kafka如何保证数据可靠性和数据一致性
数据可靠性
Kafka 作为一个商业级消息中间件,消息可靠性的重要性可想而知。本文从 Producter 往 Broker 发送消息、Topic 分区副本以及 Leader 选举几个角度介绍数据的可靠性。
Producer 往 Broker 发送消息
如果我们要往 Kafka 对应的主题发送消息,我们需要通过 Producer 完成。前面我们讲过 Kafka 主题对应了多个分区,每个分区下面又对应了多个副本;为了让用户设置数据可靠性, Kafka 在 Producer 里面提供了消息确认机制。也就是说我们可以通过配置来决定有几个副本收到这条消息才算消息发送成功。可以在定义 Producer 时通过 acks 参数指定(在 0.8.2.X 版本之前是通过 request.required.acks 参数设置的,详见 KAFKA-3043)。这个参数支持以下三种值:
acks=0:生产者不会等待任何来自服务器的响应。
如果当中出现问题,导致服务器没有收到消息,那么生产者无从得知,会造成消息丢失
由于生产者不需要等待服务器的响应所以可以以网络能够支持的最大速度发送消息,从而达到很高的吞吐量
acks=1(默认值):只要集群的Leader节点收到消息,生产者就会收到一个来自服务器的成功响应
如果消息无法到达Leader节点(例如Leader节点崩溃,新的Leader节点还没有被选举出来)生产者就会收到一个错误响应,为了避免数据丢失,生产者会重发消息
如果一个没有收到消息的节点成为新Leader,消息还是会丢失
此时的吞吐量主要取决于使用的是同步发送还是异步发送,吞吐量还受到发送中消息数量的限制,例如生产者在收到服务器响应之前可以发送多少个消息
acks=-1:只有当所有参与复制的节点全部都收到消息时,生产者才会收到一个来自服务器的成功响应
这种模式是最安全的,可以保证不止一个服务器收到消息,就算有服务器发生崩溃,整个集群依然可以运行
延时比acks=1更高,因为要等待不止一个服务器节点接收消息
根据实际的应用场景,我们设置不同的 acks,以此保证数据的可靠性。
另外,Producer 发送消息还可以选择同步(默认,通过 producer.type=sync 配置) 或者异步(producer.type=async)模式。如果设置成异步,虽然会极大的提高消息发送的性能,但是这样会增加丢失数据的风险。如果需要确保消息的可靠性,必须将 producer.type 设置为 sync。
Topic 分区副本
在 Kafka 0.8.0 之前,Kafka 是没有副本的概念的,那时候人们只会用 Kafka 存储一些不重要的数据,因为没有副本,数据很可能会丢失。但是随着业务的发展,支持副本的功能越来越强烈,所以为了保证数据的可靠性,Kafka 从 0.8.0 版本开始引入了分区副本(详情请参见 KAFKA-50)。也就是说每个分区可以人为的配置几个副本(比如创建主题的时候指定 replication-factor,也可以在 Broker 级别进行配置 default.replication.factor),一般会设置为3。
Kafka 可以保证单个分区里的事件是有序的,分区可以在线(可用),也可以离线(不可用)。在众多的分区副本里面有一个副本是 Leader,其余的副本是 follower,所有的读写操作都是经过 Leader 进行的,同时 follower 会定期地去 leader 上复制数据。当 Leader 挂掉之后,其中一个 follower 会重新成为新的 Leader。通过分区副本,引入了数据冗余,同时也提供了 Kafka 的数据可靠性。
Kafka 的分区多副本架构是 Kafka 可靠性保证的核心,把消息写入多个副本可以使 Kafka 在发生崩溃时仍能保证消息的持久性。
Leader 选举
在介绍 Leader 选举之前,让我们先来了解一下 ISR(in-sync replicas)列表。每个分区的 leader 会维护一个 ISR 列表,ISR 列表里面就是 follower 副本的 Borker 编号,只有“跟得上” Leader 的 follower 副本才能加入到 ISR 里面,这个是通过 replica.lag.time.max.ms 参数配置的。只有 ISR 里的成员才有被选为 leader 的可能。
所以当 Leader 挂掉了,而且 unclean.leader.election.enable=false 的情况下,Kafka 会从 ISR 列表中选择第一个 follower 作为新的 Leader,因为这个分区拥有最新的已经 committed 的消息。通过这个可以保证已经 committed 的消息的数据可靠性。
综上所述,为了保证数据的可靠性,我们最少需要配置一下几个参数:
- producer 级别:acks=all(或者 request.required.acks=-1),同时发生模式为同步 producer.type=sync
- topic 级别:设置 replication.factor>=3,并且 min.insync.replicas>=2;
- broker 级别:关闭不完全的 Leader 选举,即 unclean.leader.election.enable=false;
数据一致性
这里介绍的数据一致性主要是说不论是老的 Leader 还是新选举的 Leader,Consumer 都能读到一样的数据。那么 Kafka 是如何实现的呢?
