90后的青春,定格在被淡忘的QQ空间里
QQ空间,这个曾经陪我们从童年到少年再到成年,从2G时代再到如今的4G末,占据了我们太多的青春回忆,如今好友空间动态更新的不在像从前那样频繁。依稀记得当年的好友买卖,抢车位再或者情侣空间,现在想想那时候真的很幼稚,那就是我们傻逼的童年,什么互踩,火星文,跑堂见证了我们无忧无虑的童年。
有时候看看QQ推送的"那年今日",看到自己好几年前发的动态,说的傻话,自己都怕了自己。有时候看到好朋友几年前的动态,不由笑骂道,这孙子,怎么这么2! 即使现在不怎么用QQ了,有时候看看曾经发的说说还有空间的留言。即使让我再尴尬也不舍得删,因为那都是青春满满的回忆。
空间留言上千条,说说也比较多,一页一页的翻比较麻烦。索性就把这些数据都下载到本地。同理我们也可以导出全部联系人的说说和留言板。
Selenium
由于访问好友留言板需要登录,为了方便起见我们使用Web应用程序测试的Selenium工具。该工具可以用于单元测试,集成测试,系统测试等等。它可以像真正的用户一样去操作浏览器等,支持Mozilla Firefox、Google Chrome、Safari、Opera、IE等等浏览器。
使用这个工具之前我们需要安装selenium库和下载相应浏览器的驱动。然后通过分析QQ空间登录界面我们发现默认是扫码登录,因此需要切换成账号密码登录。
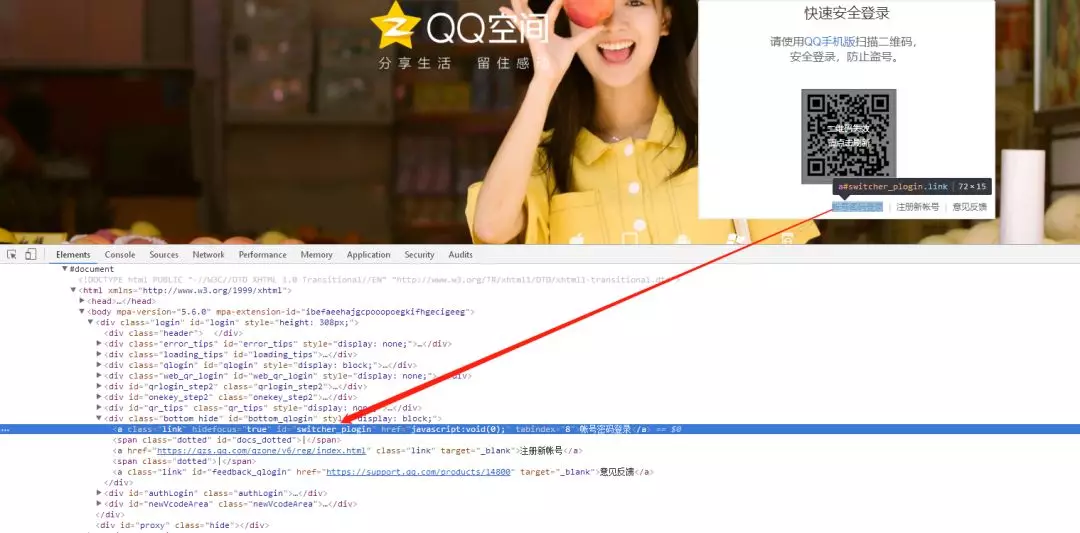
通过分析html标签属性,我们发现 id="switcher_plogin",是个切换登录的全局唯一属性。同理我们再需要找到账号、密码输入框和点击登录的元素就可以用selenium模拟登录了
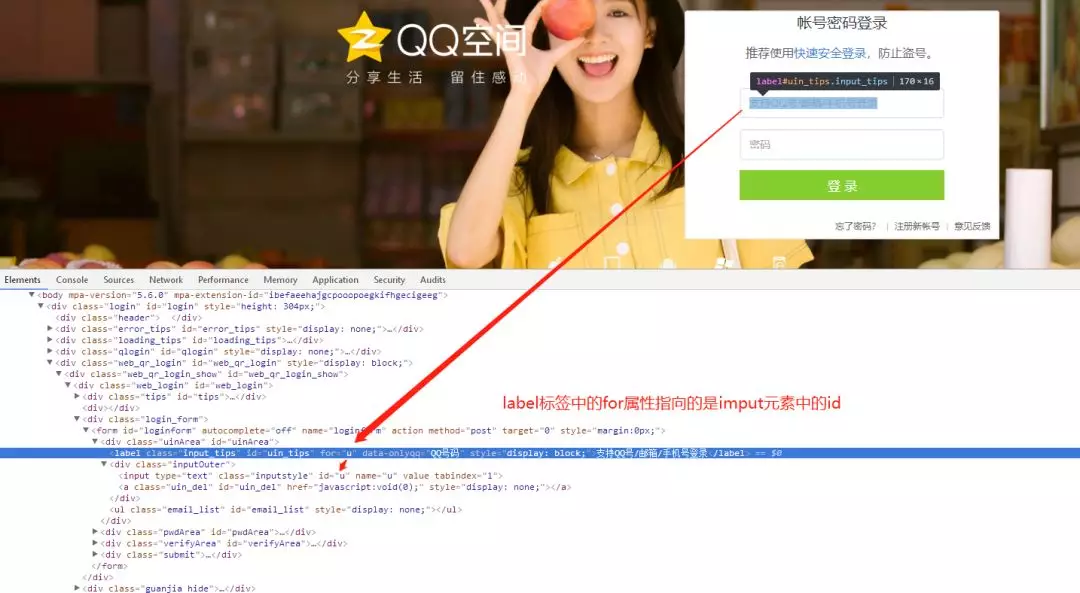
登录部分代码如下:
from selenium import webdriver driver = webdriver.Chrome()
# 获取谷歌浏览器驱动
driver = webdriver.Chrome()
# 登录网站
driver.get('https://i.qq.com')
# 选择账号密码登录
driver.switch_to_frame('login_frame')
# 点击输入框获取输入
driver.find_element_by_id('switcher_plogin').click()
# 输入账号
driver.find_element_by_id('u').send_keys('你的qq号')
# 输入密码
driver.find_element_by_id('p').send_keys('qq密码')
# 点击登录
driver.find_element_by_id('login_button').click()
工作前的参数准备
通过查看开发者工具中的请求我们发现,登录之后每次请求除了携带必要的参数以外,还携带了登录获取的token和g_tk。token我们可以从网页源代码中直接获取,但是g_tk在源代码中没有,根据以往经验第一步只能从js中查看,果然发现了一段加密代码,再结合上下文发现是从cookie中取出“p_skey”的值再经过一系列操作就是g_tk的值了。因为我们需要先获取cookie,然后再通过cookie获取g_tk。
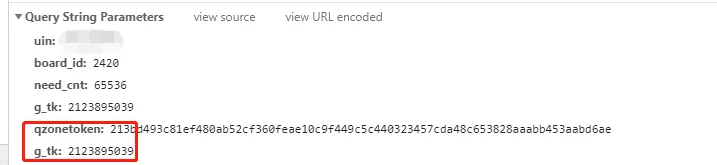
部分js加密逻辑代码
if (e) {
if (e.host && e.host.indexOf("qzone.qq.com") > 0) {
try {
t = parent.QZFL.cookie.get("p_skey")
} catch(e) {
t = QZFL.cookie.get("p_skey")
}
}
............
}
"g_tk=" + QZFL.pluginsDefine.getACSRFToken(t)
QZFL.pluginsDefine.getACSRFToken._DJB = function(e) {
var t = 5381;
for (var n = 0,
r = e.length; n < r; ++n) {
t += (t << 5) + e.charCodeAt(n)
}
