GBT算法在拖动滑块辨别人还是机器中的应用
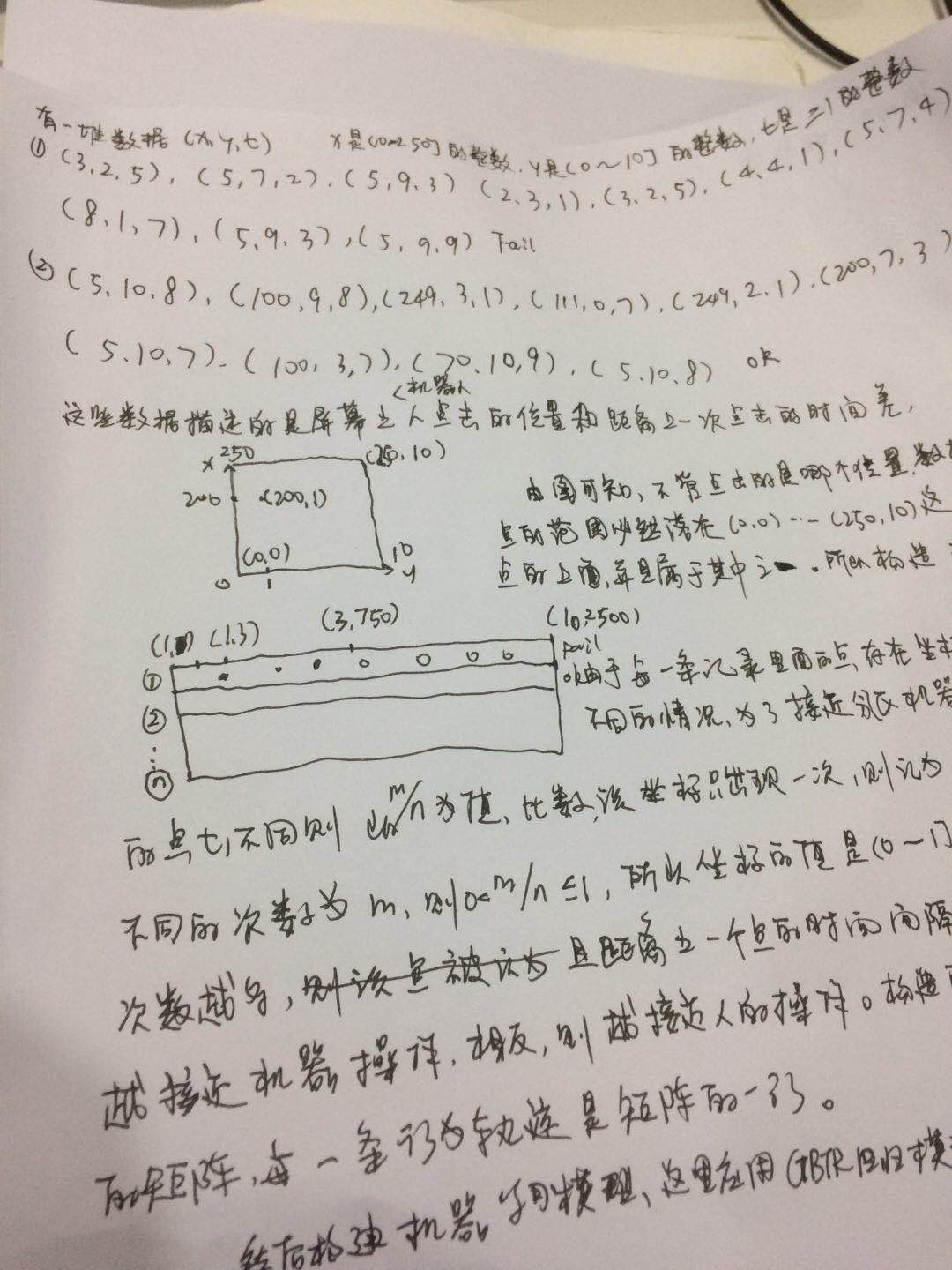
1.数据源格式:(x,y,t),第一个值x是x坐标范围是1-250的整数,y是1-10的整数,t是滑块从上一个坐标到下一个坐标的时间差,ok是判断是人操作的,Fail是判断是机器操作的,数据看的出,同一个记录里面的同一个点,即x,y都相同,但是t不同,以此分析,如果同一个点只出现一次,则该点记录为1,如果出现n次,重复次数为m次,则设计该点的值为m/n,如该点在该条记录出现的总次数是5,t不同的次数是3,则该点的值是=3、5=0.6,分析的依据是,如果该点重复的次数越多,而且距离上一个时间差越近,说明越接近机器人的轨迹,因为人的轨迹是变化较大的。将模型设计为一个大表,以1-2500这2500个数字为字段,这个表在scala 程序中是一个数组,数组长度为2500,1...250分别对应坐标点中的(0,0,)....(0,250),2-500分别对应坐标点中的(1,0)...(1,250)...所以必然,在每条记录里面的所有点必然在这个数组中能找到,在表中就是一行,这些点必然是在这行中能找到一个列属于该点,如果不存在,则设为0.
