汽车之家汽车品牌Logo信息抓取 DotnetSpider实战[三]
一、正题前的唠叨
第一篇实战博客,阅读量1000+,第二篇,阅读量200+,两篇文章相差近5倍,这个差异真的令我很费劲,截止今天,我一直在思考为什么会有这么大的差距,是因为干货变少了,还是什么原因,一直没想清楚,如果有读者发现问题,可以评论写下大家的观点,当出现这样的差距会是什么原因,谢谢大家。
二、分析汽车之家品牌Logo页面
2.1分析页面结构
首先我们打开汽车之家品牌Logo选择页 https://car.m.autohome.com.cn/,我们以华颂为例,实际上我们就是需要将class是item的里面的img的src(图片路径),和strong里面的text(品牌)获取就行了,大家可以看到,这个其实很简单,相比上次我们获取页面,获取接口数据简单多了,为什么要单独拿一个作为一篇文章呢,就是因为这个地方还涉及到一个文件下载,这一块之前都没有提到过。
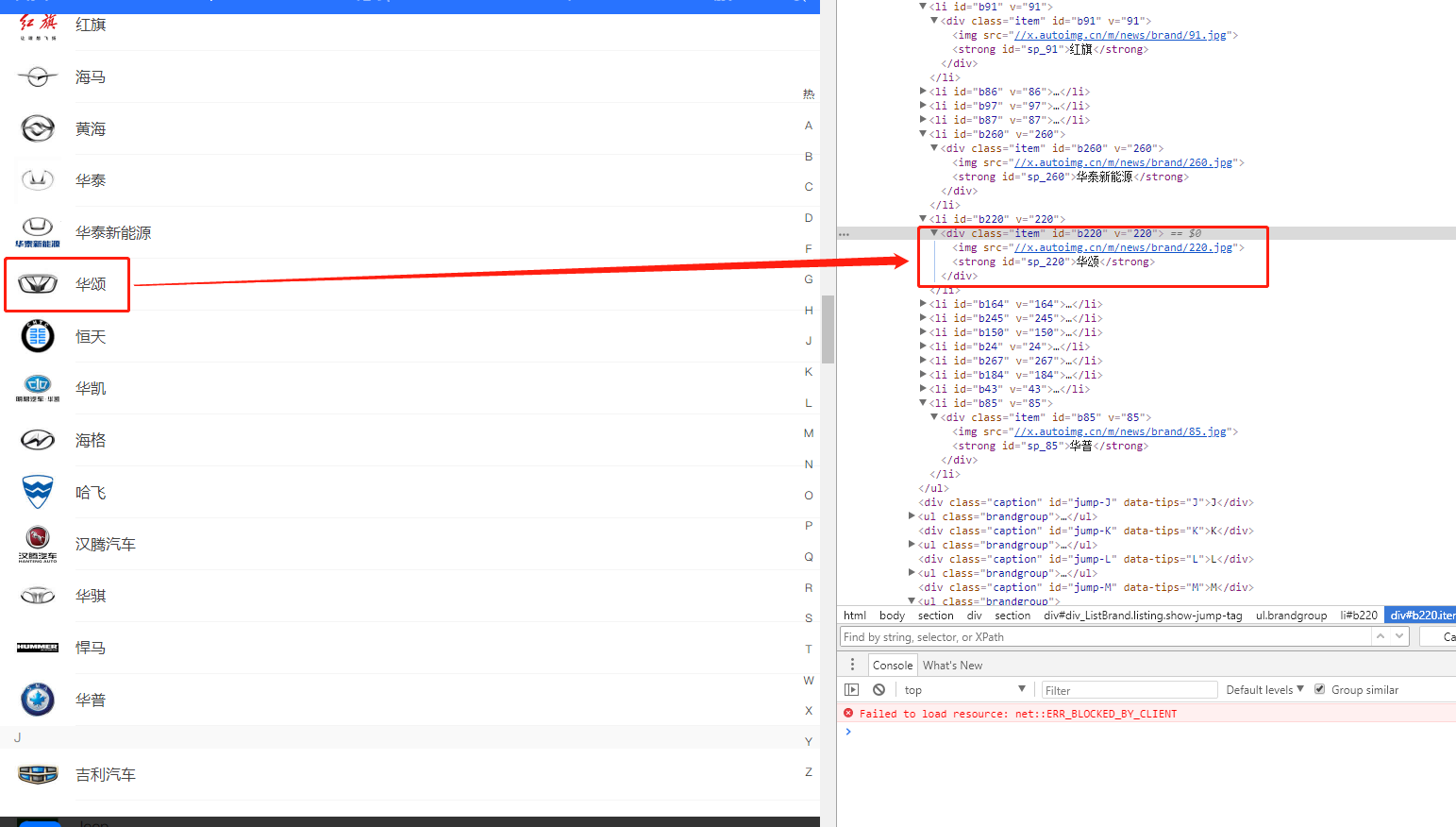
2.2页面中的坑
最开始抓取的时候,我发现很多地方src都是空,我就很纳闷为什么会这样,后来断点调试后才发现,汽车之家Logo图片在页面还未划到此处的时候,img是不会加载的,只是占一个位置在那,等到滚动条滚到哪,哪的图片就会加载,所以此处抓取img的路径时需要判断一下

三、动手开发
3.1准备Processor
private class GetLogoInfoProcessor : BasePageProcessor //获取Logo信息
{
public GetLogoInfoProcessor()
{
}
protected override void Handle(Page page)
{
List<LogoInfoModel> logoInfoList = new List<LogoInfoModel>();
var logoInfoNodes = page.Selectable.XPath(".//div[@id='div_ListBrand']//div[@class='item']").Nodes();
foreach (var logoInfo in logoInfoNodes)
{
LogoInfoModel model = new LogoInfoModel();
model.BrandName = logoInfo.XPath("./strong").GetValue();
model.ImgPath = logoInfo.XPath("./img/@src").GetValue();
if (model.ImgPath == null)
{
