm = likelihood_field_range_finder_model(X(j,:)',xsensor,... zt(k,:)',nearest_wall, grid_dim, std_hit,Z_weights,Z_max); W(j) = W(j) * wm; else dist = Z_max + std_hit*randn(1); ppx = [x(1),x(1) + dist*cos(phi) + d]; ppy = [x(2),x(2) + dist*sin(phi) + d]; missed_points = [missed_points;ppx(2),ppy(2)]; end set(handle_sensor_ray(k),'XData', ppx, 'YData', ppy)end |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
function q = likelihood_field_range_finder_model(X,x_sensor,zt,N,dim,std_hit,Zw,z_max)% retorna probabilidad de medida range finder :)% X col, zt col, xsen col[n,m] = size(N);% Robot global position and orientationtheta = X(3);% Beam global angletheta_sen = zt(2);phi = pi_to_pi(theta + theta_sen);%Tranf matrix in case sensor has relative position respecto to robot's CGrotS = [cos(theta),-sin(theta);sin(theta),cos(theta)];% Prob. distros parameterssigmaR = std_hit;zhit = Zw(1);zrand = Zw(2);zmax = Zw(3);% Actual algoq = 1;if zt(1) ~= z_max % get global pos of end point of measument xz = X(1:2) + rotS*x_sensor + zt(1)*[cos(phi); sin(phi)]; xi = floor(xz(1)/dim) + 1; yi = floor(xz(2)/dim) + 1; % if end point doesn't lay inside map: unknown if xi<1 || xi>n || yi<1 || yi>m q = 1.0/z_max; % all measurements equally likely, uniform in range [0-zmax] return end dist2 = N(xi,yi); gd = gauss_1D(0,sigmaR,dist2); q = zhit*gd + zrand/zmax;endend |
3.Correlation based sensor models相关分析模型
XX提出了一种用相关函数表达马尔科夫过程的扫描匹配方法。
互相关方法Cross-Correlation,另外相关分析在进行匹配时也可以应用,比如对角度直方图进行互相关分析,计算变换矩阵。
参考文献:A Map Based On Laser scans without geometric interpretation
circular Cross-Correlation的Matlab实现
1 % Computes the circular cross-correlation between two sequences
2 %
3 % a,b the two sequences
4 % normalize if true, normalize in [0,1]
5 %
6 function c = circularCrossCorrelation(a,b,normalize)
7
8 for k=1:length(a)
9 c(k)=a*b';
10 b=[b(end),b(1:end-1)]; % circular shift
11 end
12
13 if normalize
14 minimum = min(c);
15 maximum = max(c);
16 c = (c - minimum) / (maximum-minimum);
17 end
4.MCL
蒙特卡洛方法
5.AngleHistogram
角度直方图
6.ICP/PLICP/MBICP/IDL
属于ICP系列,经典ICP方法,点到线距离ICP,
7.NDT
正态分布变换
8.pIC
结合概率的方法
9.线特征
目前应用线段进行匹配的试验始终不理想:因为线对应容易产生错误,而且累积误差似乎也很明显!
---------------------
slam-gmapping之scanMatch算法原理
原文:https://blog.csdn.net/m0_37350344/article/details/81159413
Scan Matching
问题描述:给定Scan和map,或者给定scan和scan或者给定map和map,找到最匹配的变换(translation+rotation)
作用:提高提议分布
方法:
p(z|x,m)= beam sonsor model sensor full readings <-> map
p(z|x,m)= likelihood field model sensor beam endpoints <-> likelihood field
p(mlocal|x,m)=matching model local map<->global map
Beam sensor Model
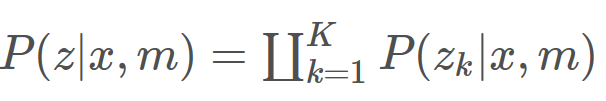
噪声原因 :较小的测量噪声、动态物体带来的误差、未探测到物体带来的误差(没有探测到物体时将使用测距仪的最大测程作为测量数据,因此也有可能不正确)、随机误差。
(1)测量噪声:由测距仪的精度、大气对测量信号的影响等造成,其概率模型一般是以理想测量距离为均值的高斯模型
(2)动态物体误差:由未预测到的物体(Unexpected objects)带来的误差。环境是动态的,而保存的地图是静态的,即不变的。没有包含在地图里的物体的出现会产生一个令人意外的比较小的测量数据。典型的动态物体就是行人。处理这些误差的一种方法就是把它当成传感器噪声。测量到的距离越大,检测到动态物体的概率越小,且小距离对应的测量到的是动态物体的概率应远大于大距离的概率,随意概率随距离的增大呈指数下降趋势,所以其概率模型为指数分布
(3)随机误差:测距仪偶尔会产生一些无法解释的测量结果。
(4)测量失败:有时候,传感器探测不到障碍物,比如试图探测一些吸收光线的物体,此时的探测数据将失效。典型的探测结果就是传感器返回自身的最大探测距离。概率模型表示为:(应该就是两点分布,即失败与没有失败)
根据实际数据得到参数
Likelihood Field Model

+ 该方法的缺点
+ 没有对人或者其他动态的障碍物建模
+ 没有对激光束建模,认为传感器可以穿过墙
+ 不能处理未知区域 (改进 若end_point 在未知区域P(z|x,m)=1/z max P(z|x,m)=1/zmaxP(z|x,m)=1/z_{max})
+ P(z|x,m) P(z|x,m)P(z|x,m)对应于似然区域得分
+ slam工程中
激光传感器的作用主要是感知周围环境,获取的扫描数据在SLAM过程中有两个作用:一是构建地图(占用概率栅格地图);另外一个是扫描匹配,优化里程计获取的机器人位姿,扫描匹配是建立局部子图和全局地图位置关系的过程,常用到的就是传感器观测模型。
scanMatch
2D激光扫描匹配方法
ScanMatching 实现机器人位姿估计
matlab程序实现
transform = matchScans(currentScan, referenceScan)//计算相对位姿
transScan = transformScan(currentScan, transform);//转为可视化结果
---
使用迭代算法建立栅格地图1234
---------------------
作者:Tomas_yuan
来源:CSDN
原文:https://blog.csdn.net/m0_37350344/article/details/81159413
版权声明:本文为博主原创文章,转载请附上博文链接!