[[25,27,0],[6,-1,470],[8,2,20],[14,-1,38],[10,1,28],[3,0,9],[10,-2,28],[9,1,27],[12,-1,38],[12,0,39],[3,2,10],[10,0,35],[3,-1,8],[6,-1,25],[8,1,31],[5,0,18],[2,1,11],[7,0,29],[2,-2,11],[4,2,20],[4,-2,18],[2,1,13],[1,-1,7],[6,2,32],[3,-1,17],[5,0,37],[4,-1,32],[3,0,24],[4,1,32],[4,-1,39],[4,0,40],[3,2,35],[1,0,12],[2,-2,28],[0,1,229]];FAIL
[[27,24,0],[4,1,467],[8,-1,40],[2,-1,7],[2,2,9],[3,-2,15],[6,2,32],[4,-1,20],[7,1,35],[5,-2,26],[2,1,10],[5,1,27],[1,-1,6],[2,0,15],[5,1,26],[4,-2,28],[3,0,23],[1,2,7],[4,-1,26],[3,-1,19],[1,0,7],[3,2,24],[0,0,6],[5,-1,40],[4,-1,39],[1,1,8],[0,0,7],[3,0,35],[3,0,26],[2,-1,32],[2,0,32],[2,2,33],[1,-2,8],[1,1,25],[1,1,14],[1,-1,22],[2,-1,40],[0,0,22],[1,0,1],[0,1,219]];FAIL
[[25,28,0],[8,1,524],[7,-1,27],[4,0,16],[3,-1,16],[3,2,10],[8,-1,35],[8,-1,40],[8,2,38],[2,-1,10],[6,-1,29],[4,0,23],[7,2,36],[5,-2,33],[5,2,26],[4,-1,29],[4,0,26],[1,0,9],[5,-1,38],[2,0,25],[4,1,29],[3,0,37],[2,0,19],[0,-1,6],[3,1,34],[2,0,24],[2,0,27],[2,-1,32],[2,0,40],[1,1,6],[1,-1,22],[1,0,33],[1,0,4],[0,1,299]];OK
2.算法构造scala代码如下:
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.feature.VectorIndexer
import org.apache.spark.ml.regression.{GBTRegressionModel, GBTRegressor}
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.sql.types.{DoubleType, StringType, StructField, StructType}
import org.apache.spark.sql.SQLContext
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics
import org.apache.spark.mllib.regression.LabeledPoint
object GBTForget {
/**
* Created by lkl on 2017/12/14.
