第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目
下载地址:https://github.com/scrapy/scrapyd
建议安装
pip3 install scrapyd
首先安装scrapyd模块,安装后在Python的安装目录下的Scripts文件夹里会生成scrapyd.exe启动文件,如果这个文件存在说明安装成功,我们就可以执行命令了
启动scrapyd服务
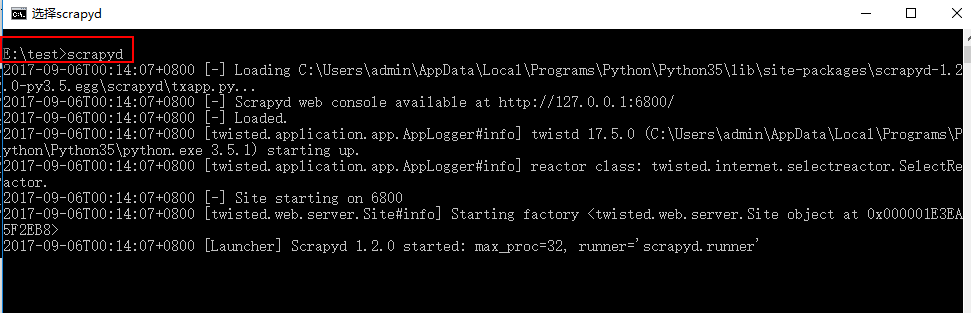
在命令输入:scrapyd

如图说明启动成功,关闭或者退出命令窗口,因为我们正真的使用是在指定的启动目录下启动服务的
指定启动服务目录后启动服务
重新打开命令,cd进入要指定服务的目录后,执行命令scrapyd启动服务
此时可以看到启动目录里生成了dbs目录

dbs目录里是空的什么都没有
此时我们需要安装scrapyd-client模块
scrapyd-client模块是专门打包scrapy爬虫项目到scrapyd服务中的
下载目录:https://github.com/scrapy/scrapyd-client
建议安装
pip3 install scrapyd-client
安装后在Python的安装目录下的Scripts文件夹里会生成scrapyd-deploy无后缀文件,如果有此文件说明安装成功
重点说明:这个scrapyd-deploy无后缀文件是启动文件,在Linux系统下可以远行,在windows下是不能远行的,所以我们需要编辑一下使其在windows可以远行

在此目录里新建一个scrapyd-deploy.bat文件,注意名称一定要和scrapyd-deploy相同,我们编辑这个bat文件使其在windows可以远行
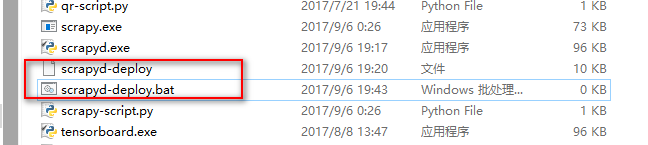
scrapyd-deploy.bat文件编辑
设置python执行文件路径和scrapyd-deploy无后缀文件路径
@echo off
"C:\Users\admin\AppData\Local\Programs\Python\Python35\python.exe" "C:\Users\admin\AppData\Local\Programs\Python\Python35\Scripts\scrapyd-deploy" %1 %2 %3 %4 %5 %6 %7 %8 %9
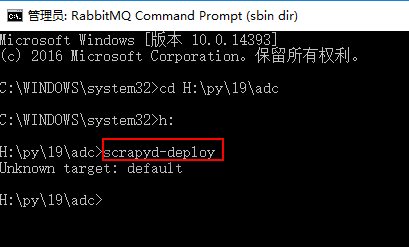
scrapyd-deploy.bat文件编辑好后,打开命令窗口cd 到scrapy项目中有scrapy.cfg文件的目录,然后执行scrapyd-deploy命令,看看我们编辑的scrapyd-deploy.bat文件是否可以执行
如果下图表示可以执行
设置scrapy项目中的scrapy.cfg文件,这个文件就是给scrapyd-deploy使用的
scrapy.cfg文件
注意:下面的中文备注不能写在里面,不然会报错,这写的备注只是方便知道怎么设置
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.org/en/latest/deploy.html [settings]
default = adc.settings [deploy:bobby] #设置部署名称bobby
url = http://localhost:6800/ #开启url
project = adc #项目名称
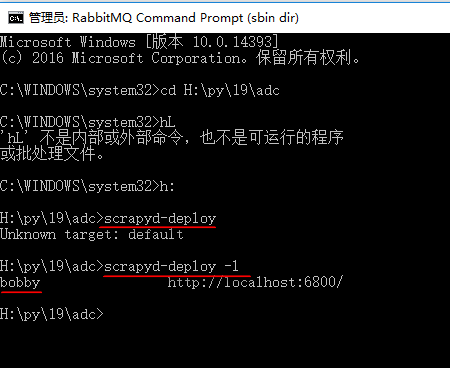
命令窗口输入:scrapyd-deploy -l 启动服务,可以看到我们设置的部署名称
开始打包前,执行一个命令:scrapy list ,这个命令执行成功说明可以打包了,如果没执行成功说明还有工作没完成
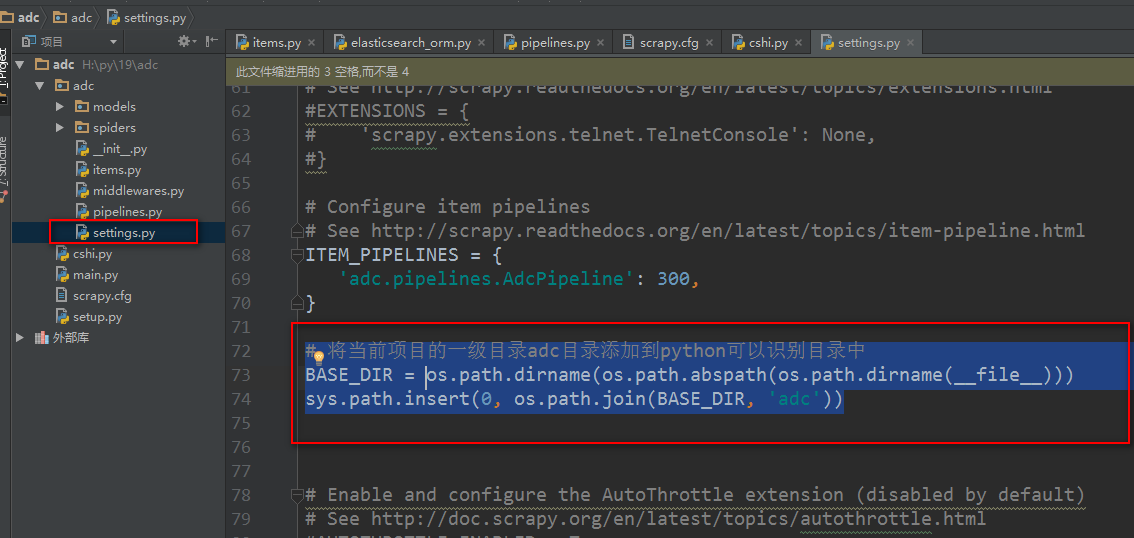
注意执行 scrapy list 命令的时候很有可能出现错误,如果是python无法找到scrapy项目,需要在scrapy项目里的settings.py配置文件里设置成python可识别路径