return t & 2147483647
};
获取token && cookie && g_tk代码
"""
获取g_tk的值
"""
def get_g_tk(cookie):
hashes = 5381
for letter in cookie['p_skey']:
hashes += (hashes << 5) + ord(letter)
return hashes & 0x7fffffff # 获取登录之后的cookie信息
cookie = {}
for elem in driver.get_cookies():
cookie[elem['name']] = elem['value']
# 获取g_tk
g_tk = get_g_tk(cookie)
# 利用xpath获取登录之后的网页源代码
html = driver.page_source
xpath = r'window\.g_qzonetoken = \(function\(\)\{ try\{return "(.*?)";}'
# 通过xpath 获得登录后的token
token = re.compile(xpath).findall(html)[0]
开始搞事
破解了一个简单的反爬虫,下面就可以编写正式的爬虫代码了,首先确定我们目标url、通过浏览器分析响应的json对象、编写headers
因为每次请求都需要携带登录信息,为了方便我们用到了session类,其次观察相应我们发现返回的response有无用的字符,因此需要进行截取

headers = {
'authority': 'user.qzone.qq.com',
'method': 'GET',
'scheme': 'https',
'accept-language': 'zh-CN,zh;q=0.9',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
def get_resp(cookie, g_tk, token, page):
session = requests.session()
# 将cookie字典转换成RequestsCookieJar
c = requests.utils.cookiejar_from_dict(cookie)
# 将headers 放入session
session.headers = headers
# RequestsCookieJar复制给session
session.cookies = c
# 访问留言板的url
url = f'https://user.qzone.qq.com/proxy/domain/m.qzone.qq.com/cgi-bin/new/get_msgb?uin={登陆的qq}&hostUin={要查询留言内容的QQ号}&start={page}&num=10&g_tk={g_tk}&qzonetoken={token}'
print(url)
response = session.get(url)
# 截取无用的字符
resp_text = response.text[10: -3]
# 转为json
resp_json = json.loads(resp_text)
return resp_json
上面的方法,只是获得了某一页的接口相应,我们通过json获取留言总数,再除以每页的条数,就可以知道总页数了。然后再遍历去取每页的数据,为了方便查看将数据保存在csv文件中,另外将留言内容保存在txt文件中,生成词云。
def get_zone_xx(cookie, g_tk, token, page=0):
# 初始化请求为了取总条数
resp_json = get_resp(cookie, g_tk, token, page)
# 总条数
total = resp_json['data']['total']
print(f'共{total}条留言信息')
# 总页数
size = int(total/10 + 1)
# 已经读取的信息条数
use_page = 0
# 保存每条数据信息,生成csv文件用
content_arr = []
for i in range(0, size):