*/
def main(args: Array[String]): Unit = {
val cf = new SparkConf().setAppName("ass").setMaster("local")
val sc = new SparkContext(cf)
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
val File1 = sc.textFile("20171117PP.txt").filter(_.contains("OK")).map(_.replace(",0],","a[").split("a").last).map(_.replace("OK", "1")).map(_.replace("FAIL", "0")).map(line => (line.split(";").last.toDouble, line.split(";").head))
val File2=sc.textFile("20171117PP.txt").filter(_.contains("FAIL")).map(_.replace(",0],","a[").split("a").last).map(_.replace("OK", "1")).map(_.replace("FAIL", "0")).map(line => (line.split(";").last.toDouble, line.split(";").head))
val b=File2.randomSplit(Array(0.1, 0.9))
val (strainingDatas, stestDatas) = (b(0), b(1))
val File=File1 union(strainingDatas)
val ass = File.map { p => {
var str = ""
val l = p._1
val a = p._2.substring(2, p._2.length - 2)
val b = a.replace("],[", "a")
val c = b.split("a")
for (arr <- c) {
val index1 = arr.split(",")(0).toInt + ","
val index2 = arr.split(",")(1).toInt + ","
val index3 = arr.split(",")(2).toInt + " "
val index = index1 + index2 + index3
str += index
}
(l, str.substring(0, str.length - 1))
}
}
val rdd = ass.map( p => {
val l=p._1
val rowall =new Array[Double](2500)
val arr = p._2.split(" ")
var map:Map[Int,List[Double]] = Map()
var vlist:List[Double] = List()
for(a <- arr){
val x = a.split(",")(0).toInt
val y = a.split(",")(1).toInt+5
val t = a.split(",")(2).toInt
val index = (x*10)+(y+1)
val v = t
vlist = v :: map.get(index).getOrElse(List())
map += (index -> vlist) }
map.foreach(p => {
val k = p._1
val v = p._2
val sv = v.toSet.size
val rv = sv.toDouble/v.size.toDouble
val tmp =f"$rv%1.2f".toDouble
rowall(k) = tmp
})
(l.toDouble,Vectors.dense(rowall))
}).toDF("label","features") // val label=row.getInt(0).toDouble
// val no=row.getString(2)
// val feature=Vectors.dense(arr.toArray)
// (label,no,feature)
// Automatically identify categorical features, and index them.
// Set maxCategories so features with > 4 distinct values are treated as continuous.
val featureIndexer = new VectorIndexer().setInputCol("features").setOutputCol("indexedFeatures").setMaxCategories(4).fit(rdd)
// Split the data into training and test sets (30% held out for testing)
val Array(trainingData, testData) = rdd.randomSplit(Array(0.7, 0.3))
// Train a GBT model.
val gbt = new GBTRegressor().setLabelCol("label").setFeaturesCol("indexedFeatures").setMaxIter(10)
// Chain indexer and GBT in a Pipeline
val pipeline = new Pipeline().setStages(Array(featureIndexer, gbt))
// Train model. This also runs the indexer.
val model = pipeline.fit(trainingData)
// Make predictions.
val predictions = model.transform(testData).select("label","prediction").toJavaRDD
predictions.repartition(1).saveAsTextFile("/user/hadoop/20171214") val File0=sc.textFile("001.txt").map(_.replace(",0],","a[").split("a").last).map(_.replace("OK", "1")).map(_.replace("FAIL", "0")).map(line => (line.split(";").last.toDouble, line.split(";").head)) val ass001 = File0.map { p => {
var str = ""
val l = p._1
val a = p._2.substring(2, p._2.length - 2)
val b = a.replace("],[", "a")
val c = b.split("a")
for (arr <- c) {
val index1 = arr.split(",")(0).toInt + ","
val index2 = arr.split(",")(1).toInt + ","
val index3 = arr.split(",")(2).toInt + " "
val index = index1 + index2 + index3
str += index
}
(l, str.substring(0, str.length - 1))
}
}
val rdd001 = ass001.map( p => {
val l=p._1
val rowall =new Array[Double](2500)
val arr = p._2.split(" ")
var map:Map[Int,List[Double]] = Map()
var vlist:List[Double] = List()
for(a <- arr){
val x = a.split(",")(0).toInt
val y = a.split(",")(1).toInt+5
val t = a.split(",")(2).toInt
val index = (x*10)+(y+1)
val v = t
vlist = v :: map.get(index).getOrElse(List())
map += (index -> vlist) }
map.foreach(p => {
val k = p._1
val v = p._2
val sv = v.toSet.size
val rv = sv.toDouble/v.size.toDouble
val tmp =f"$rv%1.2f".toDouble
rowall(k) = tmp
})
(l.toDouble,Vectors.dense(rowall))
}).toDF("label","features") val predicions001=model.transform(rdd001) // predicions001.repartition(1).saveAsTextFile("/user/hadoop/20171214001") } }
GBT算法在拖动滑块辨别人还是机器中的应用的更多相关文章
- jQuery手机触屏拖动滑块验证跳转插件
HTML: <!DOCTYPE html> <html lang="en"> <head> <title>jQuery手机触屏拖动滑 ...
- js+css3+HTML5拖动滑块(type="range")改变值
最近在做一个H5的改版项目,产品和设计给出的效果中有一个拖动滑块可以改变输入值的效果,类似如下图这样: 拿到这样的设计稿后,我有点懵了,自己写一个js?去网上找一个这样的效果?自己写一个可以,只是实现 ...
