selenium+chrome抓取淘宝搜索抓娃娃关键页面
最近迷上了抓娃娃,去富国海底世界抓了不少,完全停不下来,还下各种抓娃娃的软件,梦想着有一天买个抓娃娃的机器存家里~.~
今天顺便抓了下马爸爸家抓娃娃机器的信息,晚辈只是觉得翻得手酸,本来100页的数据,就抓了56条,还希望马爸爸莫怪。。。。
有对爬虫的感兴趣的媛友,可以作为参考哦!
# coding:utf-8 import pymongo
import time
import re
from selenium import webdriver
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 使用无界面浏览器
from selenium.webdriver.chrome.options import Options
# 创建驱动对象
chrome_options = webdriver.ChromeOptions()
# 设置代理
# chrome_options.add_argument('--proxy-server=http://ip:port')
# 加载浏览器头
# 更换头部
chrome_options.add_argument('User-Agent="Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36"')
# 不加载图片
prefs = {"profile.managed_default_content_settings.images":2}
chrome_options.add_experimental_option("prefs",prefs)
# 设置无界面浏览器
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable--gpu')
driver = webdriver.Chrome(chrome_options=chrome_options) # 设置显示等待时间
wait = WebDriverWait(driver,1) # 翻页 在底部输入框输入页数进行翻页
def next_page(page_num):
try:
print ('正在翻第----%s------页' %page_num)
# 获得页码输入框 try是否超时报错
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.form > input'))
)
# 清空输入框的内容
input.clear()
# 输入框输入页码
input.send_keys(page_num)
# 获得确定按钮
btn = driver.find_element_by_class_name('.btn J_Submit')
# 点击确定按钮
btn.click()
# 根据对应页码高亮部分判断是否成功
# 获得高亮部分
wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > ul > li.item.active > span'))
)
parse_html(driver.page_source)
except TimeoutException:
# 报错重新请求
return next_page(page_num) def save_mongo(data):
client = pymongo.MongoClient('60.205.211.210',27017)
# 连接数据库
db = client.test
# 连接集合
collection = db.taobao
# 插入数据
collection.insert(data) def parse_html(html):
html_page = BeautifulSoup(html,'lxml')
items = html_page.select('.m-itemlist .items .item')
for item in items:
# 图片url
img_url = item.select('.pic .pic-link')[0].attrs['href']
if img_url.startswith('//'):
img_url = 'https:' + img_url
# print (img_url)
# 价格
price = item.select('.price')[0].text.strip()[1:]
# print (price)
# 销量
sales = re.search(r'(\d+)',item.select('.deal-cnt')[0].text).group(1)
# print (sales)
# 商品描述
desc = item.select('.title .J_ClickStat')[0].text.strip()
# print (desc)
# 店铺
shop = item.select('.shop .dsrs + span')[0].text.strip()
# print (shop)
# 地址
address = item.select('.location')[0].text.strip()
# print(address)
product_data = {
'img_url':img_url,
'price':price,
'desc':desc,
'sales':sales,
'shop':shop,
'address':address
}
print (product_data)
save_mongo(product_data) def get_page(url):
try:
driver.get(url)
search_input = wait.until(
# 参数为元祖
EC.presence_of_element_located((By.ID,'q'))
)
search_input.send_keys(u'抓娃娃')
btn = driver.find_element_by_class_name('btn-search')
btn.click()
# 实现翻页 需要把总页数return出去
total_pages = driver.find_element_by_css_selector('#mainsrp-pager > div > div > div > div.total').text
total_pages_num = re.compile(r'(\d+)').search(total_pages).group(1)
# print (total_pages_num)
parse_html(driver.page_source)
return total_pages_num
except TimeoutException as e:
print (e.msg) def main():
url = 'https://www.taobao.com'
try:
page_num = get_page(url)
# for i in range(2,int(page_num)+1):
for i in range(2, int(page_num) - 96):
next_page(i)
except Exception as e:
print (e.message)
finally:
driver.close() if __name__ == '__main__':
main()
要是环境配置好了,可以直接跑一下哦!