# 请求每一页的内容
resp_json = get_resp(cookie, g_tk, token, i)
# 当条数大于或等于总条数 跳出循环
if use_page >= total:
break
# 从每页数据中取出需要的字段值
for comment in resp_json['data']['commentList']:
use_page += 1
print(f'当前正在读取第{use_page}条')
page_json = []
# 留言日期
page_json.append(comment['pubtime'])
# 昵称
page_json.append(comment['nickname'])
# 内容
content = replace_html(comment['htmlContent'])
# 将内容写入文本 生成词云用
with open('zone_text111.txt', 'a') as f:
f.write(content) page_json.append(content)
content_arr.append(page_json)
生成csv文件
# 将总数据转化为data frame再输出
df = pd.DataFrame(data=content_arr,
columns=['留言日期', '昵称', '留言内容'])
df.to_csv('QQ_ZONE.csv', index=False, encoding='utf-8_sig')
print('已保存为csv文件.')
运行上面代码生成csv文件部分内容如下
生成词云(wordcloud)代码如下
from wordcloud import WordCloud
import matplotlib.pyplot as plt
with open('zone_text.txt','r') as f:
mytext = f.read() font = r'C:\Windows\Fonts\simfang.ttf'
wc = WordCloud(collocations=False, font_path=font, width=1400, height=1400, margin=2).generate(mytext)
plt.imshow(wc)
plt.axis("off")
plt.show() plt.show()
运行结果如下:

写在最后
上面的代码并没有太复杂,也许是触景生情,也许是对现在朋友圈各种乱七八糟的信息产生了抵触,所以试着去回忆青春的那些往事。
朋友圈和空间并不能去衡量一个人是是否成熟,但是对于大部分90后来说,空间真的是承载了太多纯真的回忆。不忘初心,砥砺前行!!!
公众号 程序员共成长 内回复【空间】,获取源代码
本文首发于公众号 程序员共成长 公众号内回复 [礼包] 即可领取优质资源,包括但不限于Java、Python、Linux、数据库、大数据、架构、测试、前端、ui以及各方向电子书

90后的青春,定格在被淡忘的QQ空间里的更多相关文章
- 一位90后的自述:如何从年薪3w到30w
作者介绍:90后生人/男/二本本科/世界500强技术主管 1.引言 上海小胖,曾就职于pwc(普华永道)担任TechLeader,带领DS(Data Scientist)团队完成全美医疗保险大数据项目 ...
- 一位90后程序员的自述:如何从年薪3w到30w
▌自我介绍 引用赵真老师的一首歌<过去不是错>中的一句话:过去不是过错,毕竟我们也开心过.过去不是过错,何必愧疚不知所措. 我们这一代人,我相信多少都会有人和我一样,坚持过一个游戏,叫 D ...
- 【转载】阎焱:90后创业是扯淡 大量O2O和P2P公司濒临倒闭
真正创业成功的大部分是年龄在30岁到38岁之间,很多90后基本什么都不懂.从历史来看,在这样的人口大国,集体性行为,无论是政治的还是经济的,基本都是导致灾难性后果. 10月14日消息,赛富基金创始首席 ...
- 月薪25K的90后程序员,他们都经历了什么?
如果说薪资是检验一家公司对程序员认可的标准,那么年纪轻轻就能达到月薪 25K,一定程度上说明了公司对他创造的价值的认可. 深访10+ 名月薪25K的程序员,发现他们最常见的三种成长途径是…… 在公司发 ...
