数据分析与挖掘 - R语言:K-means聚类算法
一个简单的例子!
环境:CentOS6.5
Hadoop集群、Hive、R、RHive,具体安装及调试方法见博客内文档。
1、分析题目
--有一个用户点击数据样本(husercollect)
--按用户访问的时间(时)统计
--要求:分析时间和点击次数的聚类情况
2、数据准备
--创建临时表
DROP TABLE if exists tmp.t2_collect;
CREATE TABLE tmp.t2_collect(
h int,
cnt int
) COMMENT '用户点击数据临时表'; --插入临时表
insert overwrite table tmp.t2_collect
--分组
select a1.h, count(1) as cnt from(
--取出时
select hour(createtime) as h from bdm.husercollect
)a1
group by a1.h;
3、评估K值
#!/usr/bin/Rscript
library(RHive)
rhive.connect(host ='192.168.107.82')
data <- rhive.query('select h,cnt from tmp.t2_collect limit 6000')
x <- data$h
y <- data$cnt --组合成数据框
df <- data.frame(x, y)
--添加列名
colnames(df) <- c("hour", "cnt") --cluster.stats函数需要使用fpc库
library(fpc) --k取2到8评估K
K <- 2:8
--每次迭代30次,避免局部最优
round <- 30
rst <- sapply(K, function(i){
print(paste("K=",i))
mean(sapply(1:round,function(r){
print(paste("Round",r))
result <- kmeans(df, i)
stats <- cluster.stats(dist(df), result$cluster)
stats$avg.silwidth
}))
}) --加载图形库
library(Cairo)
png("k-points-pic.png", width=800, height=600)
plot(K, rst, type='l', main='outline & R relation', ylab='outline coefficient') dev.off()
rhive.close()
评估结果:
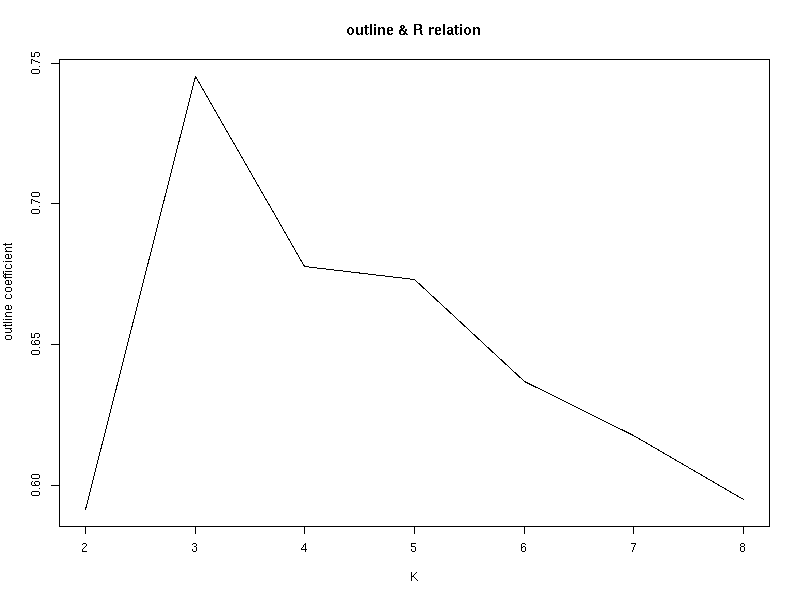
由上图可见当K=3时,轮廓系数最大。
4、聚类分析
#!/usr/bin/Rscript
library(RHive)
rhive.connect(host ='192.168.107.82')
data <- rhive.query('select h,cnt from tmp.t2_collect limit 6000')
x <- data$h
y <- data$cnt --组合成数据框
df <- data.frame(x, y)
--添加列名
colnames(df) <- c("hour", "cnt") --Kmeans
kc <- kmeans(df, 3); --具体分类情况
--fitted(kc); library(Cairo)
png("k-means-pic.png", width=800, height=600)
plot(df[c("hour", "cnt")], col = kc$cluster, pch = 8);
points(kc$centers[,c("hour", "cnt")], col = 1:3, pch = 8, cex=2); dev.off()
rhive.close()
聚类结果:

至此,一个简单的K-means聚类算法实例完成!
数据分析与挖掘 - R语言:K-means聚类算法的更多相关文章
- 零基础数据分析与挖掘R语言实战课程(R语言)
随着大数据在各行业的落地生根和蓬勃发展,能从数据中挖金子的数据分析人员越来越宝贝,于是很多的程序员都想转行到数据分析, 挖掘技术哪家强?当然是R语言了,R语言的火热程度,从TIOBE上编程语言排名情况 ...