下面是mongo数据库数据:

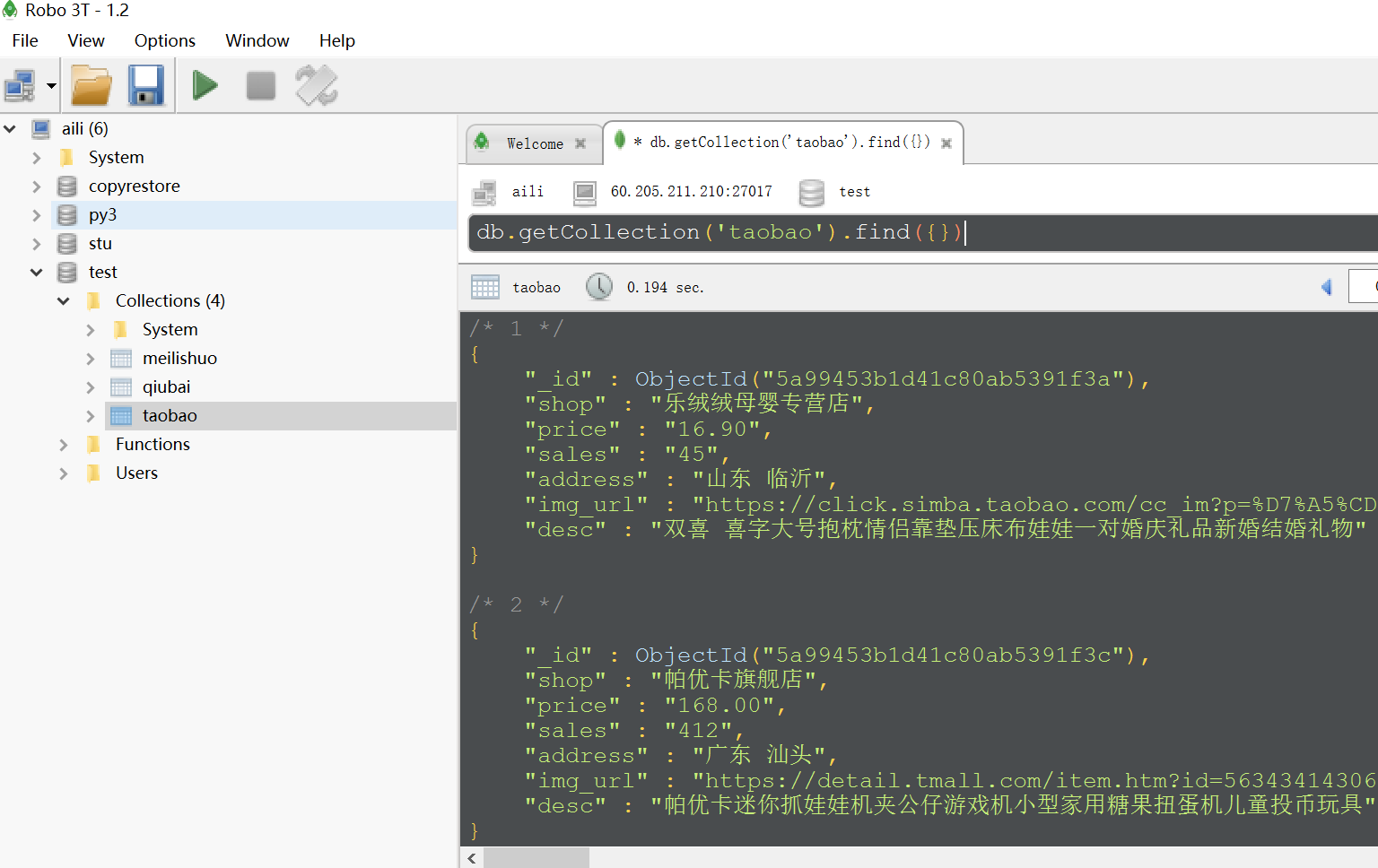
selenium+chrome抓取淘宝搜索抓娃娃关键页面的更多相关文章
- selenium+PhantomJS 抓取淘宝搜索商品
最近项目有些需求,抓取淘宝的搜索商品,抓取的品类还多.直接用selenium+PhantomJS 抓取淘宝搜索商品,快速完成. #-*- coding:utf-8 -*-__author__ =''i ...
- 一个小demo 实用selenium 抓取淘宝搜索页面内的产品内容
废话少说,上代码 #conding:utf-8 import re from selenium import webdriver from selenium.webdriver.common.by i ...
