Spark(四十七):Spark UI 数据可视化
导入:
1)Spark Web UI主要依赖于流行的Servlet容器Jetty实现;
2)Spark Web UI(Spark2.3之前)是展示运行状况、资源状态和监控指标的前端,而这些数据都是由度量系统(MetricsSystem)收集来的;
3)Spark Web UI(spark2.3之后)呈现的数据应该与事件总线和ElementTrackingStore关系紧密,而MetricsSystem是一个向外部提供测量指标的存在
具体Spark UI存储更改可以通过spark issue查看:
Key-value store abstraction and implementation for storing application data
Use key-value store to keep History Server application listing
Hook up Spark UI to the new key-value store backend
Implement listener for saving application status data in key-value store
Make Environment page use new app state store
Make Executors page use new app state store
Spark UI界面可以包含选项卡:Jobs,Stages,Storage,Enviroment,Executors,SQL
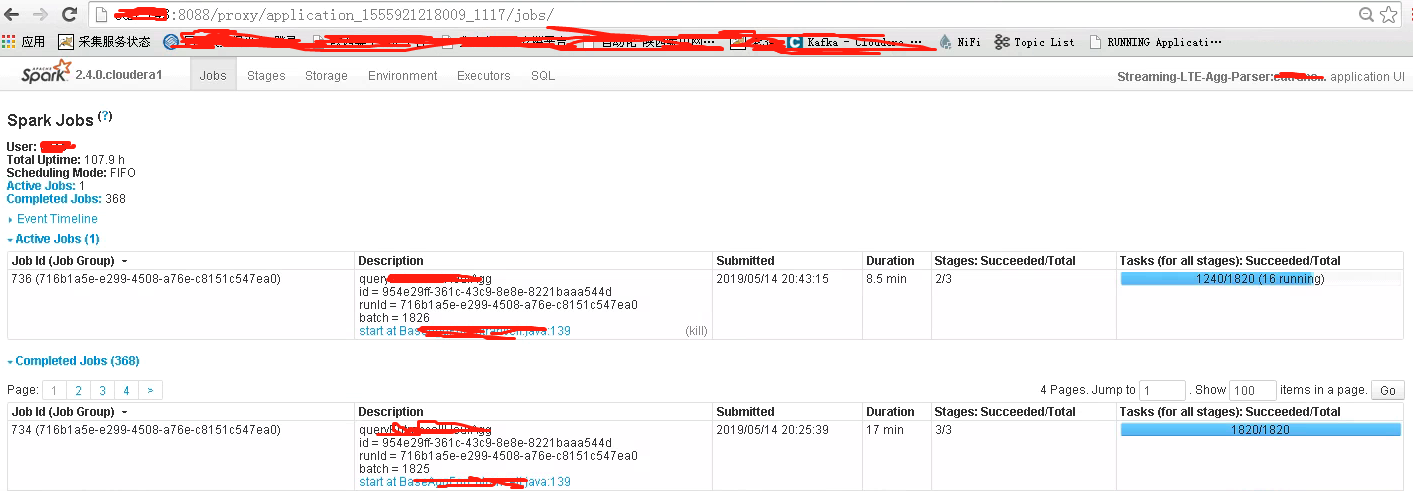
Spark UI(http server)是如何被启动?
接下来让我们从源码入手查看下Spark UI(http server)是如何被启动的,页面中的数据从哪里获取到。
Spark UI中用到的http server是jetty,jetty采用java编写,是比较不错的servlet engine和http server,能嵌入到用户程序中执行,不用用tomcat或jboss那样需要运行在独立jvm进程中。
1)SparkContext初始化时启动SparkUI
Spark UI(http server)在SparkContext初始化的时候被创建:
...
private var _listenerBus: LiveListenerBus = _
private var _statusStore: AppStatusStore = _
...
private[spark] def ui: Option[SparkUI] = _ui
_listenerBus = new LiveListenerBus(_conf) // Initialize the app status store and listener before SparkEnv is created so that it gets
// all events.