# 将当前项目的一级目录adc目录添加到python可以识别目录中
BASE_DIR = os.path.dirname(os.path.abspath(os.path.dirname(__file__)))
sys.path.insert(0, os.path.join(BASE_DIR, 'adc'))
如果错误提示,什么远程计算机拒绝,说明你的scrapy项目有链接远程计算机,如链接数据库或者elasticsearch(搜索引擎)之类的,需要先将链接服务器启动
执行 scrapy list 命令返回了爬虫名称说明一切ok了,如下图

到此我们就可以开始打包scrapy项目到scrapyd了,用命令结合scrapy项目中的scrapy.cfg文件设置来打包
scrapy.cfg文件
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.org/en/latest/deploy.html [settings]
default = adc.settings [deploy:bobby] #设置部署名称bobby
url = http://localhost:6800/ #开启url
project = adc #项目名称
执行打包命令: scrapyd-deploy 部署名称 -p 项目名称
如:scrapyd-deploy bobby -p adc
如下显示表示scrapy项目打包成功

scrapy项目打包成功后说明
scrapy项目打包成功后会在scrapyd启动服务的目录生成相应的文件,如下:
1、会在scrapyd启动服务的目录下的dbs文件夹生成scrapy项目名称.db

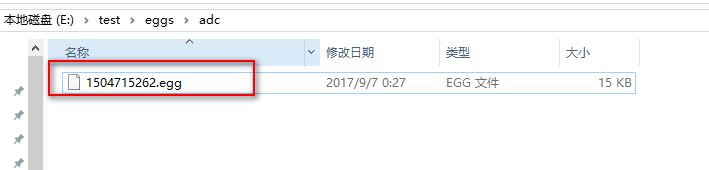
2、会在scrapyd启动服务的目录下的eggs文件夹生成scrapy项目名称的文件夹,里面是一个scrapyd-deploy打包生成的名称.egg
3、会将scrapy爬虫项目打包,在scrapy项目里会生成两个文件夹,build文件夹和project.egg-info文件夹
build文件夹里是打包后的爬虫项目,scrapyd以后远行的就是这个打包后的项目
project.egg-info文件夹里是打包时的一些配置
说明:scrapyd-deploy只负责将scrapy爬虫项目打包给scrapyd部署,只需要打包一次,打包后,以后的启动爬虫,停止爬虫等scrapy项目管理由scrapyd来完成
scrapyd管理scrapy项目
注意:scrapyd管理用的 curl 命令,curl命令不支持windows系统,只支持Linux系统,所以在windows系统下我们用cmder来执行命令
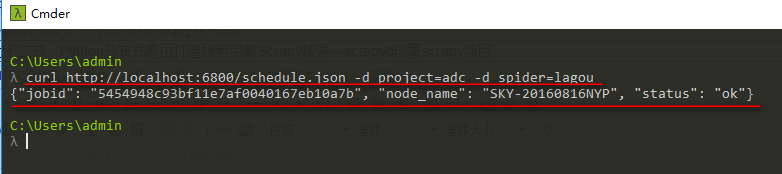
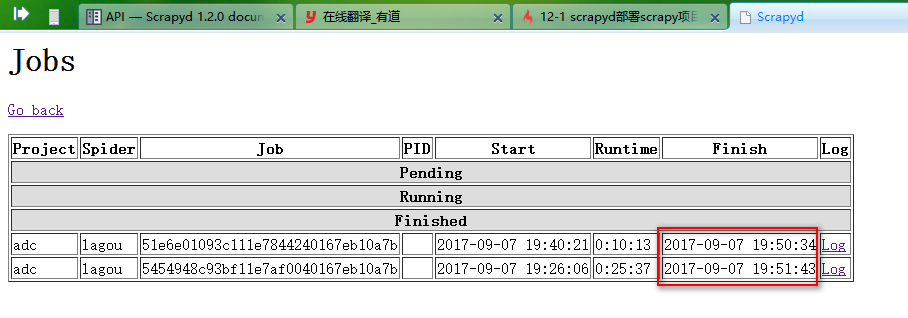
1、远行爬虫,远行指定scrapy下面的指定爬虫
curl http://localhost:6800/schedule.json -d project=scrapy项目名称 -d spider=爬虫名称
如:
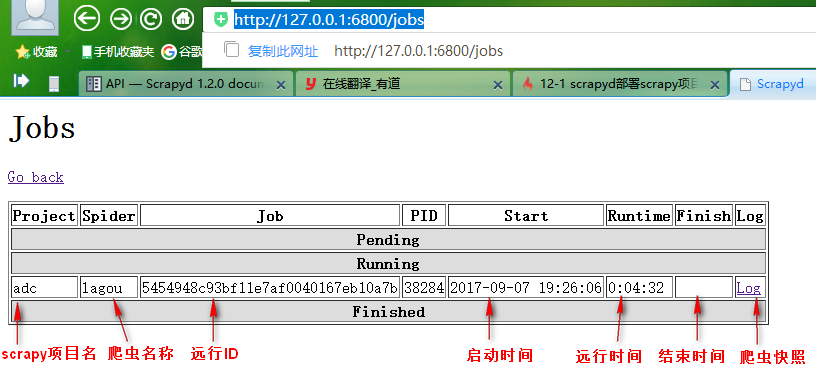
curl http://localhost:6800/schedule.json -d project=adc -d spider=lagou
2、停止爬虫
curl http://localhost:6800/cancel.json -d project=scrapy项目名称 -d job=远行ID
如:
curl http://localhost:6800/cancel.json -d project=adc -d job=5454948c93bf11e7af0040167eb10a7b

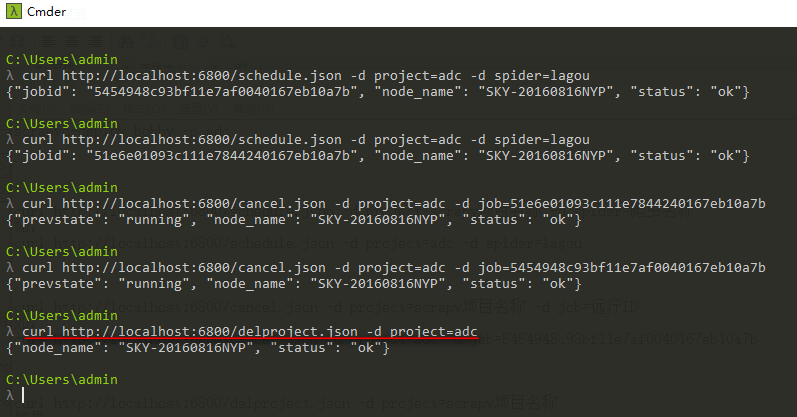
3、删除scrapy项目
注意:一般删除scrapy项目,需要先执行命令停止项目下在远行的爬虫
删除项目后会删除scrapyd启动服务的目录下的eggs文件夹生成egg文件,需要重新用scrapyd-deploy打包后才能再次运行
curl http://localhost:6800/delproject.json -d project=scrapy项目名称
如果:
curl http://localhost:6800/delproject.json -d project=adc
