Selenium简单回顾
一.Selenium介绍
1.Selenium(浏览器自动化测试框架):
Selenium 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
2.Selenium框架图:
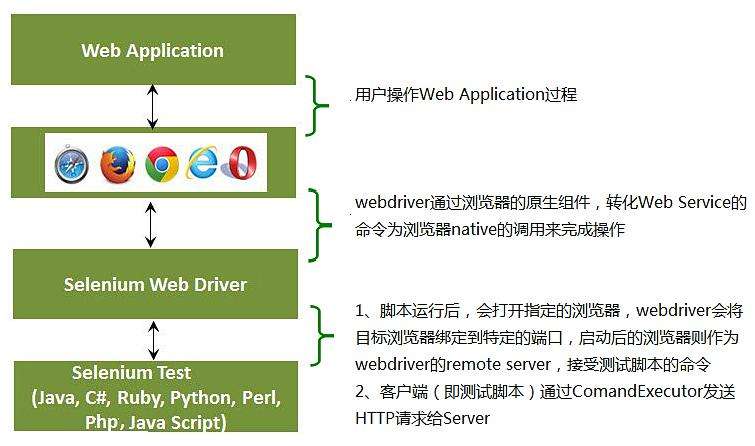
二.Selenium的安装和简单使用:
1.安装:(官方文档:https://selenium-python.readthedocs.io/api.html)
2.浏览器的安装(若没在环境变量中,请下载):

3.简单使用Selenium:
3.1简单获取百度网页并退出(会弹出浏览器模拟操作):
from selenium import webdriver
from scrapy.selector import Selector
# 打开谷歌浏览器
# 若没将浏览器Chrome的exe文件添加到PATH下,则带参数指定浏览exe文件的位置
# brower=webdriver.Chrome(executable_path='....')
# 添加在PATH下自动找取
brower = webdriver.Chrome()
# 获取的是js和css文件加载完后的网页,而不是该网页源代码 brower.get('https://www.baidu.com/')
# 获取js和css加载完后的网页
print(brower.page_source)
'''
selenium提供了很多提取网页内容的方法,如下等,但是selenium是用纯python写的,
提取效率慢,若知是提取内容,建议用scrapy,模拟输入密码和点击时用selenium的方法
brower.find_element_by_css_selector()
brower.find_elements_by_css_selector()
......
'''
#利用scrapy的selector解析,速度更快
t_select=Selector(text=brower.page_source)
......
# 退出
brower.quit()
3.2模拟登录微博:
from selenium import webdriver
import urllib browser = webdriver.Chrome()
browser.get('https://weibo.com/')
import time
time.sleep(10)
username = browser.find_element_by_css_selector('#loginname')
passwd=browser.find_element_by_css_selector('input[node-type="password"]')
if username:
username.send_keys('yourphone')
else:
print('未找到用户名输入框!!!标签错误')
if passwd:
passwd.send_keys('yourpasswd')
else:
print('未找到密码输入框!!!标签错误')
yanzhengma=browser.find_element_by_css_selector('.code.W_fl img')
if yanzhengma:
#获取验证码图片下载地址并下载到本地
img_url=yanzhengma.get_attribute('src')
data = urllib.request.urlopen(img_url).read()
f = open('weibo.png' , 'wb')
f.write(data)
f.close()
code_input=browser.find_element_by_css_selector('input[node-type="verifycode"]')
#可以使用打码平台或自动识别验证码
codes=input('请输入截图里的验证码:')
code_input.send_keys(codes)
browser.find_elements_by_css_selector('a[node-type="submitBtn"]')[0].click()
3.3selenium实现页面滚动下拉:
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://www.oschina.net/blog')
#执行js代码,可以设定下拉到底部或某个位置等
for i in range(3):
#下拉三次
browser.execute_script(
"window.scrollTo(0,document.body.scrollHeight); var lenofPage=document.body.scrollHeight; return lenofPage;")
time.sleep(3)
3.4selenium设置不加载图片(加快效率):
from selenium import webdriver
#设置chromedriver不加载图片,加速页面的加载
option=webdriver.ChromeOptions()
prefs={'profile.managed_default_content_settings.images':2}
option.add_experimental_option("prefs",prefs)
browser=webdriver.Chrome(chrome_options=option)
browser.get('https://www.taobao.com/')
3.5phantomjs的简单使用(无界面的浏览器,速率快,但多进程情况下性能下降很严重):
注:selenium3.11.0及以上版本不在支持phantomjs,若需使用则要安装旧版的selenium(pip3 uninstall selenium 安装历史版本:pip3 install selenium==3.10.0或更旧的版本)