Gmapping笔记的更多相关文章
- Learning ROS for Robotics Programming Second Edition学习笔记(三) indigo rplidar rviz slam
中文译著已经出版,详情请参考:http://blog.csdn.net/ZhangRelay/article/category/6506865 Learning ROS for Robotics Pr ...
- ROS进阶学习笔记(11)- Turtlebot Navigation and SLAM - ROSMapModify - ROS地图修改
ROS进阶学习笔记(11)- Turtlebot Navigation and SLAM - 2 - MapModify地图修改 We can use gmapping model to genera ...
- git-简单流程(学习笔记)
这是阅读廖雪峰的官方网站的笔记,用于自己以后回看 1.进入项目文件夹 初始化一个Git仓库,使用git init命令. 添加文件到Git仓库,分两步: 第一步,使用命令git add <file ...
- js学习笔记:webpack基础入门(一)
之前听说过webpack,今天想正式的接触一下,先跟着webpack的官方用户指南走: 在这里有: 如何安装webpack 如何使用webpack 如何使用loader 如何使用webpack的开发者 ...
- SQL Server技术内幕笔记合集
SQL Server技术内幕笔记合集 发这一篇文章主要是方便大家找到我的笔记入口,方便大家o(∩_∩)o Microsoft SQL Server 6.5 技术内幕 笔记http://www.cnbl ...
- PHP-自定义模板-学习笔记
1. 开始 这几天,看了李炎恢老师的<PHP第二季度视频>中的“章节7:创建TPL自定义模板”,做一个学习笔记,通过绘制架构图.UML类图和思维导图,来对加深理解. 2. 整体架构图 ...
- PHP-会员登录与注册例子解析-学习笔记
1.开始 最近开始学习李炎恢老师的<PHP第二季度视频>中的“章节5:使用OOP注册会员”,做一个学习笔记,通过绘制基本页面流程和UML类图,来对加深理解. 2.基本页面流程 3.通过UM ...
- NET Core-学习笔记(三)
这里将要和大家分享的是学习总结第三篇:首先感慨一下这周跟随netcore官网学习是遇到的一些问题: a.官网的英文版教程使用的部分nuget包和我当时安装的最新包版本不一致,所以没法按照教材上给出的列 ...
- springMVC学习笔记--知识点总结1
以下是学习springmvc框架时的笔记整理: 结果跳转方式 1.设置ModelAndView,根据view的名称,和视图渲染器跳转到指定的页面. 比如jsp的视图渲染器是如下配置的: <!-- ...
随机推荐
- Android开发 android沉浸式状态栏的适配(包含刘海屏)转载
原文地址:https://blog.csdn.net/liup1211/article/details/86583015 写在前面: 1,本文阐述如何实现沉浸式状态栏 2,部分代码有从其他博客摘抄,也 ...
- Android开发 Context详解与类型 转载
转载地址:https://blog.csdn.net/guolin_blog/article/details/47028975 个人总结: Context分为 activity : activity其 ...
- lvs+keepalived+ipvsadm 完整搭建笔记
原文:http://www.safecdn.cn/2018/12/lvs-keepalived-ipvsadm/ 1.环境介绍: 系统:centos 6.7 keepalived VIP1 :10.0 ...
- oracle 的tnsnames.ora,listener.ora
x:\app\Administrator\product\11.2.0\dbhome_1\NETWORK\ADMIN listener.ora: # listener.ora Network Conf ...
- python-day3集合、文件读写、函数
@集合运算 s.union(t) s | t 返回一个新的 set 包含 s 和 t 中的每一个元素 s.intersection(t) s & t 返回一个新的 set 包含 s 和 t 中 ...
- 深入理解Java虚拟机读书笔记2----垃圾收集器与内存分配策略
二 垃圾收集器与内存分配策略 1 JVM中哪些内存需要回收? JVM垃圾回收主要关注的是Java堆和方法区这两个区域:而程序计数器.虚拟机栈.本地方法栈这3个区域随线程而生,随线程而灭,随着方 ...
- C++builder Tokyo 调用com 不正确的变量类型
C++builder Tokyo 调用com 不正确的变量类型 tt.OleFunction("interface_call","MS01",&erro ...
- Rocket MQ 2 - Namesrv
通过上文中使用可以看到,主要逻辑还是在NamesrvController中包含KVConfigManager负责配置相关的读写,RouteInfoManager负责路由信息的管理; 启动定时任务定时打 ...
- 自学PHP的正确方法与经验
我是2015年开始接触认识到PHP编程方面的知识,2012年我还是一名刚毕业的大学生开始踏入社会从事自己一份学校推荐的自动化职业,自动化工作枯燥无味,每天基本上3点一线,食堂-公司机器-宿舍,做了3年 ...
- python的socke编程
python的sock编程分为TCP编程和UDP编程,两者不同在于,TCP需要首先建立连接才能发送接收数据,而UDP则可以直接发送接收不需要预先建立连接. tcp编程,我总结为4步 TCP的serve ...