model.ImgPath = logoInfo.XPath("./img/@data-src").GetValue();
}
if (model.ImgPath.IndexOf("https") == -)
{
model.ImgPath = "https:" + model.ImgPath;
}
logoInfoList.Add(model);
//page.AddTargetRequest(model.ImgPath); //Site设置DownloadFiles为TRUE就可以自动下载文件
}
page.AddResultItem("LogoInfoList", logoInfoList); } }
3.2准备Pipeline
这个地方我没用他原用的下载方法,自己写了一个简单的下载方法,因为我感觉他的下载方式直接down下来,不是很符合我的业务逻辑
private class PrintLogInfoPipe : BasePipeline
{ public override void Process(IEnumerable<ResultItems> resultItems, ISpider spider)
{ foreach (var resultItem in resultItems)
{
var logoInfoList = resultItem.GetResultItem("LogoInfoList") as List<LogoInfoModel>;
foreach (var logoInfo in logoInfoList)
{
Console.WriteLine($"brand:{logoInfo.BrandName} path:{logoInfo.ImgPath}");
SaveFile(logoInfo.ImgPath, logoInfo.BrandName);
}
}
}
private void SaveFile(string url, string filename)
{
HttpRequestMessage httpRequestMessage = new HttpRequestMessage();
httpRequestMessage.RequestUri = new Uri(url);
httpRequestMessage.Method = HttpMethod.Get;
HttpClient httpClient = new HttpClient();
var httpResponse = httpClient.SendAsync(httpRequestMessage);
string filePath = Environment.CurrentDirectory + "/img/"+ filename + ".jpg";
if (!File.Exists(filePath))