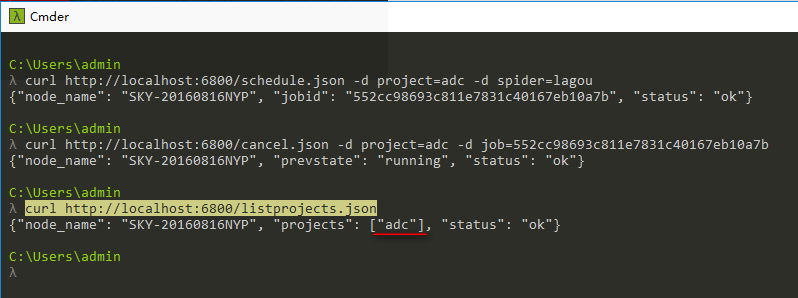
4、查看有多少个scrapy项目在api中
curl http://localhost:6800/listprojects.json
5、查看指定的scrapy项目中有多少个爬虫
curl http://localhost:6800/listspiders.json?project=scrapy项目名称
如:
curl http://localhost:6800/listspiders.json?project=adc

scrapyd支持的API 介绍
scrapyd支持一系列api,下面用一个py文件来介绍
# -*- coding: utf-8 -*- import requests
import json baseUrl ='http://127.0.0.1:6800/'
daemUrl ='http://127.0.0.1:6800/daemonstatus.json'
listproUrl ='http://127.0.0.1:6800/listprojects.json'
listspdUrl ='http://127.0.0.1:6800/listspiders.json?project=%s'
listspdvUrl= 'http://127.0.0.1:6800/listversions.json?project=%s'
listjobUrl ='http://127.0.0.1:6800/listjobs.json?project=%s'
delspdvUrl= 'http://127.0.0.1:6800/delversion.json' #http://127.0.0.1:6800/daemonstatus.json
#查看scrapyd服务器运行状态
r= requests.get(daemUrl)
print '1.stats :\n %s \n\n' %r.text #http://127.0.0.1:6800/listprojects.json
#获取scrapyd服务器上已经发布的工程列表
r= requests.get(listproUrl)
print '1.1.listprojects : [%s]\n\n' %r.text
if len(json.loads(r.text)["projects"])>0 :
project = json.loads(r.text)["projects"][0] #http://127.0.0.1:6800/listspiders.json?project=myproject
#获取scrapyd服务器上名为myproject的工程下的爬虫清单
listspd=listspd % project
r= requests.get(listspdUrl)
print '2.listspiders : [%s]\n\n' %r.text
if json.loads(r.text).has_key("spiders")>0 :
spider =json.loads(r.text)["spiders"][0] #http://127.0.0.1:6800/listversions.json?project=myproject
##获取scrapyd服务器上名为myproject的工程下的各爬虫的版本
listspdvUrl=listspdvUrl % project
r = requests.get(listspdvUrl)
print '3.listversions : [%s]\n\n' %rtext
if len(json.loads(r.text)["versions"])>0 :
version = json.loads(r.text)["versions"][0] #http://127.0.0.1:6800/listjobs.json?project=myproject
#获取scrapyd服务器上的所有任务清单,包括已结束,正在运行的,准备启动的。
listjobUrl=listjobUrl % proName
r=requests.get(listjobUrl)
print '4.listjobs : [%s]\n\n' %r.text #schedule.json