_statusStore = AppStatusStore.createLiveStore(conf)
listenerBus.addToStatusQueue(_statusStore.listener.get)
。。。。
_ui =
if (conf.getBoolean("spark.ui.enabled", true)) {
Some(SparkUI.create(Some(this), _statusStore, _conf, _env.securityManager, appName, "",
startTime))
} else {
// For tests, do not enable the UI
None
}
// Bind the UI before starting the task scheduler to communicate
// the bound port to the cluster manager properly
_ui.foreach(_.bind())
。。。
_ui.foreach(_.setAppId(_applicationId))
...
其中,_statusStore是AppStatusStore初始化对象,它内部包装了KVStore和AppStatusListener:
- KVStore用于存储监控数据,
- AppStatusListener注册到事件总线中的appStatus队列中。
_env.securityManager则是SparkEnv中初始化的安全管理器。
SparkContext通过调用SparkUI伴生对象中的create()方法来直接new出SparkUI实例,然后调用bind()方法将SparkUI绑定到Jetty服务。
2)SparkUI类对象初始化
SparkUI调用create方法后会初始化一个SparkUI对象,在SparkUI对象被初始化时,会调用SparkUI的initialize()方法
private[spark] class SparkUI private (
val store: AppStatusStore,
val sc: Option[SparkContext],
val conf: SparkConf,
securityManager: SecurityManager,
var appName: String,
val basePath: String,
val startTime: Long,
val appSparkVersion: String)
extends WebUI(securityManager, securityManager.getSSLOptions("ui"), SparkUI.getUIPort(conf),
conf, basePath, "SparkUI")
with Logging
with UIRoot { val killEnabled = sc.map(_.conf.getBoolean("spark.ui.killEnabled", true)).getOrElse(false) var appId: String = _ private var streamingJobProgressListener: Option[SparkListener] = None /** Initialize all components of the server. */
def initialize(): Unit = {
val jobsTab = new JobsTab(this, store)
attachTab(jobsTab)
val stagesTab = new StagesTab(this, store)
attachTab(stagesTab)
attachTab(new StorageTab(this, store))
attachTab(new EnvironmentTab(this, store))
attachTab(new ExecutorsTab(this))
addStaticHandler(SparkUI.STATIC_RESOURCE_DIR)
attachHandler(createRedirectHandler("/", "/jobs/", basePath = basePath))
attachHandler(ApiRootResource.getServletHandler(this)) // These should be POST only, but, the YARN AM proxy won't proxy POSTs
attachHandler(createRedirectHandler(
"/jobs/job/kill", "/jobs/", jobsTab.handleKillRequest, httpMethods = Set("GET", "POST")))
attachHandler(createRedirectHandler(
"/stages/stage/kill", "/stages/", stagesTab.handleKillRequest,
httpMethods = Set("GET", "POST")))
}
SparkUI类中有3个属性成员:
- killEnabled由配置项spark.ui.killEnable控制。如果为true,则会在Spark Web UI界面中展示强行杀掉Spark Application Job的开关;
- appId就是当前的Application ID;
- streamingJobProgressListener是用于Spark Streaming作业进度的监听器。
在initialize()方法中,
- 首先,会创建JobsTab、StagesTab、StorageTab、EnvironmentTab、ExecutorsTab这5个Tab,并调用了attachTab()方法注册到Web UI。这里的Tab是Spark UI中的标签页,参考上图,名称也是一一对应。
- 然后,调用addStaticHandler()方法创建静态资源的ServletContextHandler,又调用createRedirectHandler()创建一些重定向的ServletContextHandler。
- 最后,逐一调用attachHandler()方法注册到Web UI。
备注:ServletContextHandler是Jetty中一个功能完善的处理器,负责接收并处理HTTP请求,再投递给Servlet。
上边每个JobsTab、StagesTab、StorageTab、EnvironmentTab、ExecutorsTab除了包含有渲染页面类,还包含资源html&js&css&其他(图片)(https://github.com/apache/spark/tree/branch-2.4/core/src/main/resources/org/apache/spark/ui/static)
3)执行bind()方法启动jetty服务
在上边SparkContext初始化时,创建了SparkUI对象,将会调用bind()方法将SparkUI绑定到Jetty服务,这个bind()方法SparkUI子类WebUI中的一个方法。
WebUI属性成员和Getter方法
protected val tabs = ArrayBuffer[WebUITab]()
protected val handlers = ArrayBuffer[ServletContextHandler]()
protected val pageToHandlers = new HashMap[WebUIPage, ArrayBuffer[ServletContextHandler]]