from selenium import webdriver browser = webdriver.PhantomJS(executable_path='E:/phantomjs-2.1.1-windows/bin/phantomjs.exe')
browser.get('https://www.cnblogs.com/lyq-biu/p/9753969.html')
print(browser.page_source)
3.6selenium集成到scrapy(若要使用,记得在setting中添加到中间件):
注:scrapy本身是异步的,经过这样的selenium集成会变成同步的,会降低速率,若想集成仍是异步的,则需重写downloader。参考:https://github.com/flisky/scrapy-phantomjs-downloader
#第一种
from selenium import webdriver
from scrapy.http import HtmlResponse
class SeleniumMiddleware(object):
#通过selenium请求动态网页
def process_request(self,request,spider):
#spider的名字是jobbole才使用selenium方法
if spider.name=='jobbole':
#请求一次打开一个窗口,很慢
browser=webdriver.Chrome()
browser.get(request.url)
return HtmlResponse(url=request.url,body=browser.page_source)
#第二种
from selenium import webdriver
from scrapy.http import HtmlResponse class SeleniumMiddleware(object):
# 通过selenium请求动态网页
def __init__(self):
#使用一个Chrome,return之后无法关闭,则初始化可以放入spider中,调用spider.close()关闭
self.browser = webdriver.Chrome()
super(SeleniumMiddleware, self).__init__() def process_request(self, request, spider):
if spider.name == 'jobbole':
self.browser.get(request.url)
return HtmlResponse(url=request.url, body=self.browser.page_source)
#第三种
from scrapy.xlib.pydispatch import dispatcher
from scrapy import signals
......
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts'] def __init__(self):
self.browser = webdriver.Chrome()
super(JobboleSpider, self).__init__()
#分发给spider_close,使用信号量spider_closed
dispatcher.connect(self.spider_close,signals.spider_closed ) def spider_close(self):
#爬虫退出时关闭Chrome
self.browser.quit()
......
class SeleniumMiddleware(object):
# 通过selenium请求动态网页
def process_request(self, request, spider):
if spider.name == 'jobbole':
# browser=webdriver.Chrome()
spider.browser.get(request.url)
return HtmlResponse(url=request.url, body=spider.browser.page_source)
3.7pyvirtualdisplay的简单使用(无界面):
安装:pip install pyvirtualdisplay
from selenium import webdriver
from pyvirtualdisplay import Display
#设置无界面,windows环境下不适用
display=Display(visible=0,size=(800,600))
display.start()
browser=webdriver.Chrome()
browser.get('https://i.cnblogs.com/EditPosts.aspx?postid=9753969&update=1')
......
browser.quit()
display.stop()
3.8scrapy-splash,selenium grid,splinter
三.总结:
有很多模拟浏览器操作的插件,而selenium用纯Python写的,效率较慢,但使用方便,是一个很好的测试框架,它的selenium支持分布式。
Selenium简单回顾的更多相关文章
- Android混淆、反编译以及反破解的简单回顾
=========================================================================虽然反编译很简单,也没下面说的那么复杂,不过还是转了过 ...
- 中国2017 Google 开发者大会第二天简单回顾
昨天早晨发布了第一天的开发者大会回顾文章后,就匆匆忙忙赶去会场继续享受高科技的盛宴,接下来简单回顾一下第二天的大会参与情况. 昨天早晨下着小雨,并带着微风,在外面还是挺冷的,这里不得不给工作人员点个赞 ...
- 中国2017 Google 开发者大会第一天简单回顾
昨天有幸参加了中国2017 Google 开发者大会,在这第一天就收获满满,昨天太忙了,今天早晨来一起简单回顾一下,可以让没有参加的童鞋们感受一下现场的温度. 早早就来到了会议现场,外面看不出什么特别 ...
