机器学习实战笔记(Python实现)-03-朴素贝叶斯
---------------------------------------------------------------------------------------
本系列文章为《机器学习实战》学习笔记,内容整理自书本,网络以及自己的理解,如有错误欢迎指正。
源码在Python3.5上测试均通过,代码及数据 --> https://github.com/Wellat/MLaction
---------------------------------------------------------------------------------------
1、算法概述
1.1 朴素贝叶斯
朴素贝叶斯是使用概率论来分类的算法。其中朴素:各特征条件独立;贝叶斯:根据贝叶斯定理。
根据贝叶斯定理,对一个分类问题,给定样本特征x,样本属于类别y的概率是:
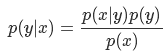 -------(1)
-------(1)
在这里,x 是一个特征向量,设 x 维度为 M。因为朴素的假设,即特征条件独立,根据全概率公式展开,上式可以表达为:
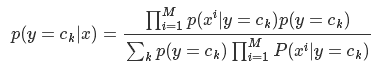
这里,只要分别估计出,特征 Χi 在每一类的条件概率就可以了。类别 y 的先验概率可以通过训练集算出,同样通过训练集上的统计,可以得出对应每一类上的,条件独立的特征对应的条件概率向量。
1.2 算法特点
优点:在数据较少的情况下仍然有效,可以处理多类别问题。
缺点:对于输入数据的准备方式较为敏感。
适用数据类型:标称型数据。
2、使用Python进行文本分类
要从文本中获取特征,需要先拆分文本。可以把词条想象为单词,也可以使用非单词词条,如URL、IP地址或者任意其他字符串。然后将每一个文本片段表示为一个词条向量,其中值为1表示词条出现在文档中,0表示词条未出现。
2.1 准备数据:从文本中构建词向量
from numpy import * def loadDataSet():
'''
postingList: 进行词条切分后的文档集合
classVec:类别标签
'''
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #1代表侮辱性文字,0代表正常言论
return postingList,classVec def createVocabList(dataSet):
vocabSet = set([])#使用set创建不重复词表库
for document in dataSet:
vocabSet = vocabSet | set(document) #创建两个集合的并集
return list(vocabSet) def setOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList)#创建一个所包含元素都为0的向量
#遍历文档中的所有单词,如果出现了词汇表中的单词,则将输出的文档向量中的对应值设为1
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else: print("the word: %s is not in my Vocabulary!" % word)
return returnVec
'''
我们将每个词的出现与否作为一个特征,这可以被描述为词集模型(set-of-words model)。
如果一个词在文档中出现不止一次,这可能意味着包含该词是否出现在文档中所不能表达的某种信息,
这种方法被称为词袋模型(bag-of-words model)。
在词袋中,每个单词可以出现多次,而在词集中,每个词只能出现一次。
为适应词袋模型,需要对函数setOfWords2Vec稍加修改,修改后的函数称为bagOfWords2VecMN
'''
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec
2.2 训练算法:从词向量计算概率
计算每个类别的条件概率,伪代码:

def trainNB0(trainMatrix,trainCategory):
'''
朴素贝叶斯分类器训练函数(此处仅处理两类分类问题)
trainMatrix:文档矩阵
trainCategory:每篇文档类别标签
'''
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs)
#初始化所有词出现数为1,并将分母初始化为2,避免某一个概率值为0
p0Num = ones(numWords); p1Num = ones(numWords)#
p0Denom = 2.0; p1Denom = 2.0 #
for i in range(numTrainDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
#将结果取自然对数,避免下溢出,即太多很小的数相乘造成的影响
p1Vect = log(p1Num/p1Denom)#change to log()
p0Vect = log(p0Num/p0Denom)#change to log()
return p0Vect,p1Vect,pAbusive
2.3 测试算法
分类函数:
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
'''
分类函数
vec2Classify:要分类的向量
p0Vec, p1Vec, pClass1:分别对应trainNB0计算得到的3个概率
'''
p1 = sum(vec2Classify * p1Vec) + log(pClass1)
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
测试:
def testingNB():
listOPosts,listClasses = loadDataSet()
myVocabList = createVocabList(listOPosts)
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
#训练模型,注意此处使用array
p0V,p1V,pAb = trainNB0(array(trainMat),array(listClasses))
testEntry = ['love', 'my', 'dalmation']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print(testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))
testEntry = ['stupid', 'garbage']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print(testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))
3、实例:使用朴素贝叶斯过滤垃圾邮件
一般流程:

3.1 切分文本
将长字符串切分成词表,包括将大写字符转换成小写,并过滤字符长度小于3的字符。
def textParse(bigString):#
'''
文本切分
输入文本字符串,输出词表
'''
import re
listOfTokens = re.split(r'\W*', bigString)
return [tok.lower() for tok in listOfTokens if len(tok) > 2]
3.2 使用朴素贝叶斯进行垃圾邮件分类
def spamTest():
'''
垃圾邮件测试函数
'''
docList=[]; classList = []; fullText =[]