protected var serverInfo: Option[ServerInfo] = None
protected val publicHostName = Option(conf.getenv("SPARK_PUBLIC_DNS")).getOrElse(
conf.get(DRIVER_HOST_ADDRESS))
private val className = Utils.getFormattedClassName(this) def getBasePath: String = basePath
def getTabs: Seq[WebUITab] = tabs
def getHandlers: Seq[ServletContextHandler] = handlers
def getSecurityManager: SecurityManager = securityManager
https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/ui/WebUI.scala
WebUI属性成员有6个:
- tabls:持有WebUITab(Web UI中的tab页)的缓存;
- handlers:持有Jetty ServletContextHandler的缓存;
- pageToHandlers:保存WebUIPage(WebUITab的下一级组件)与其对应的ServletContextHandler的映射关系;
- serverInfo:当前Web UI对应的Jetty服务器信息;
- publicHostName:当前Web UI对应的Jetty服务主机名。先通过系统环境变量SPARK_PUBLIC_DNS获取,在通过spark.driver.host配置项获取。
- className:当前类的名称,用Utils.getFormattedClassName()方法格式化过。
Getter方法有4个:
- getTabs()和getHandlers()都是简单地获得对应属性的值;
- getBasePath()获得构造参数中定义的Web UI基本路劲;
- getSecurityManager()则取得构造参数中传入的安全管理器。
WebUI提供的attache/detach类方法
这些方法都是成对出现,一共有3对:
- attachTab/detachTab:用于注册和移除WebUIPage;
- attachPage/detachPage:用于注册和移除WebUIPage;
- attachHandler/detaHandler:用于注册和移除ServletContextPage。
/** Attaches a tab to this UI, along with all of its attached pages. */
def attachTab(tab: WebUITab): Unit = {
tab.pages.foreach(attachPage)
tabs += tab
}
/** Detaches a tab from this UI, along with all of its attached pages. */
def detachTab(tab: WebUITab): Unit = {
tab.pages.foreach(detachPage)
tabs -= tab
}
/** Detaches a page from this UI, along with all of its attached handlers. */
def detachPage(page: WebUIPage): Unit = {
pageToHandlers.remove(page).foreach(_.foreach(detachHandler))
}
/** Attaches a page to this UI. */
def attachPage(page: WebUIPage): Unit = {
val pagePath = "/" + page.prefix
val renderHandler = createServletHandler(pagePath,
(request: HttpServletRequest) => page.render(request), securityManager, conf, basePath)
val renderJsonHandler = createServletHandler(pagePath.stripSuffix("/") + "/json",
(request: HttpServletRequest) => page.renderJson(request), securityManager, conf, basePath)
attachHandler(renderHandler)
attachHandler(renderJsonHandler)
val handlers = pageToHandlers.getOrElseUpdate(page, ArrayBuffer[ServletContextHandler]())
handlers += renderHandler
}
/** Attaches a handler to this UI. */
def attachHandler(handler: ServletContextHandler): Unit = {
handlers += handler
serverInfo.foreach(_.addHandler(handler))
}
/** Detaches a handler from this UI. */
def detachHandler(handler: ServletContextHandler): Unit = {
handlers -= handler
serverInfo.foreach(_.removeHandler(handler))
} def detachHandler(path: String): Unit = {
handlers.find(_.getContextPath() == path).foreach(detachHandler)
}
def addStaticHandler(resourceBase: String, path: String = "/static"): Unit = {
attachHandler(JettyUtils.createStaticHandler(resourceBase, path))
}
https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/ui/WebUI.scala
attachPage()方法流程:
- 1)调用Jetty工具类JettyUtils的createServletHandler()方法,为WebUIPage的两个渲染方法render()和readerJson()创建ServletContextHandler,也就是一个WebUIPage需要对应两个处理器。
- 2)然后,调用上述attachHandler()方法向Jetty注册处理器,并将映射关系写入handlers结构中。
WebUI绑定到Jetty服务
/** Binds to the HTTP server behind this web interface. */
def bind(): Unit = {
assert(serverInfo.isEmpty, s"Attempted to bind $className more than once!")
