日志收集(ElasticSearch)串联查询 MDC
之前写过将应用程序或服务程序产生的日志直接写入搜索引擎的博客 其中基本过程就是 app->redis->logstash->elasticsearch 整个链路过程 本来想将redis替换成kafka的 无奈公司领导不让(不要问我为什么没有原因不想回答,哦也!就这么酷!!!)
然后又写了相关的优化,其实道理很简单 就是 部署多个redis 多个logstash就ok了 (注意redis建议不要部署集群单节点就OK因为他只承担了消息传输的功能别无其他,架集群的好处就是APP应用自己分发负载了,如果是多个redis单节点需要个类似nginx的东西做负载转发,其实最好使用F5这类的硬件会更好)好了不多说废话下面直奔主题。
遇到的问题
1、去ES(ElasticSearch 以下简称ES)查询日志用关键字搜索要搜索好几次才能定位的问题?
2、多线程调用公用的方法很多时候是不是有点迷糊找不着北等等 不止这些
想要达到的目的
通过关键字(关键字可以是订单号,操作码等可以标识一条信息,一般在数据库里面都是主键)一次查询出来所有的整个链路的相关日志
好,我们的目的很明确,不想各种过滤条件一大堆去定位真正想要的日志,一个关键搞定多所有。
说道这里可能有很多童鞋对日志框架比较了解第一就会想到MDC,没错就是他。下面才是真正的主题,哈哈!
MDC我就不多介绍这里我在网上随便找了一个介绍的 如果熟悉可以略过(https://blog.csdn.net/liubo2012/article/details/46337063)
MDC其实就是在方法里面前后标记一下,然后在这个标记范围内(包括中间调用的方法嵌套)所有的日志都会打上相应的标签记录方便查询
那怎么和我们之前的 方案结合和 我们之前用的是下面这个包,这个包是支持MDC传输的具体源码大家可以参看github实现https://github.com/kmtong/logback-redis-appender
<dependency>
<groupId>com.cwbase</groupId>
<artifactId>logback-redis-appender</artifactId>
<version>1.1.5</version>
</dependency>
当我们引入这个包之后logback.xml文件是如下配置的
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="false" scan="true" scanPeriod="1 seconds">
<include resource="org/springframework/boot/logging/logback/base.xml" />
<!-- <jmxConfigurator/> -->
<contextName>logback</contextName> <property name="log.path" value="\logs\logback.log" /> <property name="log.pattern"