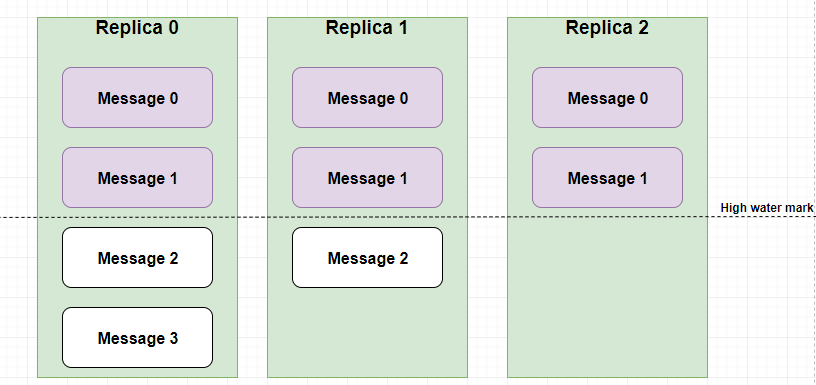
假设分区的副本为3,其中副本0是 Leader,副本1和副本2是 follower,并且在 ISR 列表里面。虽然副本0已经写入了 Message3,但是 Consumer 只能读取到 Message1。因为所有的 ISR 都同步了 Message1,只有 High Water Mark 以上的消息才支持 Consumer 读取,而 High Water Mark 取决于 ISR 列表里面偏移量最小的分区,对应于上图的副本2,这个很类似于木桶原理。
这样做的原因是还没有被足够多副本复制的消息被认为是“不安全”的,如果 Leader 发生崩溃,另一个副本成为新 Leader,那么这些消息很可能丢失了。如果我们允许消费者读取这些消息,可能就会破坏一致性。试想,一个消费者从当前 Leader(副本0) 读取并处理了 Message4,这个时候 Leader 挂掉了,选举了副本1为新的 Leader,这时候另一个消费者再去从新的 Leader 读取消息,发现这个消息其实并不存在,这就导致了数据不一致性问题。
当然,引入了 High Water Mark 机制,会导致 Broker 间的消息复制因为某些原因变慢,那么消息到达消费者的时间也会随之变长(因为我们会先等待消息复制完毕)。延迟时间可以通过参数 replica.lag.time.max.ms 参数配置,它指定了副本在复制消息时可被允许的最大延迟时间。
输入中。。。
kafka如何保证数据可靠性和数据一致性的更多相关文章
- [转帖]kafka 如何保证数据不丢失
kafka 如何保证数据不丢失 https://www.cnblogs.com/MrRightZhao/p/11498952.html 一般我们在用到这种消息中件的时候,肯定会考虑要怎样才能保证数 ...
- Kafka如何保证数据不丢失
Kafka如何保证数据不丢失 1.生产者数据的不丢失 kafka的ack机制:在kafka发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够被收到,其中状态有0,1,-1. 如果是 ...