try {
val host = Option(conf.getenv("SPARK_LOCAL_IP")).getOrElse("0.0.0.0")
serverInfo = Some(startJettyServer(host, port, sslOptions, handlers, conf, name))
logInfo(s"Bound $className to $host, and started at $webUrl")
} catch {
case e: Exception =>
logError(s"Failed to bind $className", e)
System.exit(1)
}
}
https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/ui/WebUI.scala
这个bind()方法,包含节点信息:
a)其中调用startJettyServer(...)方法,该方法是JettyUtils.scala中的一个方法,这点也说明了SparkUI运行时基于jetty实现的。
b)调用startjettyServer(...)方法传递了host,port参数,这两个参数也是Spark UI访问的ip和端口,我们需要了解下这两个参数具体的配置在哪里。
√ host的获取代码:
val host = Option(conf.getenv("SPARK_LOCAL_IP")).getOrElse("0.0.0.0")
spark-env.sh包含了参数(SPARK_LOCAL_IP、SPARK_PUBLIC_DNS):
# Options read when launching programs locally with
# ./bin/run-example or ./bin/spark-submit
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public dns name of the driver program # Options read by executors and drivers running inside the cluster
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public DNS name of the driver program
# - SPARK_LOCAL_DIRS, storage directories to use on this node for shuffle and RDD data
# - MESOS_NATIVE_JAVA_LIBRARY, to point to your libmesos.so if you use Mesos
https://github.com/apache/spark/blob/branch-2.4/conf/spark-env.sh.template
√ ip的获取代码在SparkUI object静态类中
private[spark] object SparkUI {
val DEFAULT_PORT = 4040
val STATIC_RESOURCE_DIR = "org/apache/spark/ui/static"
val DEFAULT_POOL_NAME = "default"
def getUIPort(conf: SparkConf): Int = {
conf.getInt("spark.ui.port", SparkUI.DEFAULT_PORT)
}
/**
* Create a new UI backed by an AppStatusStore.
*/
def create(
sc: Option[SparkContext],
store: AppStatusStore,
conf: SparkConf,
securityManager: SecurityManager,
appName: String,
basePath: String,
startTime: Long,
appSparkVersion: String = org.apache.spark.SPARK_VERSION): SparkUI = {
new SparkUI(store, sc, conf, securityManager, appName, basePath, startTime, appSparkVersion)
}
}
Spark Web UI渲染
Spark Web UI实际上是一个三层的树形结构,树根节点为WebUI,中层节点是WebUITab,叶子节点是WebUIPage。
UI界面的展示就主要靠WebUITab与WebUIPage来实现。在Spark UI界面中,一个Tab(WebUITab)可以包含一个或多个Page(WebUIPage),且Tab(WebUITab)是可选的。
WebUI定义:上边有讲解,这里就不再贴代码。https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/ui/WebUI.scala
WebUITab定义:
/**
* A tab that represents a collection of pages.
* The prefix is appended to the parent address to form a full path, and must not contain slashes.
*/
private[spark] abstract class WebUITab(parent: WebUI, val prefix: String) {
val pages = ArrayBuffer[WebUIPage]()
val name = prefix.capitalize /** Attach a page to this tab. This prepends the page's prefix with the tab's own prefix. */
def attachPage(page: WebUIPage) {
page.prefix = (prefix + "/" + page.prefix).stripSuffix("/")
pages += page
} /** Get a list of header tabs from the parent UI. */
def headerTabs: Seq[WebUITab] = parent.getTabs def basePath: String = parent.getBasePath
}
https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/ui/WebUI.scala下定义的。
- 由于一个Tab(WebUITab)可以包含多个Page(WebUIPage),因此WebUITab中属性val pages = ArrayBuffer[WebUIPage]()数组就是用来缓存该Tab(WebUITab)下所有的Page(WebUIPage)。
- attachPage(...)方法就用于将Tab(WebUITab)的路径前缀与Page(WebUIPage)的路径前缀拼接在一起,并将其写入pages数组中。
WebUIPage定义:
/**
* A page that represents the leaf node in the UI hierarchy.