value="%d{yyyy-MM-dd HH:mm:ss.SSS} -%5p ${PID} --- traceId:[%X{mdc_trace_id}] [%15.15t] %-40.40logger{39} : %m%n" /> <appender name="file"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}</file> <encoder>
<pattern>${log.pattern}</pattern>
</encoder> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>info-%d{yyyy-MM-dd}-%i.log
</fileNamePattern> <timeBasedFileNamingAndTriggeringPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"> <maxFileSize>10MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<maxHistory>10</maxHistory>
</rollingPolicy> </appender> <appender name="redis" class="com.cwbase.logback.RedisAppender"> <tags>test</tags>
<host>10.10.12.21</host>
<port>6379</port>
<key>spp</key>
<mdc>true</mdc>
<callerStackIndex>0</callerStackIndex>
<location>true</location> <!-- <additionalField>
<key>traceId</key>
<value>@{destination}</value>
</additionalField> -->
</appender> <root level="info">
<!-- <appender-ref ref="file" /> -->
<!-- <appender-ref ref="UdpSocket" /> -->
<!-- <appender-ref ref="TcpSocket" /> -->
<appender-ref ref="redis" />
</root> <!-- <logger name="com.example.logback" level="warn" /> --> </configuration>
我们把<mdc>true</mdc>标签设置为true 默认是false就可以了,下面我们看下我们的测试代码
package com.zjs.canal.client.client; import org.junit.Test;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.slf4j.MDC; public class testaa {
protected final static Logger logger = LoggerFactory.getLogger(testaa.class); @Test
public void test(){ MDC.put("destination", "123456789");