- QQ市场总监分享:黏住90后的独门攻略
转自:http://www.gameres.com/476003.html 90后的关键词 1. 品质生活 90后是怎么样的一群人?他们注重生活的品质. 他们比我们更爱享受,或者说他们不像我们一样认为 ...
- 季逸超:90后IT少年的“盖茨梦”
2月15日,"90后"独立开发者季逸超在其微博称,个人获得徐小平和红杉资本投资,成立了Peak Labs--以贝尔和施乐为目标的实验室. 谁是季逸超?他现年20岁,曾单独一人做出猛 ...
- 一位90后程序员的自述:如何从年薪3w到30w!
初入职场之时,大多数人都应该考虑过这样的一个问题,如何找到一种实用,简化web流程的方法,在工作之中能有所提升和突破. 学好哪些?基础必须精通! 九层之塔,起于垒土;千里之行,始于足下.入门之前,这些 ...
- 90后iOS开发者的出路,如何规划30岁前的自己(程序员必修课)
前言: 最近发生了一些和我们没有直接关系但是有间接关系的事情.比如华为“清洗”高龄基层员工,比如游戏公司2号员工拿不到股份而离职.先不说事实到底如何,起码很多码农是心有戚戚焉. 最近一年多也发生了一些 ...
- 饿了么CTO张雪峰:允许90后的技术人员“浮躁“一点
编者按:今年4月,饿了么正式加入了阿里新零售战队,进一步加速其在本地生活市场的扩张速度.在创业9年的时间中,饿了么在外卖领域经历了真正的“从0到1”,尤其是在外卖平台的技术升级方面,越过了一个又一个的 ...
随机推荐
- Python 作用域, 局部与全局变量
全局与局部变量 在子程序(函数)中定义的变量称为局部变量, 在程序的一开始定义的变量称为全局变量 全局变量作用于整个程序, 局部变量作用域是定义该变量的子程序 当全局变量与局部变量重名时: 在定义局部 ...
- random.nextInt()与Math.random()基础用法
相关文章:关于Random(47)与randon.nextInt(100)的区别 1.来源 random.nextInt() 为 java.util.Random类中的方法: Random类中还提供各 ...
- 【bzoj2331】[SCOI2011]地板
题目链接: TP 题解: 分类讨论好烦啊! 0表示没有插头,1.2表示有插头,1表示接下来可以转弯,2表示接下来不能转弯,只能停在一个地方. 然后分类讨论: 插头状态 到达状态 0 0 2 2 | 1 ...
- bzoj 1592 dp
就是dp啊 f[i][j]表示到第i位,最后一位高度是j的最小花费 转移::f[i][j]=minn(f[i-1][k])+abs(a[i]-num[j]);(k<=j) #include< ...
- 【爆料】-《卧龙岗大学毕业证书》UOW一模一样原件
☞西悉尼大学毕业证书[微/Q:865121257◆WeChat:CC6669834]UC毕业证书/联系人Alice[查看点击百度快照查看][留信网学历认证&博士&硕士&海归&a ...
- vue中引入babel步骤
vue中引入babel步骤 vue项目中普遍使用es6语法,但有时我们的项目需要兼容低版本浏览器,这时就需要引入babel插件,将es6转成es5. 1.安装babel-polyfill插件 npm ...
- 【深度学习篇】---CNN和RNN结合与对比,实例讲解
一.前述 CNN和RNN几乎占据着深度学习的半壁江山,所以本文将着重讲解CNN+RNN的各种组合方式,以及CNN和RNN的对比. 二.CNN与RNN对比 1.CNN卷积神经网络与RNN递归神经网络直观 ...
- 基于Java实现红黑树的基本操作
首先,在阅读文章之前,我希望读者对二叉树有一定的了解,因为红黑树的本质就是一颗二叉树.所以本篇博客中不在将二叉树的增删查的基本操作了,需要了解的同学可以到我之前写的一篇关于二叉树基本操作的博客:htt ...
- 简述RPC原理实现
前言 架构的改变,往往是因为业务规模的扩张. 随着业务规模的扩张,为了满足业务对技术的要求,技术架构需要从单体应用架构升级到分布式服务架构,来降低公司的技术成本,更好的适应业务的发展. 分布式服务 ...
- Spark学习之编程进阶总结(二)
五.基于分区进行操作 基于分区对数据进行操作可以让我们避免为每个数据元素进行重复的配置工作.诸如打开数据库连接或创建随机数生成器等操作,都是我们应当尽量避免为每个元素都配置一次的工作.Spark 提供 ...