*
* The direct parent of a WebUIPage is not specified as it can be either a WebUI or a WebUITab.
* If the parent is a WebUI, the prefix is appended to the parent's address to form a full path.
* Else, if the parent is a WebUITab, the prefix is appended to the super prefix of the parent
* to form a relative path. The prefix must not contain slashes.
*/
private[spark] abstract class WebUIPage(var prefix: String) {
def render(request: HttpServletRequest): Seq[Node]
def renderJson(request: HttpServletRequest): JValue = JNothing
}
https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/ui/WebUI.scala下定义的。
- render(...)方法用于渲染页面;
- renderJson(...)方法用于生成渲染页面对应的JSON字符串。
WebUITab与WebUIPage各有一系列实现类,具体请参考代码:https://github.com/apache/spark/tree/branch-2.4/core/src/main/scala/org/apache/spark/ui/exec
渲染SparkUI页面
以Executors这个Tab页为例,因为这个页面具有代表性,一个Tab下可以展示两个Page(ExecutorsPage、ExecutorThreadDumpPage)
在Spark UI中Tab下包含页面如下:
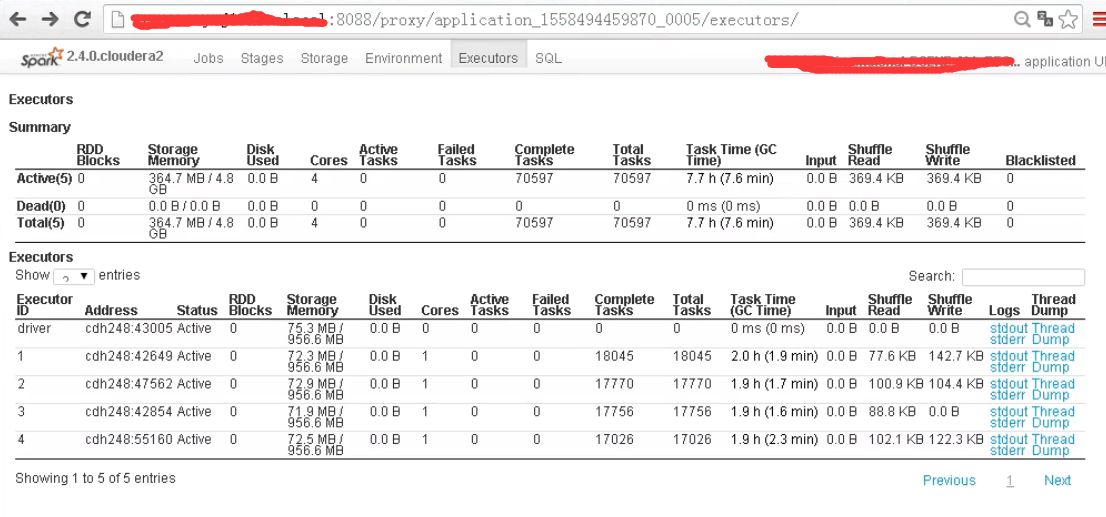
executors->ExecutorsPage
http://ip:8088/proxy/application_1558494459870_0005/executors/threadDump/?executorId=1
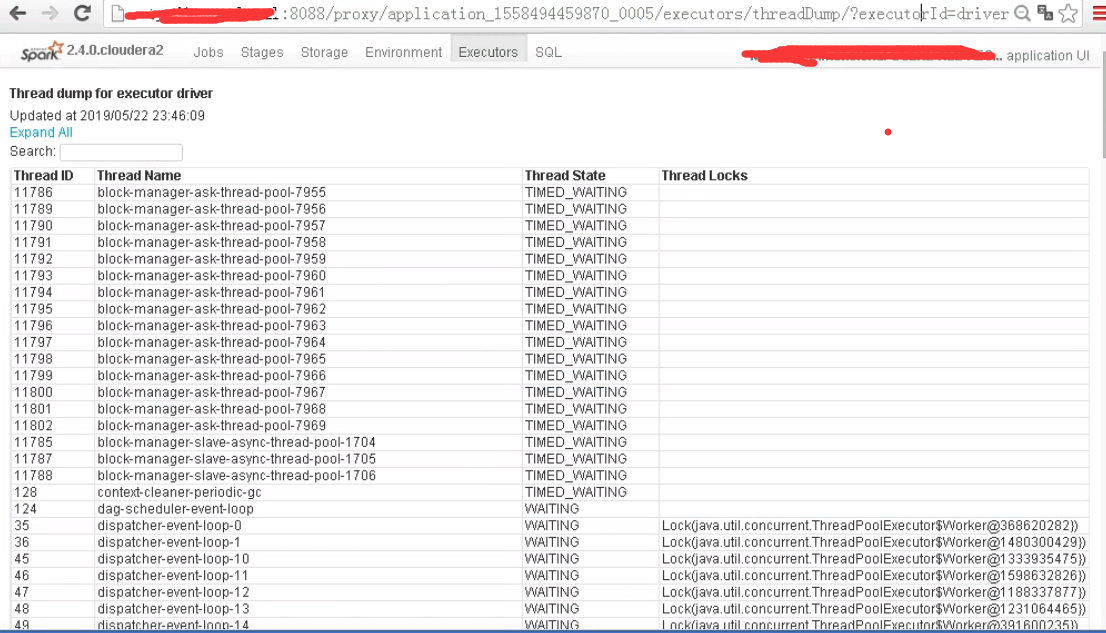
executors->ExecutorThreadDumpPage
http://ip:8088/proxy/application_1558494459870_0005/executors/threadDump/?executorId=[executorId或者driver]
首先看下ExecutorsTab的代码