#http://127.0.0.1:6800/schedule.json -d project=myproject -d spider=myspider
#启动scrapyd服务器上myproject工程下的myspider爬虫,使myspider立刻开始运行,注意必须以post方式
schUrl = baseurl + 'schedule.json'
dictdata ={ "project":project,"spider":spider}
r= reqeusts.post(schUrl, json= dictdata)
print '5.1.delversion : [%s]\n\n' %r.text #http://127.0.0.1:6800/delversion.json -d project=myproject -d version=r99'
#删除scrapyd服务器上myproject的工程下的版本名为version的爬虫,注意必须以post方式
delverUrl = baseurl + 'delversion.json'
dictdata={"project":project ,"version": version }
r= reqeusts.post(delverUrl, json= dictdata)
print '6.1.delversion : [%s]\n\n' %r.text #http://127.0.0.1:6800/delproject.json -d project=myproject
#删除scrapyd服务器上myproject工程,注意该命令会自动删除该工程下所有的spider,注意必须以post方式
delProUrl = baseurl + 'delproject.json'
dictdata={"project":project }
r= reqeusts.post(delverUrl, json= dictdata)
print '6.2.delproject : [%s]\n\n' %r.text
总结一下:
http://127.0.0.1:6800/listprojects.json
3、获取项目下已发布的爬虫列表
4、获取项目下已发布的爬虫版本列表
5、获取爬虫运行状态
6、启动服务器上某一爬虫(必须是已发布到服务器的爬虫)
http://localhost:6800/schedule.json (post方式,data={"project":myproject,"spider":myspider})
7、删除某一版本爬虫
到此,基于scrapyd的爬虫发布教程就写完了。
可能有人会说,我直接用scrapy cwal 命令也可以执行爬虫,个人理解用scrapyd服务器管理爬虫,至少有以下几个优势:
1、可以避免爬虫源码被看到。
2、有版本控制。
3、可以远程启动、停止、删除,正是因为这一点,所以scrapyd也是分布式爬虫的解决方案之一。
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目的更多相关文章
- 第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理
第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理 网站树形结构 深度优先 是从左到右深度进行爬取的,以深度为准则从左到右的执行(递归方式实现)Scrapy默认 ...
- 五十一 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:https://github.com/scrapy/scrapyd 建议安装 pip3 install s ...
- 第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门 我的搜素简单实现原理我们可以用js来实现,首先用js获取到 ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
- 第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作.增.删.改.查 elasticsearch(搜索引擎)基本的索引 ...
