python 信息收集器和CMS识别脚本

前言:
信息收集是渗透测试重要的一部分
这次我总结了前几次写的经验,将其
进化了一下
正文:
信息收集脚本的功能:
1.端口扫描
2.子域名挖掘
3.DNS查询
4.whois查询
5.旁站查询
CMS识别脚本功能:
1.MD5识别CMS
2.URL识别CMS
原理:cms识别CMS将网站加一些CMS特有的路径获取到的源码
加密成md5与data.json对比如果是就是此种CMS。
URL+上CMS特有的路径,获取源码从中寻找data.json里的
re标签。如果有就是此种CMS
信息收集脚本代码:
import requests
import re
import socket
from bs4 import BeautifulSoup
import optparse def main():
parser=optparse.OptionParser()
parser.add_option('-p',dest='host',help='ip port scanner')
parser.add_option('-w',dest='whois',help='Whois query')
parser.add_option('-d',dest='dns',help='dns query')
parser.add_option('-z',dest='domain',help='Domain name query')
parser.add_option('-f',dest='fw',help='Bypass query')
(options,args)=parser.parse_args()
if options.host:
ip=options.host
portscanner(ip)
elif options.whois:
ws=options.whois
whois(ws)
elif options.dns:
dn=options.dns
dnsquery(dn)
elif options.domain:
domain=options.domain
domains(domain)
elif options.fw:
pz=options.fw
bypass(pz)
else:
parser.print_help()
exit()
def portscanner(ip):
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
socket.setdefaulttimeout(1)
for port in range(1,65535):
try:
s.connect((ip,port))
print('[+]',ip,':',port,'open')
except:
pass def whois(ws):
url = "http://whoissoft.com/{}".format(ws)
