HBase最佳实践之Scan
一.简介
二.ScanAPI

整个流程可以分为如下几个步骤:
- next请求首先会检查客户端缓存中是否存在还没有读取的数据行,如果有就直接返回,否则需要将next请求给HBase服务器端【RegionServer】。
- 如果客户端缓存已经没有扫描结果,就会将next请求发送给HBase服务器端。默认情况下,一次next请求仅可以请求100行数据【或者返回结果集总大小不超过2M】。
- 服务器端接收到next请求之后就开始从BlockCache、HFile以及memcache中一行一行进行扫描,扫描的行数达到100行之后就返回给客户端,客户端将这100条数据缓存到内存并返回一条给上层业务。
- HBase本身存储了海量数据,所以很多场景下一次scan请求的数据量都会比较大。如果不限制每次请求的数据集大小,很可能会导致系统带宽吃紧从而造成整个集群的不稳定。
- 如果不限制每次请求的数据集大小,很多情况下可能会造成客户端缓存OOM掉。
- 如果不限制每次请求的数据集大小,很可能服务器端扫描大量数据会花费大量时间,客户端和服务器端的连接就会timeout。
这样的设计有没有瑕疵?next策略可以避免在大数据量的情况下发生各种异常情况,但这样的设计对于扫描效率似乎并不友好,这里举两个例子:
- scan并没有并发执行。这里可能很多看官会问:扫描数据分布在不同的region难道也不会并行执行扫描吗?是的,确实不会,至少在现在的版本中没有实现。这点一定出乎很多读者的意料,我们知道get的批量读请求会将所有的请求按照目标region进行分组,不同分组的get请求会并发执行读取。然而scan并没有这样实现。
- 大家有没有注意到上图中步骤3和步骤4之间HBase服务器端扫描数据的时候HBase客户端在干什么?阻塞等待是吧。确实,所以从客户端视角来看整个扫描时间=客户端处理数据时间+服务器端扫描数据时间,这能不能优化?
ScanAPI应用场景
- 批量OLAP扫描业务建议不要使用ScanAPI,ScanAPI适用于少量数据扫描场景(OLTP场景)
- 建议所有scan尽可能都设置startkey以及stopkey减少扫描范围
- 建议所有仅需要扫描部分列的scan尽可能通过接口setFamilyMap设置列族以及列
三.TableScanMR
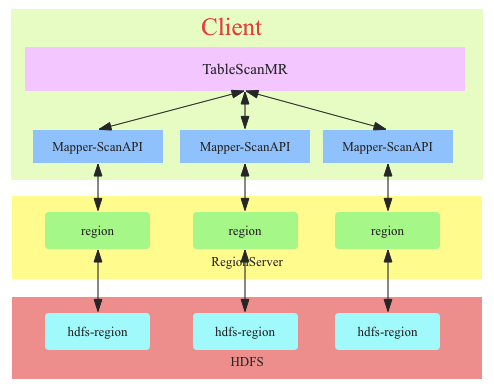
- TableScanMR设计为OLAP场景使用,因此在离线扫描时尽可能使用该中方式
- TableScanMR原理上主要实现了ScanAPI的并行化,将scan按照region边界进行切分。这种场景下整个scan的时间基本等于最大region扫描的时间。在某些有数据倾斜的场景下可能出现某一个region上有大量待扫描数据,而其他大量region上都仅有很少的待扫描数据。这样并行化效果并不好。针对这种数据倾斜的场景TableScanMR做了平衡处理,它会将大region上的scan切分成多个小的scan使得所有分解后的scan扫描的数据量基本相当。这个优化默认是关闭的,需要设置参数”hbase.mapreduce.input.autobalance”为true。因此建议大家使用TableScanMR时将该参数设置为true。