{
try
{
string folder = Path.GetDirectoryName(filePath);
if (!string.IsNullOrWhiteSpace(folder))
{
if (!Directory.Exists(folder))
{
Directory.CreateDirectory(folder);
}
} File.WriteAllBytes(filePath, httpResponse.Result.Content.ReadAsByteArrayAsync().Result);
}
catch
{
}
}
httpClient.Dispose();
}
}
存储实体类
private class LogoInfoModel
{
public string BrandName { get; set; }
public string ImgPath { get; set; }
}
3.3构造爬虫
static void Main(string[] args)
{
var site = new Site
{
CycleRetryTimes = ,
SleepTime = ,
//DownloadFiles = true, DotNetSpider中设置是否下载文件
Headers = new Dictionary<string, string>()
{
{ "Accept","text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8" },
{ "Cache-Control","no-cache" },
{ "Connection","keep-alive" },
{ "Content-Type","application/x-www-form-urlencoded; charset=UTF-8" },
{ "User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"}
} };
List<Request> resList = new List<Request>();
Request res = new Request();
res.Url = "https://car.m.autohome.com.cn/";
res.Method = System.Net.Http.HttpMethod.Get;
resList.Add(res);
var spider = Spider.Create(site, new QueueDuplicateRemovedScheduler(), new GetLogoInfoProcessor())