- Selenium 简单的例子
Selenium是一个web自动化验收测试框架. Selenium Client Driver - Selenium 2.0 Document http://seleniumhq.github.i ...
- python+selenium 简单尝试
前言 selenium是一种自动化测试工具,简单来说浏览器会根据写好的测试脚本自动做一些操作. 关于自动化测试,一开始接触的是splinter,但是安装的时候发现它是基于selenium的,于是打算直 ...
- kafka简单回顾
先说说遇到的坑 回顾下kafka topic:生产组:P0\P1----P14 一个消费组:c0 c1 c2 依据Consumer的负载均衡分配 消费顺序"c0:p0-p4 c1:p5-p9 ...
- Jmeter简单回顾
之前公众号推文一上手就分享如何测接口, 其实忽略了一些概念性的东西, 今天来给大家拾遗补缺, 做个回顾吧. 一. JMeter介绍 jmeter能做什么,来自官网的解释: Ability to loa ...
- 自动化测试基础篇--Selenium简单的163邮箱登录实例
摘自https://www.cnblogs.com/sanzangTst/p/7472556.html 前面几篇内容一直讲解Selenium Python的基本使用方法.学习了什么是selenium: ...
- Spring(完成毕业设计后的简单回顾)
最近刚刚做完了毕业设计,在开发时用的是spring框架,做的时候踩了好多坑,又把当初的笔记给翻了翻,做一次简单的回顾 # 1.Spring是什么? 是一个开源的.用于简化企业级应用开发的应用开发框架. ...
随机推荐
- vue快速入门
Vue.js是当下很火的一个JavaScript MVVM库,它是以数据驱动和组件化的思想构建的.相比于Angular.js,Vue.js提供了更加简洁.更易于理解的API,使得我们能够快速地上手并使 ...
- 二.css介绍
一.三种引入样式1.内嵌样式:写在html中 style标签里面2.行内样式:写在具体的标签的style属性3.引入外部样式表:可以将样式规则写在外部文件,再引入到html中 <link typ ...
- Spring Security(十):3. What’s New in Spring Security 4.2 (新功能)
Among other things, Spring Security 4.2 brings early support for Spring Framework 5. You can find th ...
- 使用sql语句比较excel中数据的不同
使用sql语句比较excel中数据的不同 我所在的项目组是一套物流系统,负责与公司的电商系统进行对接.但是公司的电商系统的省市区的配置和物流系统的省市区的配置有差异,所以需要找到这些差异. 首先找到我 ...
- CF1103D Professional layer 状压DP
传送门 首先对于所有数求gcd并求出这个gcd含有的质因子,那么在所有数中,只有这一些质因子会对答案产生影响,而且对于所有的数,每一个质因子只会在一个数中被删去. 质因子数量不会超过\(11\),所以 ...
- 持续集成之单元测试篇——WWH(讲讲我们做单元测试的故事)
持续集成之单元测试篇--WWH(讲讲我们做单元测试的故事) 前言 临近上线的几天内非重大bug不敢进行发版修复,担心引起其它问题(摁下葫芦浮起瓢) 尽管我们如此小心,仍不能避免修改一些bug而引起更多 ...
- Jury Meeting CodeForces - 854D (前缀和维护)
Country of Metropolia is holding Olympiad of Metrpolises soon. It mean that all jury members of the ...
- iOS UICollectionView 在滚动时停在某个item位置上
方法一:实现UIScrollView的代理,然后实现下面这个方法 #pragma mark - UIScrollViewDelegate//预计出大概位置,经过精确定位获得准备位置- (void)sc ...
- Xcode中控制台中打印中文处理
xcode 10以后的方法,一般使用 #ifdef DEBUG #define NSLog(FORMAT, ...) fprintf(stderr,"\n %s:%d %s\n", ...
- 使用Vue自己做一个简单的MarkDown在线编辑器
1.首先要下载mark组件. npm install marked --save 2.在Vcontent.vue中简单写一些样式. <template> <div class=&qu ...