- 尽量将扫描表中相邻的小region合并成大region,而将大region切分成稍微小点的region
- TableScanMR中Scan需要注意如下两个参数设置:
|
1
2
3
|
Scan scan = new Scan();scan.setCaching(500); // 1 is the default in Scan, which will be bad for MapReduce jobsscan.setCacheBlocks(false); // don't set to true for MR jobs |
四.SnapshotScanMR
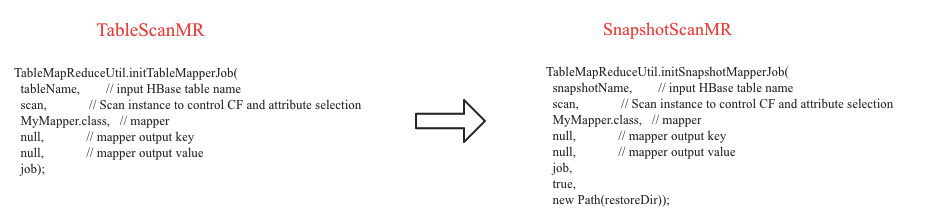
- 从命名来看就知道,SnapshotScanMR扫描于原始表对应的snapshot之上(更准确来说根据snapshot restore出来的hfile),而TableScanMR扫描于原始表。
- SnapshotScanMR直接会在客户端打开region扫描HDFS上的文件,不需要发送Scan请求给RegionServer,再有RegionServer扫描HDFS上的文件。是的,你没看错,是在客户端直接扫描HDFS上的文件,这类scanner称之为ClientSideRegionScanner。
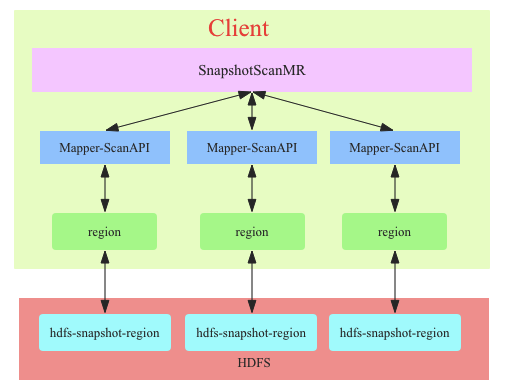
- 减小对RegionServer的影响。很显然,SnapshotScanMR这种绕过RegionServer的实现方式最大限度的减小了对集群中其他业务的影响。
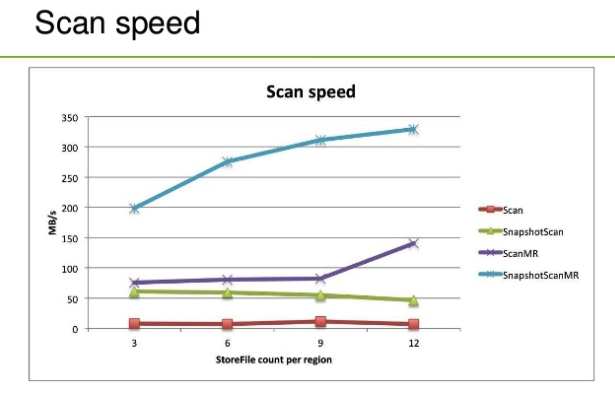
- 极大的提升了扫描效率。SnapshotScanMR相比TableScanMR在扫描效率上会有2倍~N倍的性能提升(下一小节对各种扫描用法性能做个对比评估)。有人又要问了,为什么会有这么大的性能提升?个人认为主要有如下两个方面的原因:
- 扫描的过程少了一次网络传输,对于大数据量的扫描,网络传输花费的时间是非常庞大的,这主要可能牵扯到数据的序列化以及反序列化开销。
- TableScanMR扫描中RegionServer很可能会成为瓶颈,而SnapshotScanMR扫描并没有这个瓶颈点。
基本性能对比

HBase最佳实践之Scan的更多相关文章
- HBase最佳实践(好文推荐)
HBase最佳实践-写性能优化策略 HBase最佳实践-管好你的操作系统 HBase最佳实践之列族设计优化 [大数据]HBase最佳实践 – 集群规划
- 「从零单排HBase 06」你必须知道的HBase最佳实践
前面,我们已经打下了很多关于HBase的理论基础,今天,我们主要聊聊在实际开发使用HBase中,需要关注的一些最佳实践经验. 1.Schema设计七大原则 1)每个region的大小应该控制在10G到 ...
- HBase最佳实践-列族设计优化
本文转自hbase.收藏学习下. 随着大数据的越来越普及,HBase也变得越来越流行.会用HBase现在已经变的并不困难,然而,怎么把它用的更好却并不简单.那怎么定义'用的好'呢?很简单,在保证系统稳 ...