private[ui] class ExecutorsTab(parent: SparkUI) extends SparkUITab(parent, "executors") {
init()
private def init(): Unit = {
val threadDumpEnabled =
parent.sc.isDefined && parent.conf.getBoolean("spark.ui.threadDumpsEnabled", true)
attachPage(new ExecutorsPage(this, threadDumpEnabled))
if (threadDumpEnabled) {
attachPage(new ExecutorThreadDumpPage(this, parent.sc))
}
}
}
其中SparkUITab就是对WebUITab的简单封装,加上了Application名称和Spark版本属性。ExecutorsTab类包含了init()方法,在构造函数中调用了该init()方法,init()方法内部调用了SparkUITab类预定义好的attachPage(...)方法,将ExecutorsPage加入,当属性threadDumpEnabled为true时,也将ExecutorThreadDumpPage加入。
再来看下ExecutorsPage的代码
private[ui] class ExecutorsPage(
parent: SparkUITab,
threadDumpEnabled: Boolean)
extends WebUIPage("") { def render(request: HttpServletRequest): Seq[Node] = {
val content =
<div>
{
<div id="active-executors" class="row-fluid"></div> ++
<script src={UIUtils.prependBaseUri(request, "/static/utils.js")}></script> ++
<script src={UIUtils.prependBaseUri(request, "/static/executorspage.js")}></script> ++
<script>setThreadDumpEnabled({threadDumpEnabled})</script>
}
</div> UIUtils.headerSparkPage(request, "Executors", content, parent, useDataTables = true)
}
}
render()方法用来渲染页面内容,其流程如下:
1)将content内容封装好;
2)调用UIUtils.headerSparkPage()方法,将content内容响应给浏览器;
