Splunk Enterprise architecture——转发器本质上是日志收集client附加负载均衡,indexer是分布式索引,外加一个集中式管理协调的中心节点
Splunk Enterprise architecture and processes
This topic discusses the internal architecture and processes of Splunk Enterprise at a high level. If you're looking for information about third-party components used in Splunk Enterprise, see the credits section in the Release notes.
Splunk Enterprise Processes
A Splunk Enterprise server installs a process on your host, splunkd.
splunkd is a distributed C/C++ server that accesses, processes and indexes streaming IT data. It also handles search requests. splunkd processes and indexes your data by streaming it through a series of pipelines, each made up of a series of processors.
- Pipelines are single threads inside the
splunkdprocess, each configured with a single snippet of XML. - Processors are individual, reusable C or C++ functions that act on the stream of IT data that passes through a pipeline. Pipelines can pass data to one another through queues.
Architecture diagram
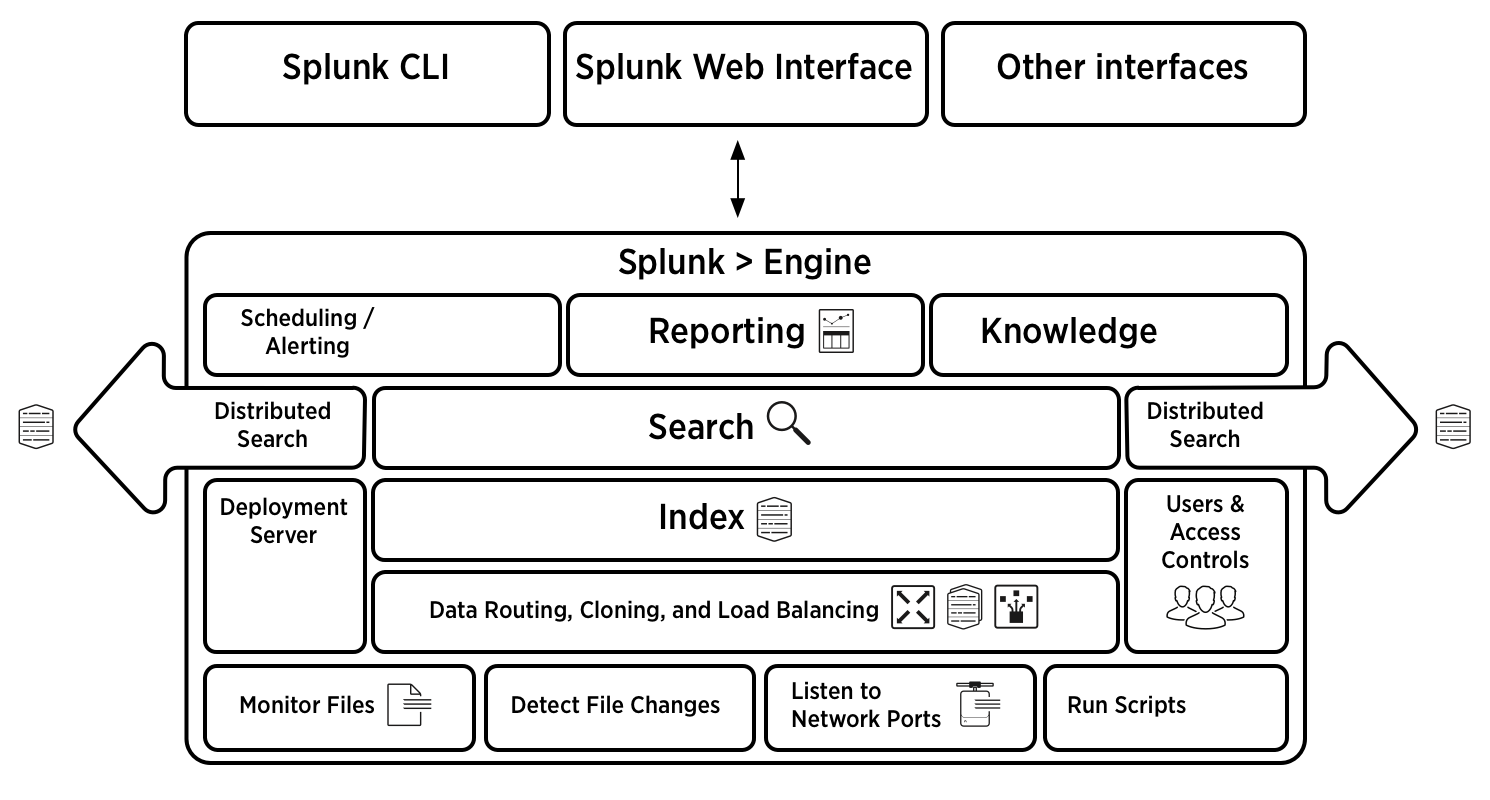
注意:负载均衡,副本!