- HBase最佳实践 - 集群规划
本文由 网易云发布. 作者:范欣欣 本篇文章仅限本站分享,如需转载,请联系网易获取授权. HBase自身具有极好的扩展性,也因此,构建扩展集群是它的天生强项之一.在实际线上应用中很多业务都运行在一个 ...
- HBase最佳实践-写性能优化策略
本篇文章来说道说道如何诊断HBase写数据的异常问题以及优化写性能.和读相比,HBase写数据流程倒是显得很简单:数据先顺序写入HLog,再写入对应的缓存Memstore,当Memstore中数据大小 ...
- HBase最佳实践-读性能优化策略
任何系统都会有各种各样的问题,有些是系统本身设计问题,有些却是使用姿势问题.HBase也一样,在真实生产线上大家或多或少都会遇到很多问题,有些是HBase还需要完善的,有些是我们确实对它了解太少.总结 ...
- HBase最佳实践-管好你的操作系统
本文由 网易云发布. 作者:范欣欣 本篇文章仅限本站分享,如需转载,请联系网易获取授权. 操作系统这个话题其实很早就想拿出来和大家分享,拖到现在一方面是因为对其中各种理论理解并不十分透彻,怕讲不好: ...
- HBase最佳实践-用好你的操作系统
终于又切回HBase模式了,之前一段时间因为工作的原因了解接触了一段时间大数据生态的很多其他组件(诸如Parquet.Carbondata.Hive.SparkSQL.TPC-DS/TPC-H等),虽 ...
- Bulk Load-HBase数据导入最佳实践
一.概述 HBase本身提供了非常多种数据导入的方式,通常有两种经常使用方式: 1.使用HBase提供的TableOutputFormat,原理是通过一个Mapreduce作业将数据导入HBase 2 ...
随机推荐
- Android--UI之ListView
前言 今天讲解一下Android平台下ListView控件的开发,在本篇博客中,将介绍ListView的一些常用属性.方法及事件,还会讲解ListView在开发中常用的几种方式,以及使用不通用的适配器 ...
- java中String类为什么不可变?
在面试中经常遇到这样的问题:1.什么是不可变对象.不可变对象有什么好处.在什么情景下使用它,或者更具体一点,java的String类为什么要设置成不可变类型? 1.不可变对象,顾名思义就是创建后的对象 ...
- jvm详情——6、堆大小设置简单说明
年轻代的设置很关键JVM中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制:系统的可用虚拟内存限制:系统的可用物理内存限制.32位系统下,一般限制在1.5G~2G:64 ...
- 基于FineUIMVC的代码生成器(传统三层)v1.0
三层我就不说了,主要是看框架思路可扩展.以前用FineUI开源版写过一版,修修改改自己用了,没有特意的整理,FineUIMVC开发还是比较快,移植了一下两天就弄完了,算是一个对新手有用的工具,先放出第 ...
- Go语言学习笔记(四) [array、slice、map]
日期:2014年7月22日 一.array[数组] 1.定义:array 由 [n]<type> 定义,n 标示 array 的长度,而 <type> 标示希望存储的内 ...
- python字典类型
字典类型简介 字典(dict)是存储key/value数据的容器,也就是所谓的map.hash.关联数组.无论是什么称呼,都是键值对存储的方式. 在python中,dict类型使用大括号包围: D = ...
- Python面向对象基础:编码细节和注意事项
在前面,我用了3篇文章解释python的面向对象: 面向对象:从代码复用开始 面向对象:设置对象属性 类和对象的名称空间 本篇是第4篇,用一个完整的示例来解释面向对象的一些细节. 例子的模型是父类Em ...
- JVM(二)—— 类加载机制
问题 1.为什么要有类加载机制(类加载机制的意义是什么) 2.类加载机制的过程,这些步骤可以颠倒顺序么?,每个步骤的作用是什么? 3.什么情况下必须对类进行初始化 类加载的过程 加载--验证--准备- ...
- B树与B+详解
承接上篇SQLite采用B树结构使得SQLite内存占用资源较少,本篇将讲述B树的具体操作(建树,插入,删除等操作).在看博客时,建议拿支笔和纸,一点一点操作,毕竟知识是自己的,自己也要消化的.本篇通 ...
- iOS UITextfield只允许输入数字和字母,长度限制
-(BOOL)textField:(UITextField *)textField shouldChangeCharactersInRange:(NSRange)range replacementSt ...