- 原生js实现拖动滑块验证
拖动滑块验证是现在的网站随处可见的,各式各样的拖动法都有. 下面实现的是某宝的拖动滑块验证: <!DOCTYPE html> <html lang="en"> ...
- [Android实例] 拖动滑块进行图片拼合验证方式的实现
该篇文章从eoeAndroid搬迁过来的,原文地址:[Android实例] 拖动滑块进行图片拼合验证方式的实现 现在网站上有各种各样的验证码验证方式,比如计算大小,输入图片内容等,今天在一家网站上看到 ...
- js 拖动滑块验证
备注:拖动滑块时尽量平移,chrome浏览器上没有卡顿情况,但是搜狗极速模式和360极速模式都遇到了卡顿,拖不动情况,应是浏览器内部对事件响应速度导致吧. JS代码: ;(function ($,wi ...
- html5拖动滑块
html5中input有增加type=range.这为拖动滑块提供了很大的便利.下面是他的属性: <!DOCTYPE html> <html lang="en"& ...
- seekBar拖动滑块
中秋节学习,, 通过拖动滑块,改变图片的透明度 <?xml version="1.0" encoding="utf-8"?> <LinearL ...
- 原生JS实现拖动滑块验证登录效果
♀分享一组利用原生JS实现拖动滑块验证效果 ♀在这个组代码中涉及三个方面的知识: ⑴事件处理 ⑵添加验证标记 ⑶选择器的封装 代码如下: <!DOCTYPE html> <htm ...
- 常见算法合集[java源码+持续更新中...]
一.引子 本文搜集从各种资源上搜集高频面试算法,慢慢填充...每个算法都亲测可运行,原理有注释.Talk is cheap,show me the code! 走你~ 二.常见算法 2.1 判断单向链 ...
随机推荐
- 【Unity笔记】用代码动态修改Animator状态机的状态
通常情况下,Animator修改状态机,是在Animator定义参数(变量),状态之间建立切换的条件(箭头),然后代码中修改参数(变量),实现状态之间的切换. 而另一种情况下,不需要预先准备定义参数( ...
- 阿里云 Caused by: redis.clients.jedis.exceptions.JedisDataException: ERR invalid password
如果你是买的阿里云的redis服务的话,不要被这个ERR invalid password所迷惑了. 你应该去检查一下你买的服务有没有设置白名单. 像mysql和mongodb的服务如果连不上的话也可 ...
- python -修改文件中某一行
写代码写错了顺序,所以想办法把x,y坐标调换回来 def change_ptsxy(fileName): fp = open(fileName) i = file_data = "" ...
- C#7.0新语法
一.out输出参数 在以前使用out输出参数的时候,必须先定义变量,然后才能使用,例如: 先定义一个方法,方法参数是out类型的输出参数: private void DoNoting(out int ...
- 【Python】 linecache模块读取文件
[linecache] 过往在读取文件的时候,我们通常使用的是这种模式: with open('file.txt','r') as f: line = f.readline() while line: ...
- 再谈git的http服务-权限控制gitweb版(未成功)
截至目前,对gitweb的掌握还没达到最终目标,仅仅实现了通过浏览器来浏览项目,通过git命令仍然未能clone项目.但仍然要记录下来,主要是因为打算暂时放弃这条路,而所收获的一些经验还是要记录下来. ...
- 构建Java并发模型框架
Java的多线程特性为构建高性能的应用提供了极大的方便,但是也带来了不少的麻烦.线程间同步.数据一致性等烦琐的问题需要细心的考虑,一不小心就会出现一些微妙的,难以调试的错误.另外,应用逻辑和线程逻辑纠 ...
- .net操作oracle,一定要用管理员身份运行 visual studio 啊,切记切记,免得报奇怪的错误。
.net操作oracle,一定要用管理员身份运行 visual studio 啊,切记切记,免得报奇怪的错误.
- Matlab 读取excel文件提示服务器出现意外情况或无法读取问题解决
1.问题描述: 该错误通常发生在应用函数读取excel文件(后缀xls或xlsx)时. 应用xlsread函数读取提示服务器出现意外情况: 应用importdata读取时提示can‘t open fi ...
- 从Java开发者的视角解释JavaScript
我们无法在一篇博文里解释JavaScript的所有细节.如果你正或多或少地涉及了web应用程序开发,那么,我们的Java工具和技术范围报告揭示了,大多数(71%)Java开发者被归到了这一类,只是你对 ...