Splunk Architecture
A Bit About Architecture
Splunk is a high performance, scalable software server written in C/C++ and Python. It indexes and searches logs and other IT data in real time. Splunk works with data generated by any application, server or device. The Splunk Developer API is accessible via REST, SOAP or the command line. After downloading, installing and starting Splunk, you'll find two Splunk Server processes running on your host, splunkd and splunkweb.
- splunkd is a distributed C/C++ server that accesses, processes and indexes streaming IT data and also handles search requests. splunkd processes and indexes your data by streaming it through a series of pipelines, each made up of a series of processors. Pipelines are single threads inside the splunkd process, each configured with a single snippet of XML. Processors are individual, reusable C/C++ or Python functions that act on the stream of IT data passing through a pipeline. Pipelines can pass data to one another via queues. splunkd supports a command line interface for searching and viewing results.
- splunkweb is a Python-based application server providing the Splunk Web user interface. It allows users to search and navigate IT data stored by Splunk servers and to manage your Splunk deployment through the browser interface. splunkweb communicates with your web browser via REST and communicates with splunkd via SOAP.

- Splunk's Data Store manages the original raw data in compressed format as well as the indexes into the data. Data can be deleted or archived based on retention period or maximum data store size.
- Splunk Servers can communicate with one another via Splunk-2-Splunk, a TCP-based protocol, to forward data from one server to another and to distribute searches across multiple servers.
- Bundles are files that contain configuration settings including, user accounts, Splunks, Live Splunks, Data Inputs and Processing Properties to easily create specific Splunk environments.
- Modules are files that add new functionality to Splunk by adding to or modifying existing processors and pipelines.
About forwarding and receiving
You can forward data from one Splunk instance to another Splunk server or even to a non-Splunk system. The Splunk instance that performs theforwarding is typically a smaller footprint version of Splunk, called a forwarder.
A Splunk instance that receives data from one or more forwarders is called a receiver. The receiver is usually a Splunk indexer, but can also be another forwarder, as described here.
This diagram shows three forwarders sending data to a single Splunk receiver (an indexer), which then indexes the data and makes it available for searching:
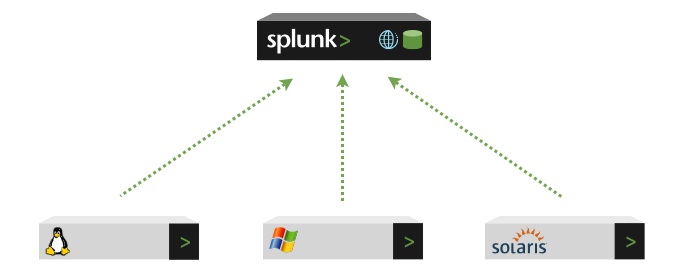
Splunk Enterprise architecture——转发器本质上是日志收集client附加负载均衡,indexer是分布式索引,外加一个集中式管理协调的中心节点的更多相关文章
- Jexus是一款Linux平台上的高性能WEB服务器和负载均衡网关
什么是Jexus Jexus是一款Linux平台上的高性能WEB服务器和负载均衡网关,以支持ASP.NET.ASP.NET CORE.PHP为特色,同时具备反向代理.入侵检测等重要功能.可以这样说,J ...
- 动态DNS——本质上是IP变化,将任意变换的IP地址绑定给一个固定的二级域名。不管这个线路的IP地址怎样变化,因特网用户还是可以使用这个固定的域名 这样看的话,p2p可以用哇
动态域名是因应网络远程访问的需要而产生的一项应用技术.因为没有固定IP,只能运用二级域名来应对经常变化的IP,动态域名的由来因此而产生. 它当前主要应用在:路由器.网络摄像机.带网络监控的硬盘录像机. ...
- Linux下Rsyslog日志远程集中式管理
Rsyslog简介 Rsyslog的全称是 rocket-fast system for log,它提供了高性能,高安全功能和模块化设计.rsyslog能够接受从各种各样的来源,将其输入,输出的结果到 ...