- 第三百五十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—chrome谷歌浏览器无界面运行、scrapy-splash、splinter
第三百五十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—chrome谷歌浏览器无界面运行.scrapy-splash. splinter 1.chrome谷歌浏览器无界面运行 chrome ...
- 第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码 scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开 ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能
第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—用Django实现搜索的自动补全功能 elasticsearch(搜索引擎)提供了自动补全接口 官方说明:https://www.e ...
随机推荐
- 定义log_query_time的值
默认超过10秒的sql才会被记录在慢查询日志里.可以通过long_query_time控制.如果是临时修改:set global long_query_time=4;(把超过4秒的sql记录到慢查询日 ...
- android studio - No compatible file types found
今天在使用AS新建一个C++类时候,输完了类名,对话框却显示下面的提示,一直不知道为什么 [解决方案] 在app目录下的build.gradle文件中添加下列代码: externalNativeBui ...
- tcp拥堵算法
http://m.blog.csdn.net/article/details?id=6739189
- nginx 并发数问题思考:worker_connections,worker_processes与 max clients
我相信,很多人都跟我一样,看书都不会太细致也不太认真思考,感觉书中讲的东西都应该是对的,最近读书时我发现以前认为理所当然的东西事实上压根都没有弄明白,最终的结果是,书是别人的,书中的知识也是别人的. ...
- 每日英语:Auto Makers Accelerate Efforts to Develop Self-Driving Cars
Big auto makers are steering their efforts to develop cars that drive themselves out of the labs and ...
- ExecutorService-10个要诀和技巧【转】
http://ifeve.com/executorservice-10-tips-and-tricks/
- spring boot spring cache ehcache3.x整合
http://blog.csdn.net/qq18998401056/article/details/53467671 **************************************** ...
- Python 调用datetime或者time获取时间的时候以及时间转换,最好设置一下时区 否则会出现相差8个小时的情况
在使用调用datetime或者time获取时间的时候以及时间转换,最好设置一下时区, 因为不同机器设置的时区不同,获取的时间可能就不对,正好我们使用的这两个服务器使用的都是东八区,所以没有问题,设置方 ...
- eclipse Maven 使用记录 ------ 建立 webapp项目
maven 建立 webapp 项目 有2种方式 , 1.在原先app上转换为webapp项目 2.建立maven项目的时候 filter 选择webapp 该选项把webapp文件目录建好,其 ...
- 《Android 编程权威指南》读书总结
1.当一段代码被多次使用,可将这段代码封装成一个抽象类,以后再要用到该段代码时,直接extends(继承)这个抽象类. 2.SDK版本向后兼容,即在SDK发布后推出的Android版本都可以使用该SD ...