- 数据分析与挖掘 - R语言:贝叶斯分类算法(案例一)
一个简单的例子!环境:CentOS6.5Hadoop集群.Hive.R.RHive,具体安装及调试方法见博客内文档. 名词解释: 先验概率:由以往的数据分析得到的概率, 叫做先验概率. 后验概率:而在 ...
- 数据分析与挖掘 - R语言:KNN算法
一个简单的例子!环境:CentOS6.5Hadoop集群.Hive.R.RHive,具体安装及调试方法见博客内文档. KNN算法步骤:需对所有样本点(已知分类+未知分类)进行归一化处理.然后,对未知分 ...
- 数据分析与挖掘 - R语言:多元线性回归
一个简单的例子!环境:CentOS6.5Hadoop集群.Hive.R.RHive,具体安装及调试方法见博客内文档. 线性回归主要用来做预测模型. 1.准备数据集: X Y 0.10 42.0 0.1 ...
- 数据分析与挖掘 - R语言:贝叶斯分类算法(案例三)
案例三比较简单,不需要自己写公式算法,使用了R自带的naiveBayes函数. 代码如下: > library(e1071)> classifier<-naiveBayes(iris ...
- 数据分析与挖掘 - R语言:贝叶斯分类算法(案例二)
接着案例一,我们再使用另一种方法实例一个案例 直接上代码: #!/usr/bin/Rscript library(plyr) library(reshape2) #1.根据训练集创建朴素贝叶斯分类器 ...
- 【机器学习与R语言】11- Kmeans聚类
目录 1.理解Kmeans聚类 1)基本概念 2)kmeans运作的基本原理 2.Kmeans聚类应用示例 1)收集数据 2)探索和准备数据 3)训练模型 4)评估性能 5)提高模型性能 1.理解Km ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- 基于R语言的梯度推进算法介绍
通常来说,我们可以从两个方面来提高一个预测模型的准确性:完善特征工程(feature engineering)或是直接使用Boosting算法.通过大量数据科学竞赛的试炼,我们可以发现人们更钟爱于Bo ...
随机推荐
- css案例 - mask遮罩层的华丽写法
mask遮罩蒙层使用通常的写法的bug 通常写法pug .mask 通常写法css .mask{ position: absolute; top: 0; right: 0; bottom: 0; le ...
- sass - 公用方法封装
// 设置宽高 @mixin wh($wid,$hei){ @if $wid { width: $wid; } @if $hei { height: $hei; } overflow: hidden; ...
- Calling a Java Method from Native Code
http://journals.ecs.soton.ac.uk/java/tutorial/native1.1/implementing/method.html Calling Java Method ...
- Elasticsearch学习之深入聚合分析五---案例实战
1. fielddata核心原理 fielddata加载到内存的过程是lazy加载的,对一个analzyed field执行聚合时,才会加载,而且是field-level加载的,一个index的一个f ...
- Windows平台编译memcached 1.2.6
两个项目libevent.memcached,Platform Toolset使用Visual Studio 2013 - Windows XP (v120_xp).在编译memcached时会提示& ...
- SIM900A基站定位调试笔记 -转
第1步:ATE1 握手并设置回显 第2步:AT+CGMR 查看SIM900的版本信号 第3步:AT+CSQ 查看信号质量 第4步:AT+CREG? 查看GSM是否注册成功 第5步:AT+CGREG? ...
- mysql补充(2)常用sql语句
补充:MySQL数据库 详解 常用的Mysql数据库操作语句大全 1.连接Mysql 格式: mysql -h主机地址 -u用户名 -p用户密码 1.连接到本机上的MYSQL.首先打开DOS窗口,然后 ...
- nginx socket转发设置
1.添加依赖模块,如下 --with-stream --with-stream_ssl_module 2.nginx.conf 配置,参考说明:ngx_stream_core_module user ...
- PHP生成页面二维码解决办法?详解
随着科技的进步,二维码应用领域越来越广泛,今天我给大家分享下如何使用PHP生成二维码,以及如何生成中间带LOGO图像的二维码. 具体工具: phpqrcode.php内库:这个文件可以到网上下载,如果 ...
- CvArr* to cv::Mat 转换
OpenCV中的CvArr*的定义的一个空类型的指针,可以转换为其派生类CvMat和IplImage,那么如何将其转化为cv::Mat呢,其实很简单,只需要一行代码即可: // CvArr *_img ...