for (int i = 0; i < 10; i++) {
logger.info("aaaaaaaa"+i);
test1();
}
MDC.remove("destination");
}
public void test1()
{
for (int i = 0; i < 10; i++) {
logger.info("bbbbbbbb"+i);
}
}
}
上面的测试有两层嵌套下面是ES日志输出
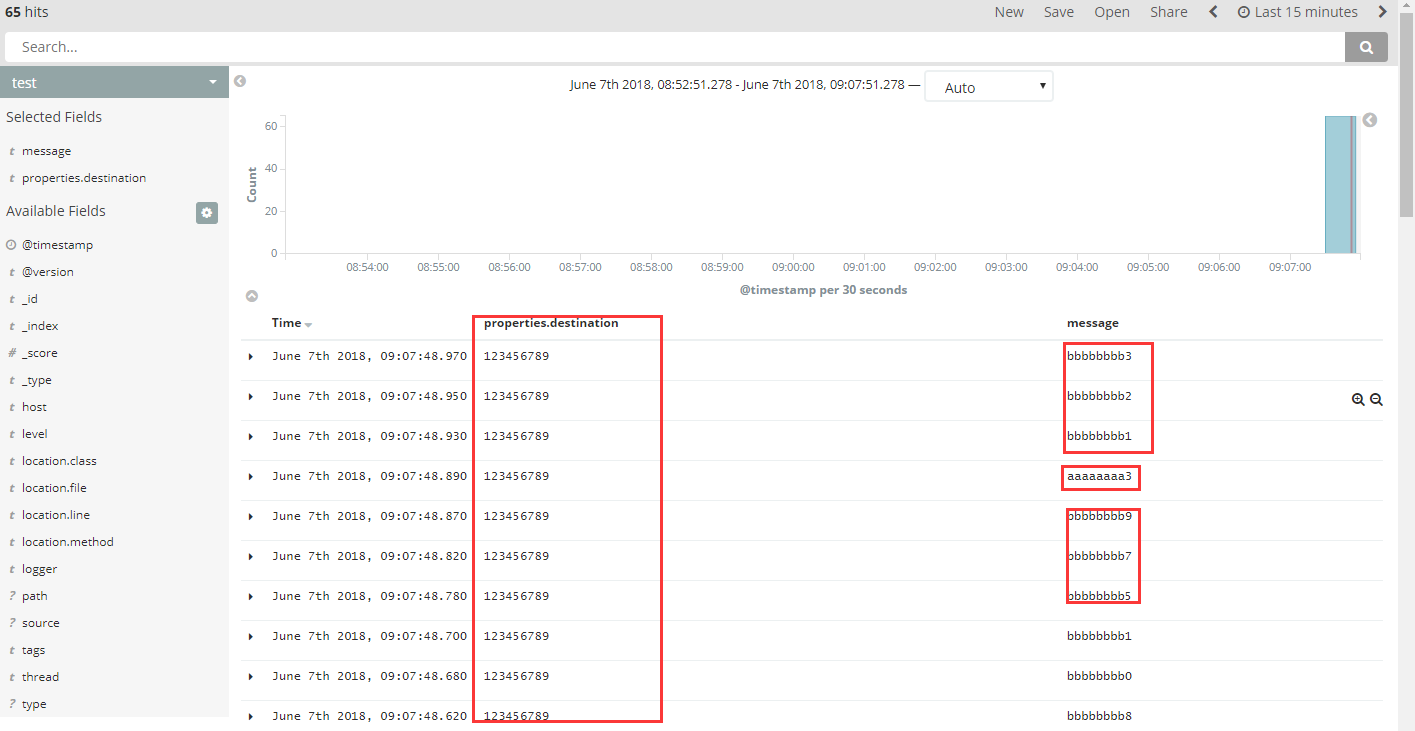
大家可以看到日志输出内容包含了两个方法,都包含相应的properties.destination字段并且值也是一样的(当然真正使用的时候destination MDC的关键字是动态的,选查询的主要关键字)
这样通过关键字一下就能把所有相关的日志都查询出来就能看出数据整个处理流程,这样就非常方便我们的查询定位排查问题
我上面的代码有一段注释不知道大家有没有注意到
就是下面这段
<!-- <additionalField>
<key>traceId</key>
<value>@{destination}</value>
</additionalField> -->
其实我们把<mdc>true</mdc>这句设为false也是可以了不过需要添加一个字段来引用数据(把上面的配置取消注释)这样我们就可以自定义命名跟踪字段的名称了(本人更倾向使用这种)
然后配置就办成下面这样
<appender name="redis" class="com.cwbase.logback.RedisAppender">
<tags>test</tags>
<host>10.10.12.21</host>
<port>6379</port>
<key>spp</key>
<!-- <mdc>true</mdc> -->
<callerStackIndex>0</callerStackIndex>
<location>true</location>
<additionalField>
<key>traceId</key>
<value>@{destination}</value>
</additionalField>
</appender>
然后看下效果
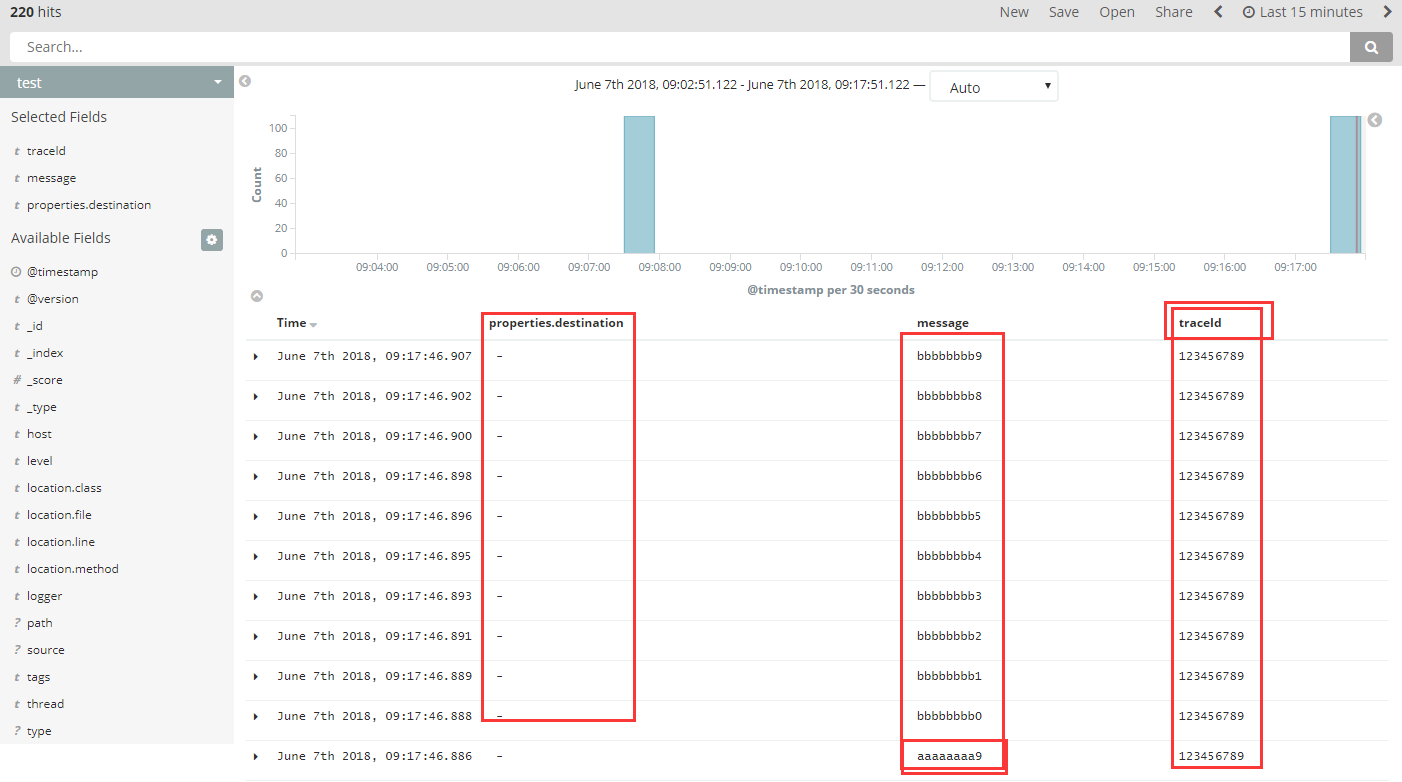
这是之前的默认字段就没有值了mdc引用的值变成我们新的字段里面去了
其实都可以开启 但是会打印两份MDC和自定义字段,这样就会重复了,所以说没必要了
好了 今天就说的这里希望对看博客的你有所帮助
日志收集(ElasticSearch)串联查询 MDC的更多相关文章
- 利用ELK构建一个小型的日志收集平台
利用ELK构建一个小型日志收集平台 伴随着应用以及集群的扩展,查看日志的方式总是不方便,我们希望可以有一个便于我们查询及提醒功能的平台:那么首先需要剖析有几步呢? 格式定义 --> 日志收集 - ...
- 快速搭建应用服务日志收集系统(Filebeat + ElasticSearch + kibana)
快速搭建应用服务日志收集系统(Filebeat + ElasticSearch + kibana) 概要说明 需求场景,系统环境是CentOS,多个应用部署在多台服务器上,平时查看应用日志及排查问题十 ...
