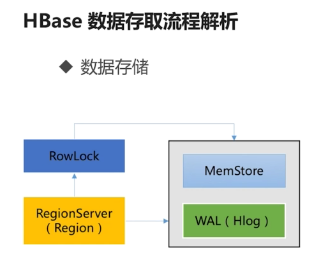
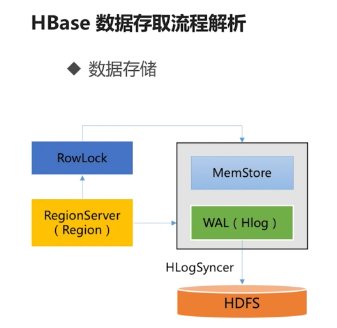
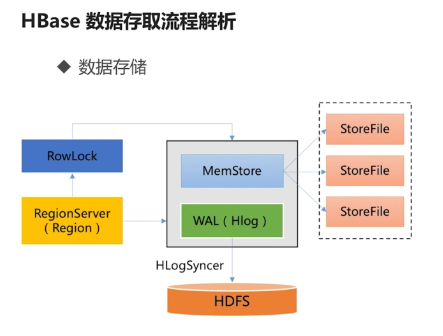
Hbase存储流程
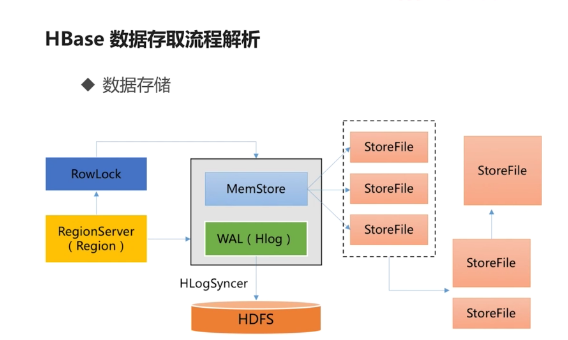
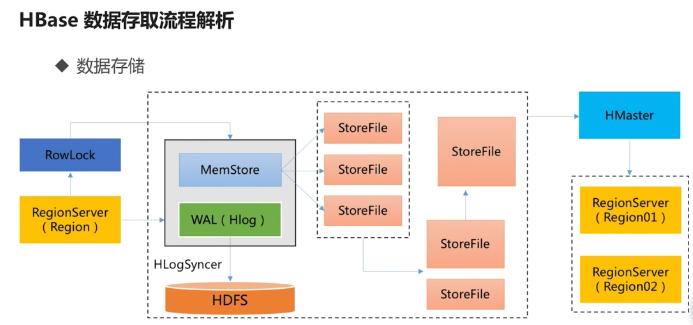
Hbase存储流程的更多相关文章
- hbase读写流程
一. Hbase读流程 META表记录着表的原信息,根据rowkey查询META表,获取所在region信息 客户端去相应的regionServer查询数据,先查询memStore(memstore是 ...
- HBase Scan流程分析
HBase Scan流程分析 HBase的读流程目前看来比较复杂,主要由于: HBase的表数据分为多个层次,HRegion->HStore->[HFile,HFile,...,MemSt ...
- Hbase存储详解
转自:http://my.oschina.net/mkh/blog/349866 Hbase存储详解 started by chad walters and jim 2006.11 G release ...
- HBase存储及读写原理介绍
一.HBase介绍及其特点 HBase是一个开源的非关系型分布式数据库,它参考了谷歌的BigTable建模,实现的编程语言为Java.它是Apache软件基金会的Hadoop项目的一部分,运行于HDF ...
- 8.hbase写入流程和读取流程
1 hbase写入流程 hbase中无论是新增数据还是修改已有行,其内部流程都是一样的,hbase执行写入时会写到两个地方,write-ahead log 简称wal 也叫hlog 预写式日志 和 M ...
- 用Hbase存储Log4j日志数据:HbaseAppender
业务需求: 需求很简单,就是把多个系统的日志数据统一存储到Hbase数据库中,方便统一查看和监控. 解决思路: 写针对Hbase存储的Log4j Appender,有一个简单的日志储存策略,把Log4 ...
- HBase存储剖析与数据迁移
1.概述 HBase的存储结构和关系型数据库不一样,HBase面向半结构化数据进行存储.所以,对于结构化的SQL语言查询,HBase自身并没有接口支持.在大数据应用中,虽然也有SQL查询引擎可以查询H ...
- hbase 存储结构和原理
HBase的表结构 建表时要指定的是:表名.列族 建表语句 create 'user_info', 'base_info', 'ext_info' 意思是新建一个表,名称是user_info,包含两个 ...
- HBase存储架构
以下的介绍是基于Apache Hbase 0.94版本: 从HBase的架构图上可以看出,HBase中的存储包括HMaster.HRegionServer.HRegion.Store.MemStore ...
随机推荐
- 11g SPA (sql Performance Analyze) 进行升级测试
注;转自http://ju.outofmemory.cn/entry/77139 11G的新特性SPA(SQL Performance Analyze)现在被广泛的应用到升级和迁移的场景.当然还有一些 ...
- Python:Day29 信号量、条件变量
信号量:semaphore 信号量是用来控制线程并发数的.(理解:虽然GIL任意时刻都只有一个线程被执行,但是所有线程都有资格去抢,semaphore就是用来控制抢的GIL的数量,只有获取了semap ...
- 001_python单元测试
一.同事推荐的 pytest库 ==> 官网:http://doc.pytest.org/en/latest/ github地址==>https://github.com/pytest-d ...
- 从零开始搭建django前后端分离项目 系列六(实战之聚类分析)
项目需求 本项目从impala获取到的数据为用户地理位置数据,每小时的数据量大概在8000万条,数据格式如下: 公司要求对这些用户按照聚集程度进行划分,将300米范围内用户数大于200的用户划分为一个 ...
- [翻译] ASP.NET Core 利用 Docker、ElasticSearch、Kibana 来记录日志
原文: Logging with ElasticSearch, Kibana, ASP.NET Core and Docker 一步一步指导您使用 ElasticSearch, Kibana, ASP ...
- 【Python入门只需20分钟】从安装到数据抓取、存储原来这么简单
基于大众对Python的大肆吹捧和赞赏,作为一名Java从业人员,我本着批判与好奇的心态买了本python方面的书<毫无障碍学Python>.仅仅看了书前面一小部分的我......决定做一 ...
- Django ORM模型:想说爱你不容易
作者:Vamei 出处:http://www.cnblogs.com/vamei 严禁转载. 使用Python的Django模型的话,一般都会用它自带的ORM(Object-relational ma ...
- 设置placeholder无效解决办法
一.设置placeholder的方法 placeholder属性用来设置控件内部的提示信息 <input type="text" placeholder="请输入用 ...
- Class AtomicInteger
Overview Package Class Use Tree Deprecated Index Help Java™ PlatformStandard Ed. 7 Prev Class Next C ...
- matplot绘图基本使用
先看一个最简单的例子 import matplotlib.pyplot as plt plt.figure() plt.subplot(211) plt.plot([1,2,3], color=''r ...