for i in range(1,26):
#读取垃圾邮件
wordList = textParse(open('email/spam/%d.txt' % i,'r',encoding= 'utf-8').read())
docList.append(wordList)
fullText.extend(wordList)
#设置垃圾邮件类标签为1
classList.append(1)
wordList = textParse(open('email/ham/%d.txt' % i,'r',encoding= 'utf-8').read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(0)
vocabList = createVocabList(docList)#生成次表库
trainingSet = list(range(50))
testSet=[] #
#随机选10组做测试集
for i in range(10):
randIndex = int(random.uniform(0,len(trainingSet)))
testSet.append(trainingSet[randIndex])
del(trainingSet[randIndex])
trainMat=[]; trainClasses = []
for docIndex in trainingSet:#生成训练矩阵及标签
trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex]))
trainClasses.append(classList[docIndex])
p0V,p1V,pSpam = trainNB0(array(trainMat),array(trainClasses))
errorCount = 0
#测试并计算错误率
for docIndex in testSet:
wordVector = bagOfWords2VecMN(vocabList, docList[docIndex])
if classifyNB(array(wordVector),p0V,p1V,pSpam) != classList[docIndex]:
errorCount += 1
print("classification error",docList[docIndex])
print('the error rate is: ',float(errorCount)/len(testSet))
#return vocabList,fullText
4、实例:使用朴素贝叶斯分类器从个人广告中获取区域倾向
一般流程:

在这个中,我们将分别从美国的两个城市中选取一些人,通过分析这些人发布的征婚广告信息,来比较这两个城市的人们在广告用词上是否不同 。
4.1 实现代码
'''
函数localWords()与程序清单中的spamTest()函数几乎相同,区别在于这里访问的是
RSS源而不是文件。然后调用函数calcMostFreq()来获得排序最高的30个单词并随后将它们移除
'''
def localWords(feed1,feed0):
import feedparser
docList=[]; classList = []; fullText =[]
minLen = min(len(feed1['entries']),len(feed0['entries']))
for i in range(minLen):
wordList = textParse(feed1['entries'][i]['summary'])
docList.append(wordList)
fullText.extend(wordList)
classList.append(1) #NY is class 1
wordList = textParse(feed0['entries'][i]['summary'])
docList.append(wordList)
fullText.extend(wordList)
classList.append(0)
vocabList = createVocabList(docList)#create vocabulary
top30Words = calcMostFreq(vocabList,fullText) #remove top 30 words
for pairW in top30Words:
if pairW[0] in vocabList: vocabList.remove(pairW[0])
trainingSet = list(range(2*minLen)); testSet=[] #create test set
for i in range(10):
randIndex = int(random.uniform(0,len(trainingSet)))
testSet.append(trainingSet[randIndex])
del(trainingSet[randIndex])
trainMat=[]; trainClasses = []
for docIndex in trainingSet:#train the classifier (get probs) trainNB0
trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex]))
trainClasses.append(classList[docIndex])
p0V,p1V,pSpam = trainNB0(array(trainMat),array(trainClasses))
errorCount = 0
for docIndex in testSet: #classify the remaining items
wordVector = bagOfWords2VecMN(vocabList, docList[docIndex])
if classifyNB(array(wordVector),p0V,p1V,pSpam) != classList[docIndex]:
errorCount += 1
print('the error rate is: ',float(errorCount)/len(testSet))
return vocabList,p0V,p1V def calcMostFreq(vocabList,fullText):
'''
返回前30个高频词
'''
import operator
freqDict = {}
for token in vocabList:
freqDict[token]=fullText.count(token)
sortedFreq = sorted(freqDict.items(), key=operator.itemgetter(1), reverse=True)
return sortedFreq[:30] if __name__== "__main__":
#导入RSS数据源
import operator
ny=feedparser.parse('http://newyork.craigslist.org/stp/index.rss')
sf=feedparser.parse('http://sfbay.craigslist.org/stp/index.rss')
localWords(ny,sf)
机器学习实战笔记(Python实现)-03-朴素贝叶斯的更多相关文章
- 【机器学习实战】第4章 朴素贝叶斯(Naive Bayes)
第4章 基于概率论的分类方法:朴素贝叶斯 朴素贝叶斯 概述 贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类.本章首先介绍贝叶斯分类算法的基础——贝叶斯定理.最后,我们 ...