rest = requests.get(url=url)
csd = rest.content.decode('utf-8')
fsd = BeautifulSoup(csd, 'html.parser')
wsd = fsd.get_text()
comp = re.compile(
r'a:link, a:visited {.*? }|a:hover {.*?}|white-space: .*?;|font-family:.*?;|function\s+s|window.location.href\s+=\s+".*?"|return\s+false;| var _sedoq\s+=\s+_sedoq|_sedoq.partnerid\s+=\s+'''';| _sedoq.locale\s+=\s+''zh-cn'';|var\s+s\s+=\s+document.createElement|s.type\s+=\s+''text/javascript'';|s.async\s+=\s+true;|s.src\s+=\s+''.*?'';|var\s+f\s+=\s+document.getElementsByTagName|f.parentNode.insertBefore|/.*?/|pre\s+{|word-wrap:\s+break-word;|}|\s*\(str1\){|\s+\+\s+str1;|\s+\|\s+\|\|\s+{;|\s+\|\|\s+{;|_sedoq.partnerid|\s+=|''''|\s+'';|\s+enter\s+your\s+partner\s+id|_sedoq.locale\s+=\s+|zh-cn|language\s+locale|\(function\(\)\s+{|\[0\];|s.type|text/javascript|script|s,\s+f|document.getElementById\(.*?\)|.style.marginLeft|=window|\|\||\s+{|;|en-us,|en-uk,|de-de,|es-er-fr,|pt-br,|\s+.innerWidth2|es-|er-|fr|.innerWidth2|er|-,')
tih = re.sub(comp, "", wsd)
wrs = open('whois.txt', 'w')
wrs.write(tih)
wrs.close()
wrr = open('whois.txt', 'r')
rr = wrr.read()
xin = rr.replace("''", '')
xin2 = xin.replace("(", '')
xin3 = xin2.replace(")", '')
xin4 = xin3.replace("er-,", '')