- Dubbo入门到精通学习笔记(二十):MyCat在MySQL主从复制的基础上实现读写分离、MyCat 集群部署(HAProxy + MyCat)、MyCat 高可用负载均衡集群Keepalived
文章目录 MyCat在MySQL主从复制的基础上实现读写分离 一.环境 二.依赖课程 三.MyCat 介绍 ( MyCat 官网:http://mycat.org.cn/ ) 四.MyCat 的安装 ...
- Centos7搭建集中式日志系统
在CentOS7中,Rsyslong是一个集中式的日志收集系统,可以运行在TCP或者UDP的514端口上. 目录 开始之前 配置接收日志的主机 配置发送日志的主机 日志回滚 附件:创建日志接收模板 ...
- flume集群日志收集
一.Flume简介 Flume是一个分布式的.高可用的海量日志收集.聚合和传输日志收集系统,支持在日志系统中定制各类数据发送方(如:Kafka,HDFS等),便于收集数据.其核心为agent,agen ...
- ELK日志收集平台部署
需求背景 由于公司的后台服务有三台,每当后台服务运行异常,需要看日志排查错误的时候,都必须开启3个ssh窗口进行查看,研发们觉得很不方便,于是便有了统一日志收集与查看的需求. 这里,我用ELK集群,通 ...
- 理解OpenShift(6):集中式日志处理
理解OpenShift(1):网络之 Router 和 Route 理解OpenShift(2):网络之 DNS(域名服务) 理解OpenShift(3):网络之 SDN 理解OpenShift(4) ...
- SpringBoot+kafka+ELK分布式日志收集
一.背景 随着业务复杂度的提升以及微服务的兴起,传统单一项目会被按照业务规则进行垂直拆分,另外为了防止单点故障我们也会将重要的服务模块进行集群部署,通过负载均衡进行服务的调用.那么随着节点的增多,各个 ...
随机推荐
- 01: 安装zabbix server
目录:Django其他篇 01: 安装zabbix server 02:zabbix-agent安装配置 及 web界面管理 03: zabbix API接口 对 主机.主机组.模板.应用集.监控项. ...
- canvas绘图详解笔记之线条及线条属性
创建 canvas 首先创建一个canvas元素,我们只需要在html文件中加入这么一句代码: <canvas id="canvas">当前浏览器不支持canvas,请 ...
- scp命令在linux间传送文件的方法
当两台LINUX主机之间要互传文件时可使用SCP命令来实现,建立信任关系之后可不输入密码. 把你的本地主机用户的ssh公匙文件复制到远程主机用户的~/.ssh/authorized_keys文件中 ...
- java使用itex读取pdf,并搜索关键字,为其盖章
导读:近期要做一个根据关键字定位pdf的盖章位置的相关需求,其中关键字可配置多个(包含pdf文档中可能不存在的关键字),当页面显示盖章完成时,打开pdf显示已经损坏. 排查后发现,当itext搜索的关 ...
- python函数总结
1.函数是一种子程序.程序员使用函数来减少代码重复,并用于组织或模块化程序.一旦定义了函数,它可以从程序中的许多不同位置被多次调用.参数允许函数具有可更改的部分.函数定义中出现的参数称之为形参,函数调 ...
- 如何修改ls命令列出来的目录颜色
答:默认为蓝色,在黑色背景下无法看清楚,因此以以下方法修改; 1.往~/.bash_profile文件中添加以下内容: export LS_COLORS='no=00:fi=00:di=01;33:l ...
- POJ1251 Jungle Roads (最小生成树&Kruskal&Prim)题解
题意: 输入n,然后接下来有n-1行表示边的加边的权值情况.如A 2 B 12 I 25 表示A有两个邻点,B和I,A-B权值是12,A-I权值是25.求连接这棵树的最小权值. 思路: 一开始是在做莫 ...
- FieldOffset
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.G ...
- POST提交大量数据,导致后面数据丢失
这个问题,解决了很久,先简单说下我解决的具体思路: 首先:form表单提交,导致后面数据丢失,考虑了提交大量的数据,导致后台溢出,剩余数据量丢失,所以从网上搜了教程: 参考链接: https://bl ...
- jquery zTree异步加载的例子
下面是使用zTree异步加载的一个例子: 1)初始化树的时候是ajax请求,返回nodes列表来初始化树的:如果一开始就异步的话,$.fn.zTree.init($("#zTree" ...