- Python实现nb(朴素贝叶斯)
Python实现nb(朴素贝叶斯) 运行环境 Pyhton3 numpy科学计算模块 计算过程 st=>start: 开始 op1=>operation: 读入数据 op2=>ope ...
- 机器学习实战笔记(Python实现)-00-readme
近期学习机器学习,找到一本不错的教材<机器学习实战>.特此做这份学习笔记,以供日后翻阅. 机器学习算法分为有监督学习和无监督学习.这本书前两部分介绍的是有监督学习,第三部分介绍的是无监督学 ...
- Python机器学习(基础篇---监督学习(朴素贝叶斯))
朴素贝叶斯 朴素贝叶斯分类器的构造基础是贝叶斯理论.采用概率模型来表述,定义x=<x1,x2,...,xn>为某一n维特征向量,y∈{c1,c2,...ck}为该特征向量x所有k种可能的类 ...
- Python实现 利用朴素贝叶斯模型(NBC)进行问句意图分类
目录 朴素贝叶斯分类(NBC) 程序简介 分类流程 字典(dict)构造:用于jieba分词和槽值替换 数据集构建 代码分析 另外:点击右下角魔法阵上的[显示目录],可以导航~~ 朴素贝叶斯分类(NB ...
- 机器学习实战笔记(Python实现)-08-线性回归
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-05-支持向量机(SVM)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-04-Logistic回归
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-01-K近邻算法(KNN)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
随机推荐
- 用Hibernate和Struts2+jsp实现分页查询、修改删除
1.首先用get的方法传递一个页数过去 2.通过Struts2跳转到Action 3.通过request接受主页面index传过的页数,此时页数是1, 然后调用service层的方法获取DAO层分页查 ...
- ★Kali信息收集~★7.FPing :ip段扫描
参数: 使用方法: fping [选项] [目标...] -a显示是活着的目标 -A 显示目标地址 -b n 大量 ping 数据要发送,以字节为单位 (默认 56) -B f 将指数退避算法因子设置 ...
- 【原】使用Bmob作为iOS后台开发心得——云端代码添加其他User的Relation关系
本文转载请注明出处 —— polobymulberry-博客园 问题描述 我在User表中增加了两个列,分别为“我关注的人”(Relation关系)和“我的粉丝”(Relation关系)当我关注某个人 ...
- Android开发之Activity的生命周期以及加载模式
本篇博客就来好好的搞一下Activity的生命周期,如果搞过iOS的小伙伴的话,Activity的生命周期和iOS中ViewController的生命周期非常类似.生命周期,并不难理解.一个人的生命周 ...
- React.js深入学习详细解析
今天,继续深入学习react.js. 目录: 一.JSX介绍 二.React组件生命周期详解 三.属性.状态的含义和用法 四.React中事件的用法 五.组件的协同使用 六.React中的双向绑定 ...
- parseInt实例详解
parseInt() 函数可解析一个字符串,并返回一个整数. parseInt(string, radix) 参数 描述 string 必需.要被解析的字符串. radix 可选.表示要解析的数字的基 ...
- Linux网络相关配置
一.修改网卡相关配置 Linux网络参数是在/etc/sysconfig/network-scripts/ifcfg-eth0中设置,其中ifcfg-eth0表示是第一个网卡,如果还有另外一块网卡,则 ...
- MySql Access denied for user 'root'@'localhost' (using password:YES) 解决方案
关于昨天下午说的MySQL服务无法启动的问题,解决之后没有进入数据库,就直接关闭了电脑. 今早打开电脑,开始-运行 输入"mysql -uroot -pmyadmin"后出现以下错 ...
- Pyc 是什么东东
在众多语言中, 最终我们可以将语言分为编译性语言和解释性语言两种 编译性语言,也就是机器语言, 是机器能读的懂的语言, 像C语言, 其实高级语言都是基于C语言的基础之上运行的 解释性语言, 不同于编译 ...
- 【Java每日一题】20161230
// 20161229问题解析请点击今日问题下方的"[Java每日一题]20161230"查看(问题解析在公众号首发,公众号ID:weknow619)package Dec2016 ...