xin5 = xin4.replace('.innWidth2+"px"', '')
xin6 = xin5.replace('window.onresize=function{', '')
xin7 = xin6.replace('.innWidth2+"px"', '')
print(xin7, end='')
def dnsquery(dn):
url = "https://jiexifenxi.51240.com/web_system/51240_com_www/system/file/jiexifenxi/get/?ajaxtimestamp=1526175925753"
headers = {
'user-agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16'}
params = {'q': '{}'.format(dn), 'type': 'a'}
reqst = requests.post(url=url, headers=headers, params=params)
content = reqst.content.decode('utf-8')
bd = BeautifulSoup(content, 'html.parser') print('---[+]A record---')
print(bd.get_text()) print('---[+]MX record---')
params2 = {'q': '{}'.format(dn), 'type': 'mx'}
rest = requests.post(url=url, headers=headers, params=params2)
content2 = BeautifulSoup(rest.content.decode('utf-8'), 'html.parser')
print(content2.get_text()) print('---[+]CNAME record---')
params3 = {'q': '{}'.format(dn), 'type': 'cname'}
rest2 = requests.post(url=url, headers=headers, params=params3)
content3 = BeautifulSoup(rest2.content.decode('utf-8'), 'html.parser')
print(content3.get_text()) print('---[+]NS record---')
params4 = {'q': '{}'.format(dn), 'type': 'ns'}
rest3 = requests.post(url=url, headers=headers, params=params4)