- kafka 如何保证数据不丢失
一般我们在用到这种消息中件的时候,肯定会考虑要怎样才能保证数据不丢失,在面试中也会问到相关的问题.但凡遇到这种问题,是指3个方面的数据不丢失,即:producer consumer 端数据不丢失 b ...
- Spark Streaming和Kafka整合保证数据零丢失
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制.为了体验这个关键的特性,你需要满足以下几个先决条件: 1.输入的数据来自可靠的数据源 ...
- TCP/IP 协议是如何保证数据可靠性的?
原文: 网络基础:TCP协议-如何保证传输可靠性 TCP协议传输的特点主要就是面向字节流.传输可靠.面向连接.这篇博客,我们就重点讨论一下TCP协议如何确保传输的可靠性的. 确保传输可靠性的方式TCP ...
- Kafka在高并发的情况下,如何避免消息丢失和消息重复?kafka消费怎么保证数据消费一次?数据的一致性和统一性?数据的完整性?
1.kafka在高并发的情况下,如何避免消息丢失和消息重复? 消息丢失解决方案: 首先对kafka进行限速, 其次启用重试机制,重试间隔时间设置长一些,最后Kafka设置acks=all,即需要相应的 ...
- kafka保证数据不丢失机制
kafka如何保证数据的不丢失 1.生产者如何保证数据的不丢失:消息的确认机制,使用ack机制我们可以配置我们的消息不丢失机制为-1,保证我们的partition的leader与follower都保存 ...
- Kafka数据可靠性深度解读
原文链接:http://www.infoq.com/cn/articles/depth-interpretation-of-kafka-data-reliability Kafka起初是由Linked ...
- Kafka数据可靠性与一致性解析
Partition Recovery机制 每个Partition会在磁盘记录一个RecoveryPoint, 记录已经flush到磁盘的最大offset.broker fail 重启时,会进行load ...
随机推荐
- unity资源机制(转)
原文地址:https://www.jianshu.com/p/ca5cb9d910c0作者:重装机霸 2.资源概述 Unity必须通过导入将所支持的资源序列化,生成AssetComponents后,才 ...
- [转帖]编写shell脚本所需的语法和示例
编写shell脚本所需的语法和示例 https://blog.csdn.net/CSDN___LYY/article/details/100584638 在说什么是shell脚本之前,先说说什么是sh ...
- Linux启动/停止/重启gitlab
# Start all GitLab components sudo gitlab-ctl start # Stop all GitLab components sudo gitlab-ctl sto ...
- 干货最新版 Spring Boot2.1.5 教程+案例合集
最近发了一系列的 Spring Boot 教程,但是发的时候没有顺序,有小伙伴反映不知道该从哪篇文章开始看起,刚好最近工作告一个小小段落,松哥就把这些资料按照学习顺序重新整理了一遍,给大家做一个索引, ...
- Kuboard Kubernetes安装
一.简介 Kubernetes 容器编排已越来越被大家关注,然而使用 Kubernetes 的门槛却依然很高,主要体现在这几个方面: 集群的安装复杂,出错概率大 Kubernetes相较于容器化,引入 ...
- 《 .NET并发编程实战》阅读指南 - 第14章
先发表生成URL以印在书里面.等书籍正式出版销售后会公开内容.
- 一段简单的顶部JS广告
一段简单的顶部JS广告 <SCRIPT LANGUAGE="JavaScript"> ; ; images = new Array; images[] = new Im ...
- Celery简介以及Django中使用celery
目录 Celery简介 消息中间件 任务执行单元 任务结果存储 使用场景 Celery的安装和配置 Celery执行异步任务 基本使用 延时任务 定时任务 异步处理Django任务 案例: Celer ...
- 写css注意的事项
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 【剑指 offer】数组中重复的数字 -- PHP 实现
题目描述 在一个长度为n的数组里的所有数字都在0到n-1的范围内. 数组中某些数字是重复的,但不知道有几个数字是重复的.也不知道每个数字重复几次.请找出数组中任意一个重复的数字. 例如,如果输入长度为 ...