.AddStartRequests(resList.ToArray())
.AddPipeline(new PrintLogInfoPipe());
spider.ThreadNum = ;
spider.Run();
Console.Read();
}
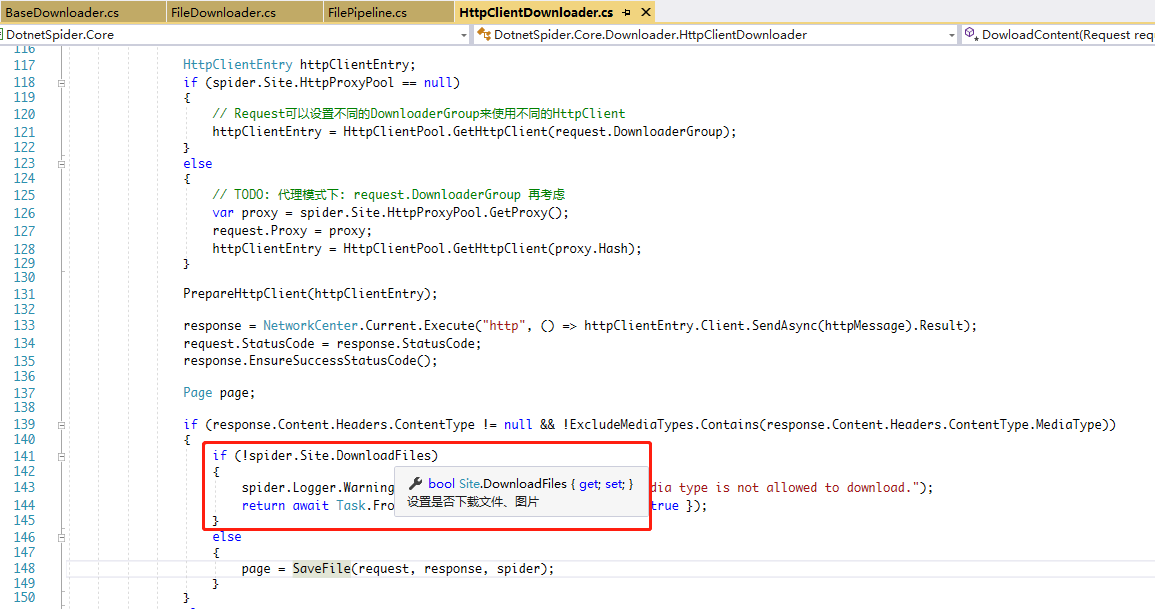
3.4 Site中DownloadFiles 源码分析
源代码中HttpClientDownloader中源代码会自动去判断Site中的DownloadFiles是否允许下载文件,默认是false,如果不将DownloadFiles的值设置为true,那么对于非字符串格式的接口数据,直接会被忽略,如果大家感兴趣,可以将我代码中的两行注释取消,那么就可以看到DotnetSpider中的下载方式
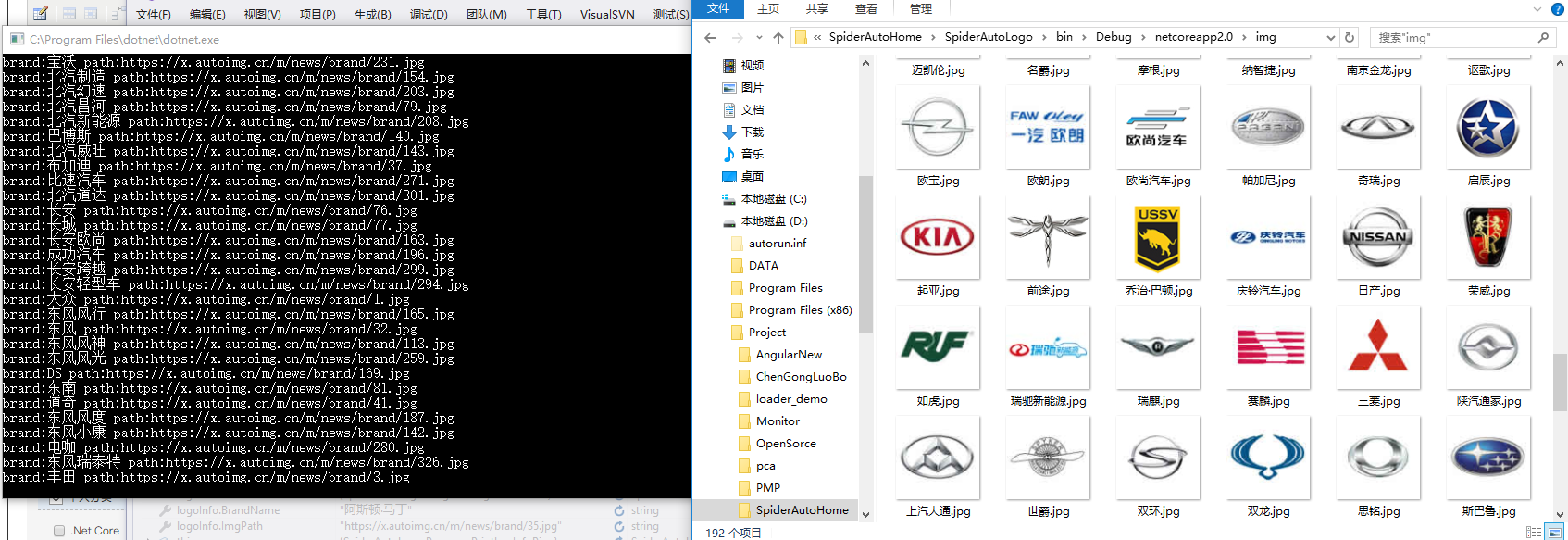
四、执行结果
本次执行的结果,已经上传到bilibili中,大家有兴趣可以打开围观一下
https://www.bilibili.com/video/av24022630/
五、总结
这次我们将数据的抓取以及文件的下载进行了一个小综合,也介绍了DotnetSpider原生的下载方式,以及我自己写的一个下载方法,大家如果遇到类似的需求可以自己选择符合自己业务逻辑的方法,希望这篇文章能够帮助到大家,如果觉得哪里写的不好,欢迎拍大板砖
三次博文源代码我已经上传Github,感兴趣可以直接下载下来 https://github.com/FunnyBoyDeng/SpiderAutoHome
六、下期没有预告
至于下期我还没想好爬什么,欢迎大家留言说自己想要爬的东西
2018-05-27
汽车之家汽车品牌Logo信息抓取 DotnetSpider实战[三]的更多相关文章
- 汽车之家店铺商品详情数据抓取 DotnetSpider实战[二]
一.迟到的下期预告 自从上一篇文章发布到现在,大约差不多有3个月的样子,其实一直想把这个实战入门系列的教程写完,一个是为了支持DotnetSpider,二个是为了.Net 社区发展献出一份绵薄之力,这 ...
- 汽车之家店铺数据抓取 DotnetSpider实战[一]
一.背景 春节也不能闲着,一直想学一下爬虫怎么玩,网上搜了一大堆,大多都是Python的,大家也比较活跃,文章也比较多,找了一圈,发现园子里面有个大神开发了一个DotNetSpider的开源库,很值得 ...
- 汽车之家店铺数据抓取 DotnetSpider实战
一.背景 春节也不能闲着,一直想学一下爬虫怎么玩,网上搜了一大堆,大多都是Python的,大家也比较活跃,文章也比较多,找了一圈,发现园子里面有个大神开发了一个DotNetSpider的开源库,很值得 ...