content4 = BeautifulSoup(rest3.content.decode('utf-8'), 'html.parser')
print(content4.get_text()) print('---[+]TXT record---')
params5 = {'q': '{}'.format(dn), 'type': 'txt'}
rest4 = requests.post(url=url, headers=headers, params=params5)
content5 = BeautifulSoup(rest4.content.decode('utf-8'), 'html.parser')
print(content5.get_text()) def domains(domain):
print('---[+]Domain name query---')
url = "http://i.links.cn/subdomain/"
headers = {'user-agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16'}
params = {'domain': '{}'.format(domain), 'b2': '', 'b3': '', 'b4': ''}
reqst = requests.post(url=url, headers=headers, params=params)
vd = reqst.content.decode('gbk')
rw = re.findall('<div class=domain><input type=hidden name=.*? id=.*? value=".*?">', vd)
rw2 = "".join(str(rw))
bwdw = BeautifulSoup(str(rw2), 'html.parser')
pw = bwdw.find_all('input')
for l in pw:
isd = l.get("value")
print(isd) def bypass(pz):
url = "http://www.webscan.cc/?action=query&ip={}".format(pz)
headers = {
'user-agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16'}
wd = requests.get(url=url, headers=headers)
rcy = wd.content.decode('utf-8')
res = re.findall('"domain":".*?"', str(rcy))
lis = "".join(res)
rmm = lis.replace('"', '')
rmm2 = rmm.replace(':', '')
rmm3 = rmm2.replace('/', '')