- Selenium模拟浏览器抓取淘宝美食信息
前言: 无意中在网上发现了静觅大神(崔老师),又无意中发现自己硬盘里有静觅大神录制的视频,于是乎看了其中一个,可以说是非常牛逼了,让我这个用urllib,requests用了那么久的小白,体会到sel ...
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
- Python爬虫学习==>第十二章:使用 Selenium 模拟浏览器抓取淘宝商品美食信息
学习目的: selenium目前版本已经到了3代目,你想加薪,就跟面试官扯这个,你赢了,工资就到位了,加上一个脚本的应用,结局你懂的 正式步骤 需求背景:抓取淘宝美食 Step1:流程分析 搜索关键字 ...
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- 16-使用Selenium模拟浏览器抓取淘宝商品美食信息
淘宝由于含有很多请求参数和加密参数,如果直接分析ajax会非常繁琐,selenium自动化测试工具可以驱动浏览器自动完成一些操作,如模拟点击.输入.下拉等,这样我们只需要关心操作而不需要关心后台发生了 ...
- 使用selenium模拟浏览器抓取淘宝信息
通过Selenium模拟浏览器抓取淘宝商品美食信息,并存储到MongoDB数据库中. from selenium import webdriver from selenium.common.excep ...
- python(27) 抓取淘宝买家秀
selenium 是Web应用测试工具,可以利用selenium和python,以及chromedriver等工具实现一些动态加密网站的抓取.本文利用这些工具抓取淘宝内衣评价买家秀图片. 准备工作 下 ...
随机推荐
- requests_模拟登录知乎
如何登录知乎? 首先要分析,进行知乎验证的时候,知乎服务器需要我们提交什么数据,提交的地址.先进行几次登录尝试,通过浏览器中network中查看数据流得知,模拟登录知乎需要提供5个数据,分别是_xsr ...
- Linux PHP多版本切换 超简单办法
今天在帮别人安装一个不知所谓的东西时碰到,三版本的PHP环境,我感觉那个人也是666哒,他使用的是AMH快速开发工具 有图有真相!!! 然后就顺便写下怎么快速,简便切换php版本 首先:find命令找 ...
- 【高并发简单解决方案】redis队列缓存 + mysql 批量入库 + php离线整合
需求背景:有个调用统计日志存储和统计需求,要求存储到mysql中:存储数据高峰能达到日均千万,瓶颈在于直接入库并发太高,可能会把mysql干垮. 问题分析 思考:应用网站架构的衍化过程中,应用最新的框 ...
- PHP微信H5支付开发
近来公司项目要求用到微信H5开发,因为微信开发文档处处都是坑,我也走了不少弯路,现在就把H5支付的过程记录一下,已备后用!! 首先 先去商户平台申请开通 H5支付!!!! 我们从微信官方下载H5支付d ...
- VisionPro随笔-Visionpro空间字符的含义
在visionpro中名字空间是一个非常重要的概念.简单的说就是在图像中的一个特殊坐标系. 下面说下名字空间中一些固定的字符的特殊含义: 1)“.”=这个表示使用输入图像的当前名字空间.即cogima ...
- java to kotlin (2) - lambda编程
前言 Kotlin Note 是我学习kotlin整理笔记向博客,文章中的例子参考了kotlin in action这本书籍,同时我也极力推荐这本书,拥有Java基础的人可以很快的就使用kotlin来 ...
- unity getcomponentsinchildren 翻船
今天使用GetComponentsInChildren, 老司机翻船.因为一直以来我使用这个函数,下意识的从来所有的相同component都是放在子节点下,本身节点肯定不会放一个相同的componen ...
- disptch_after 自递归
NSArray *arr = @[@"1", @"2", @"3", @"4", @"5"]; ...
- iOS导出ipa包时四个选项的意义
1. Save for iOS App Store Deployment 保存到本地 准备上传App Store 或者在越狱的iOS设备上使用 2. Save for Ad Hoc Deploymen ...
- PostgreSQL版本快速升级
PostgreSQL版本快速升级 写在前面 PostgreSQL9.5版本支持数据分片的功能,为以后做分布式考虑,准备将生产环境的9.1版本升级至9.5.中间需要做数据迁移. 在迁移操作中,为保证数据 ...