- GlusterFS + lagstash + elasticsearch + kibana 3 + redis日志收集存储系统部署 01
因公司数据安全和分析的需要,故调研了一下 GlusterFS + lagstash + elasticsearch + kibana 3 + redis 整合在一起的日志管理应用: 安装,配置过程,使 ...
- 用ElasticSearch,LogStash,Kibana搭建实时日志收集系统
用ElasticSearch,LogStash,Kibana搭建实时日志收集系统 介绍 这套系统,logstash负责收集处理日志文件内容存储到elasticsearch搜索引擎数据库中.kibana ...
- Elasticsearch + Logstash + Kibana +Redis +Filebeat 单机版日志收集环境搭建
1.前置工作 1.虚拟机环境简介 Linux版本:Linux localhost.localdomain 3.10.0-862.el7.x86_64 #1 SMP Fri Apr 20 16:44:2 ...
- ABP 使用ElasticSearch、Kibana、Docker 进行日志收集
ABP 使用ElasticSearch.Kibana.Docker 进行日志收集 后续会根据公司使用的技术,进行技术整理分享,都是干货哦别忘了关注我!!! 最近领导想要我把项目日志进行一个统一收集,因 ...
- 日志收集之--将Kafka数据导入elasticsearch
最近需要搭建一套日志监控平台,结合系统本身的特性总结一句话也就是:需要将Kafka中的数据导入到elasticsearch中.那么如何将Kafka中的数据导入到elasticsearch中去呢,总结起 ...
- logstash收集MySQL慢查询日志
#此处以收集mysql慢查询日志为准,根据文件名不同添加不同的字段值input { file { path => "/data/order-slave-slow.log" t ...
- 基于logstash+elasticsearch+kibana的日志收集分析方案(Windows)
一 方案背景 通常,日志被分散的储存不同的设备上.如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志.这样是不是感觉很繁琐和效率低下.开源实时日志分析ELK平台能够完美的 ...
随机推荐
- iOS网络请求-AFNetworking源码解析
趁着端午节日,自己没有什么过多的安排,准备花4-5天左右,针对网络请求源码AFNetworking和YTKNetwork进行解析以及这两年多iOS实际开发经验(其实YTKNetwork也是对AFNet ...
- WPF 实现ScrollViewer的垂直偏移滚动跳转
问题:考虑屏幕大小,一般都是会在表单问卷的页面使用ScrollViewer.问卷中问题漏填漏选时,在提交时校验不过,需要滚动跳转至漏填漏选项. 页面如下: 每个选项使用StackPanel,并对复选框 ...
- Linux学习笔记之Django项目部署(CentOS)
一.引入 用Django写了一个测试的项目,现在要部署在Linux上,一般这种情况下,只要在项目里面敲一行命令:python manage.py runserver 0.0.0.0:8000就行了.但 ...
- 从零开始学安全(九)●OSI参考模型分层
主要分为7层和网络7层模型一样 物理层主要传输数据比特流 可以理解信号 数据链路层 逻辑层 像是交换机 网络层 又交换机发送到路由器 应用层 应用通信
- Linux-bc命令(21)
bc 命令是任意精度计算器语言,通常在linux下当计算器用. 它类似基本的计算器, 使用这个计算器可以做基本的数学运算. bc支持运算有以下几种: + - * / % :加,减,乘,除,取余 a^b ...
- HashMap深度解析
最基本的结构就是两种,一种是数组,一种是模拟指针(引用),所有的数据结构都可以用这两个基本结构构造,HashMap也一样.当程序试图将多个 key-value 放入 HashMap 中时,以如下代码片 ...
- Module的加载实现
烂笔头开始记录小知识点啦- 浏览器要加载 ES6模块,: <script type="module" src="./foo.js"></scr ...
- 【软工神话】第五篇(Beta收官)
前言:这应该是最后一章了,故事虽然到这就结束了,但现实里还要继续下去,希望在很久的以后来回顾时,能因自己学生时代有这样的经历而欣慰. 说明:故事中的人物均是化名,故事情节经过些许加工,故事情节并没有针 ...
- 洛谷P4561 [JXOI2018]排序问题(二分 期望)
题意 题目链接 Sol 首先一种方案的期望等于它一次排好的概率的倒数. 一次排好的概率是个数数题,他等于一次排好的方案除以总方案,也就是\(\frac{\prod cnt_{a_i}!}{(n+m)! ...
- Java Filter防止sql注入攻击
原理,过滤所有请求中含有非法的字符,例如:, & < select delete 等关键字,黑客可以利用这些字符进行注入攻击,原理是后台实现使用拼接字符串,案例:某个网站的登入验证的SQ ...