rmm4 = rmm3.replace('domain', '')
rmm5 = rmm4.replace('http', '')
print(rmm5) if __name__ == '__main__':
main()
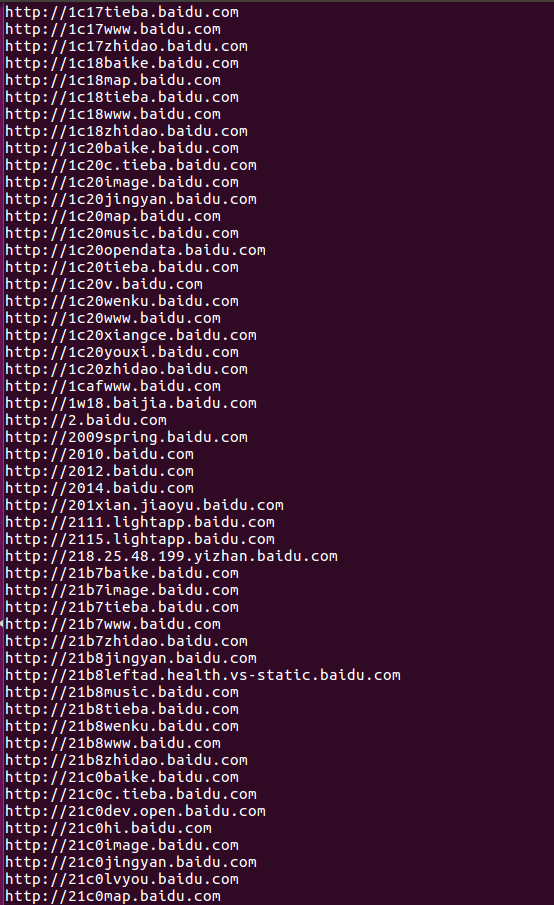
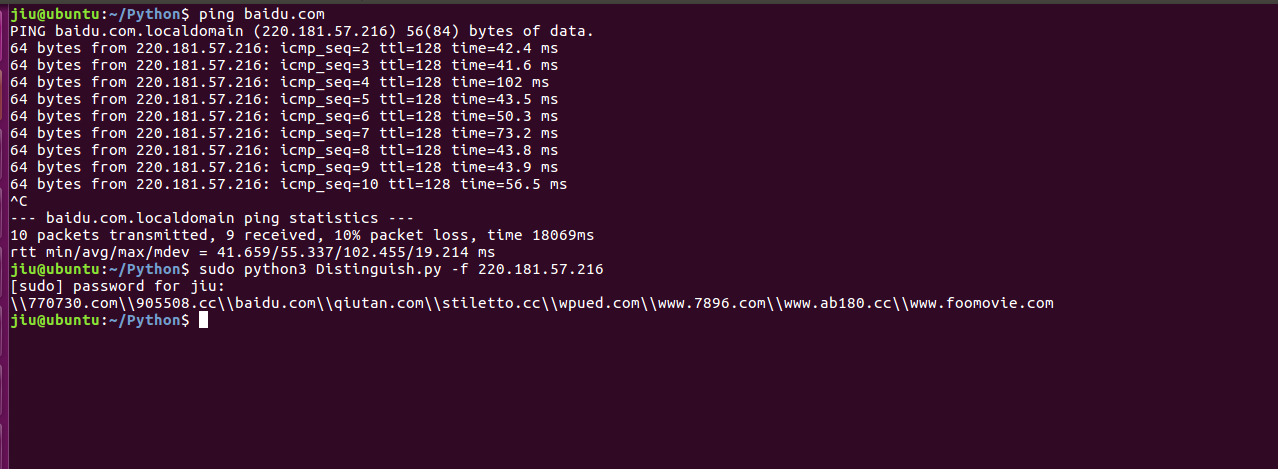
运行测试:
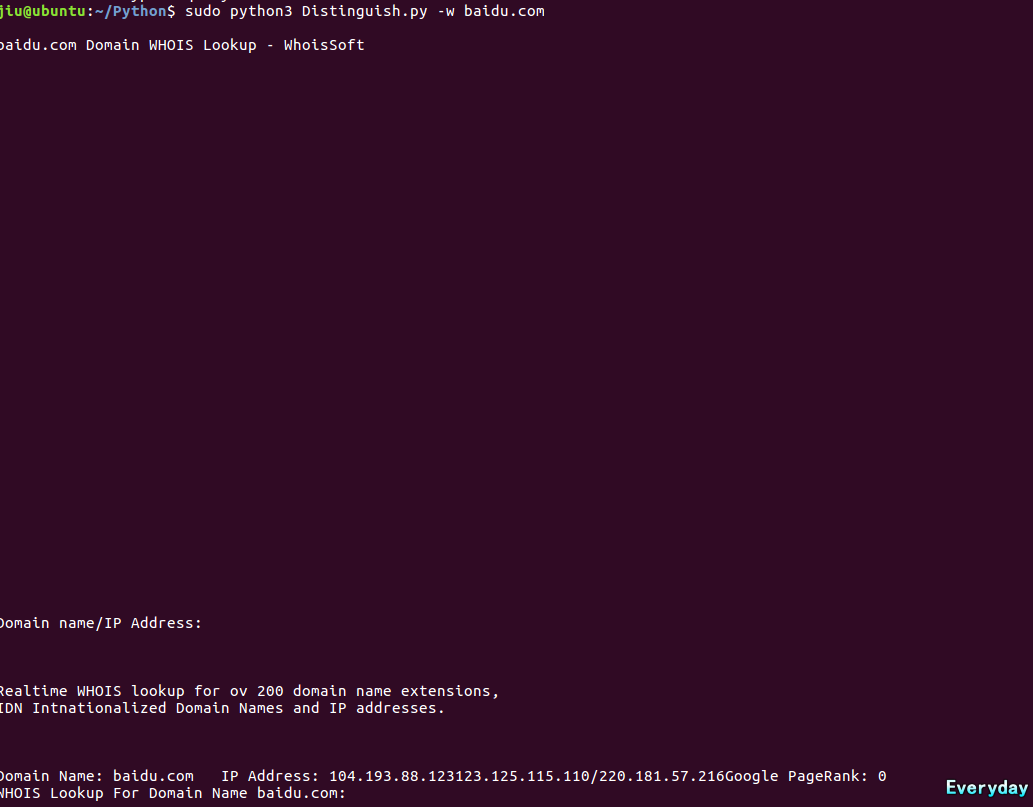
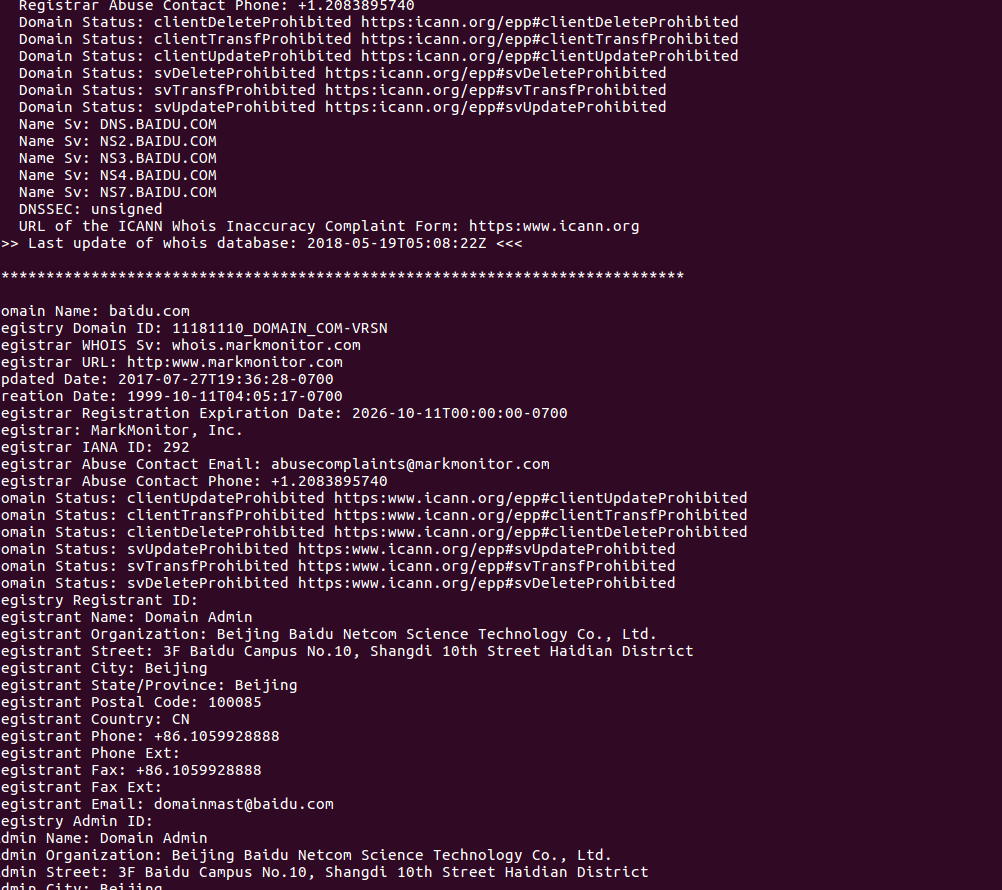
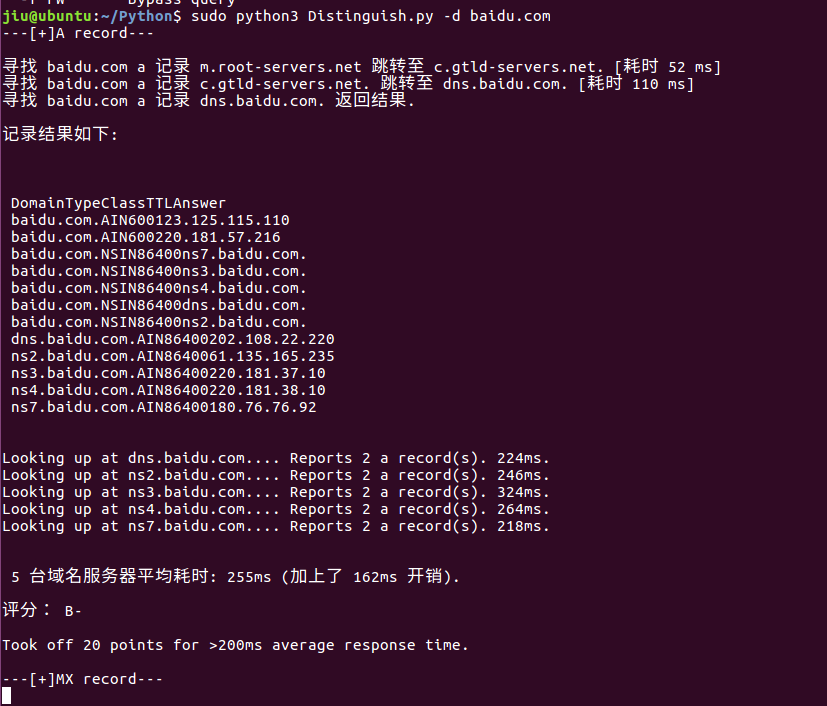
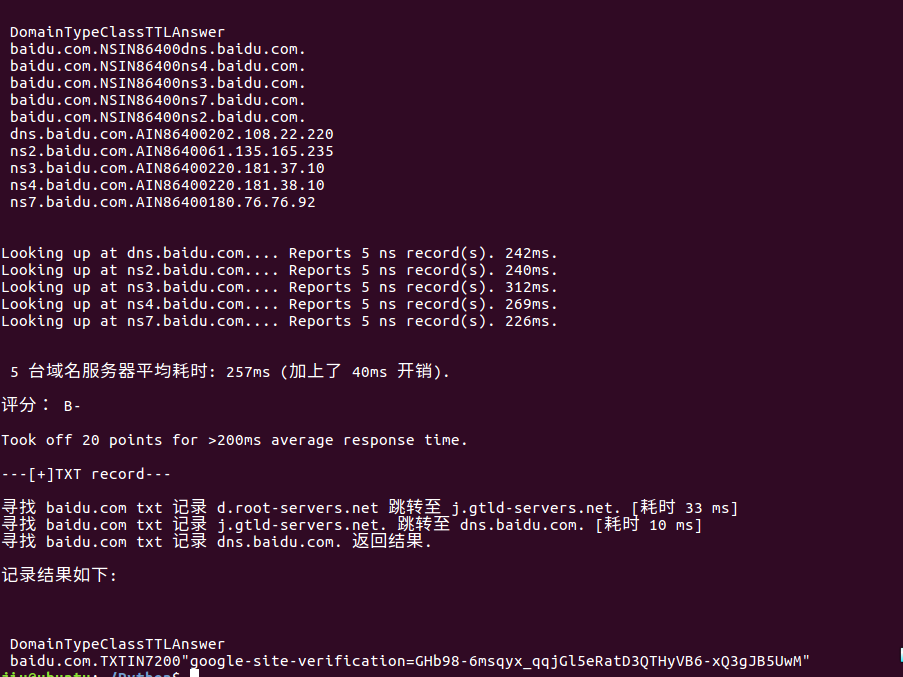

CMS脚本代码:
import requests
import json
import hashlib
import os
import optparse
def main():
usage="[-q MD5DE-CMS] " \
"[- p URL gets CMS]"
parser=optparse.OptionParser(usage)
parser.add_option('-q',dest='md5',help='md5 cms')
parser.add_option('-p',dest='url',help='url cms')
(options,args)=parser.parse_args()
if options.md5:
log=options.md5
panduan(log)
elif options.url:
log2=options.url
panduan2(log2)
else:
parser.print_help() def op():
global lr
if os.path.exists('data.json'):
print('[+]Existing data.json file')
js=open('data.json','r')
lr=json.load(js,encoding='utf-8')
else:
print('[-]Not data.json')
exit() op() def panduan(log):
global headers
headers={'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36'}
for b in lr:
url = log.rstrip('/') + b["url"]
rest = requests.get(url=url, headers=headers, timeout=5)
text = rest.text
if rest.status_code != 200:
print('[-]Not Found 200', rest.url)
md5=hashlib.md5()
md5.update(text.encode('utf-8'))
g=md5.hexdigest()
print(g)
if g == b["md5"]:
print("[+]CMS:",b["name"],"url:",b["url"])
print("[+]CMS:",b["name"],"url:",b["url"],file=open('cms.txt','w'))
else:
print('[-]not md5:',b["md5"]) def panduan2(log2):
for w in lr:
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36'}
url = log2.rstrip('/') + w["url"]
rest=requests.get(url=url,headers=headers,timeout=5)
text=rest.text
if rest.status_code !=200:
pass
if w["re"]:
if(text.find(w["re"]) != -1):
print('[+]CMS:',w["name"],"url:",w["url"])
print('[+]CMS:', w["name"], "url:", w["url"],file=open('cms.txt','w')) if __name__ == '__main__':
main()
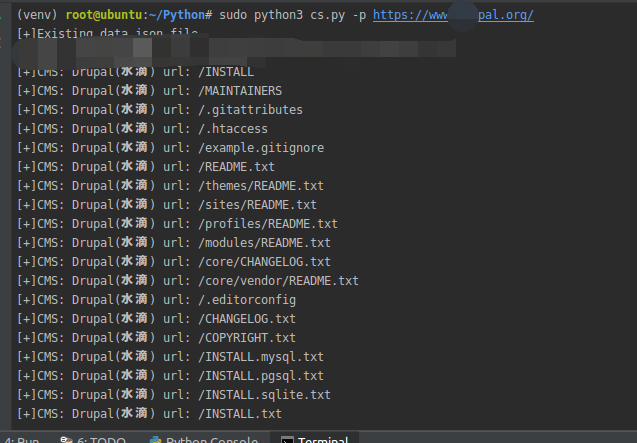
识别测试:
python 信息收集器和CMS识别脚本的更多相关文章
- python信息收集之子域名
python信息收集之子域名 主要是以下3种思路: 字典爆破 搜索引擎 第三方网站 0x00 背景知识 list Python内置的一种数据类型是列表:list是一种有序的集合. >>&g ...
- python信息收集(一)
在渗透测试初期,需要进行大量的信息收集.一般情况下,信息收集可以分为两大类----被动信息收集和主动信息收集. 其中,被动信息收集主要是通过各种公开的渠道来获取目标系统的信息,例如:站 ...
- python写一个简单的CMS识别
前言: 收集了一点cms路径,打算在写一个.之前已经写了 有需要的可以自己翻我的博客 思路: 网站添加路径判断是否为200,并且无过滤列表中的字符 代码: import requests import ...
- Python黑客——快速编写信息收集器
i春秋作家:大木瓜 环境:Python 3模块:LxmlRequestBeautifulsoup开始:首先看一下目标站: http://gaokao.chsi.com.cn/gkxx/zszcgd/d ...