- Atitit.web的自动化操作与信息抓取 attilax总结
Atitit.web的自动化操作与信息抓取 attilax总结 1. Web操作自动化工具,可以简单的划分为2大派系: 1.录制回放 2.手工编写0 U' z; D! s2 d/ Q! ^1 2. 常 ...
- 网页信息抓取进阶 支持Js生成数据 Jsoup的不足之处
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/23866427 今天又遇到一个网页数据抓取的任务,给大家分享下. 说道网页信息抓取 ...
- Ajax异步信息抓取方式
淘女郎模特信息抓取教程 源码地址: cnsimo/mmtao 网址:https://0x9.me/xrh6z 判断一个页面是不是Ajax加载的方法: 查看网页源代码,查找网页中加载的数据信息,如果 ...
- 网页信息抓取 Jsoup的不足之处 httpunit
今天又遇到一个网页数据抓取的任务,给大家分享下. 说道网页信息抓取,相信Jsoup基本是首选的工具,完全的类JQuery操作,让人感觉很舒服.但是,今天我们就要说一说Jsoup的不足. 1.首先我们新 ...
- 网易新闻页面信息抓取(htmlagilitypack搭配scrapysharp)
转自原文 网易新闻页面信息抓取(htmlagilitypack搭配scrapysharp) 最近在弄网页爬虫这方面的,上网看到关于htmlagilitypack搭配scrapysharp的文章,于是决 ...
- 接口测试——fiddler对soapui请求返回信息抓取
原文:接口测试——fiddler对soapui请求返回信息抓取 背景:接口测试的时候,需要对接口的请求和返回信息进行查阅或者修改请求信息,可利用fiddler抓包工具对soapui的请求数据进行抓取或 ...
随机推荐
- FFPLAY的原理(三)
播放声音 现在我们要来播放声音.SDL也为我们准备了输出声音的方法.函数SDL_OpenAudio()本身就是用来打开声音设备的.它使用一个叫做SDL_AudioSpec结构体作为参数,这个结构体中包 ...
- gitolite服务器部署中的一些坑
1.秘钥登录问题可参考< 安装gitolite,并ssh公钥无密码登录>http://www.cnblogs.com/tr0217/p/4517952.html,该文中推荐了阮一峰的< ...
- (七):C++分布式实时应用框架 2.0
C++分布式实时应用框架 2.0 技术交流合作QQ群:436466587 欢迎讨论交流 上一篇:(六):大型项目容器化改造 版权声明:本文版权及所用技术归属smartguys团队所有,对于抄袭,非经同 ...
- Install and Configure Apache Kafka on Ubuntu 16.04
https://devops.profitbricks.com/tutorials/install-and-configure-apache-kafka-on-ubuntu-1604-1/ by hi ...
- (汇总)os模块以及shutil模块对文件的操作
''' # os 模块 os.sep 可以取代操作系统特定的路径分隔符.windows下为 '\\' os.name 字符串指示你正在使用的平台.比如对于Windows,它是'nt',而对于Linux ...
- ASP.NET(C#) Repeater分页的实现
ASP.NET(C#) Repeater分页的实现 第一种方式: 数据库连接代码: using System; using System.Data; using System.Configuratio ...
- ArcGIS 产品体系结构
1. 开篇 本文主要从以下几个方面介绍 ArcGIS 的产品体系 2. 详细介绍 2.1 ArcGIS Desktop 参考:[https://blog.csdn.net/hphone/article ...
- Spring Boot实战笔记(八)-- Spring高级话题(条件注解@Conditional)
一.条件注解@Conditional 在之前的学习中,通过活动的profile,我们可以获得不同的Bean.Spring4提供了一个更通用的基于条件的Bean的创建,即使用@Conditional注解 ...
- SpringMVC中的异常处理
springmvc在处理请求过程中出现异常信息交由异常处理器进行处理,自定义异常处理器可以实现一个系统的异常处理逻辑. 1. 异常处理思路 系统中异常包括两类:预期异常和运行时异常RuntimeExc ...
- 执行指定iframe页面的脚本
mark一下,通过jQuery执行指定iframe页面里面的脚本,当前仅知道页面名称. $(window.top.document).find('iframe[src="pagesrc&qu ...