- python信息收集(二)
在第二层主机发现中,除了使用arping命令外,还可以使用Kali下自带的一个工具----netdiscover. netdiscover是一个专门用于二层主机发现的工具,它有两种扫 ...
- python信息收集(四)
在前三篇中,我们介绍了使用python脚本发现二层.三层的主机设备,接下来我们介绍使用python发现第四层主机. 在TCP/IP协议中,第四层为传输层,主要使用的通信协议为TCP协议 ...
- python信息收集(三)
前两篇介绍了利用python编写一些脚本实现二层主机的发现,这一篇介绍一下三层主机的发现. 一般来说,三层主机的发现主要是通过ICMP协议来实现的.其中ICMP协议中的ping命令可以 ...
- 垃圾收集器之:CMS收集器
HotSpot JVM的并发标记清理收集器(CMS收集器)的主要目标就是:低应用停顿时间.该目标对于大多数交互式应用很重要,比如web应用.在我们看一下有关JVM的参数之前,让我们简要回顾CMS收集器 ...
- JVM实用参数(七)CMS收集器
HotSpot JVM的并发标记清理收集器(CMS收集器)的主要目标就是:低应用停顿时间.该目标对于大多数交互式应用很重要,比如web应用.在我们看一下有关JVM的参数之前,让我们简要回顾CMS收集器 ...
随机推荐
- 插件化开发—动态加载技术加载已安装和未安装的apk
首先引入一个概念,动态加载技术是什么?为什么要引入动态加载?它有什么好处呢?首先要明白这几个问题,我们先从 应用程序入手,大家都知道在Android App中,一个应用程序dex文件的方法数最大不能超 ...
- OpenCV分通道显示图片,灰度,融合,直方图,彩色直方图
代码有参考跟整合:没有一一列出出处 // split_rgb.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include <io ...
- ubuntu下搭建gtk+编程环境
首先gtk+项目主页为: http://www.gtk.org/ gtk+现在有2和3两种版本,使用 sudo apt-get install gnome-core-devel 可以一次性安装2个版本 ...
- Gradle 1.12用户指南翻译——第四十三章. 构建公告插件
本文由CSDN博客貌似掉线翻译,其他章节的翻译请参见: http://blog.csdn.net/column/details/gradle-translation.html 翻译项目请关注Githu ...
- SDWebimage的原理和使用机制
对于ASIHttp请求和AFNetworking请求都有关于图片缓存机制的使用,但是相对于专注运用在图片使用的SDWebimage来说,又有不一样的使用效果,最主要的体现在缓存数据的转换. SDWeb ...
- OpenCV x64 vs2010 下打开摄像头录制视频写成avi(代码为转载)
首先参照下面这里进行opencv x64位机器下面的配置 http://wiki.opencv.org.cn/index.php/VC_2010%E4%B8%8B%E5%AE%89%E8%A3%85O ...
- MATLAB坐标系中绘制图片
MATLAB坐标系中绘制图片 方法一 使用图片坐标循环的方式,代码如下. clear,clc,close all tic; map=imbinarize(imread('map.bmp'));%map ...
- 【redis】Java连接云服务器redis之JedisConnectionException的异常问题
代码很简单: public static void main(String[] args) { Jedis jedis = new Jedis("116.85.10.216",63 ...
- JavaScript设计模式之一封装
对于熟悉C#和Java的兄弟们,面向对象的三大思想(封装,继承,多态)肯定是了解的,今天我想讲讲如何在Javascript中利用封装这个特性,开讲! 我们会把现实中的一些事物抽象成一个Class并且把 ...
- LOVO学习之思维导图和文档编辑器
思维导图——是一种图示笔记方法,一种图示笔记工具,一个思考的利器.能将放射性思考具体化,帮助人们理解和记忆事物. 思维导图绘制规则:1,在纸的正中央用一个彩色图像或者符号开始画思维导图. 2,把所有主 ...