3)浏览器加载过程中会调用executorspage.js,该JS内部会通过Rest服务器根据当前applicationId,去获取allexecutos等信息,并将allexecutos信息按照模板executorspage-template.html渲染到executors页面上。
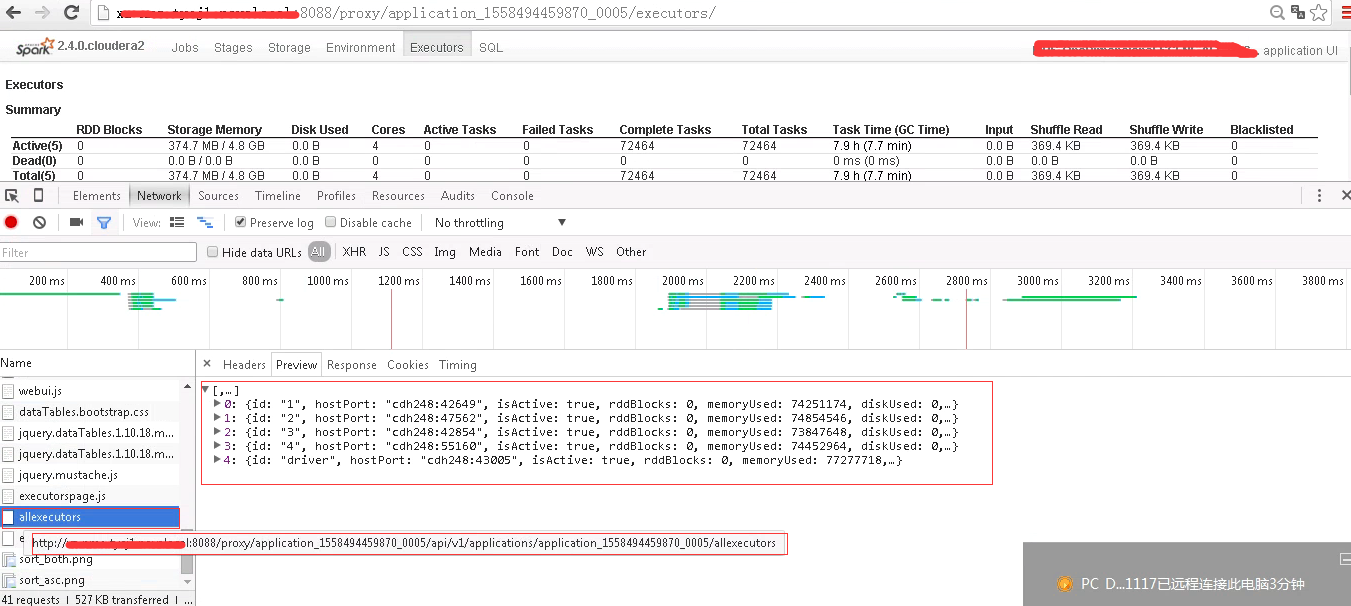
spark rest 服务实现代码路径:https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/status/api/v1/
返回allexecutors信息的方法:
@GET
@Path("allexecutors")
def allExecutorList(): Seq[ExecutorSummary] = withUI(_.store.executorList(false))
这里的store正式SparkUI的store。从该方法可以看出来:实际上,spark rest服务提供的数据是存储在SparkContext的AppStatusStore对象store上。
最后看下ExecutorThreadDumpPage的代码
private[ui] class ExecutorThreadDumpPage(
parent: SparkUITab,
sc: Option[SparkContext]) extends WebUIPage("threadDump") { // stripXSS is called first to remove suspicious characters used in XSS attacks
def render(request: HttpServletRequest): Seq[Node] = {
val executorId =
Option(UIUtils.stripXSS(request.getParameter("executorId"))).map { executorId =>
UIUtils.decodeURLParameter(executorId)
}.getOrElse {
throw new IllegalArgumentException(s"Missing executorId parameter")
}
val time = System.currentTimeMillis()
val maybeThreadDump = sc.get.getExecutorThreadDump(executorId) val content = maybeThreadDump.map { threadDump =>
val dumpRows = threadDump.map { thread =>
val threadId = thread.threadId
val blockedBy = thread.blockedByThreadId match {
case Some(_) =>
<div>
Blocked by <a href={s"#${thread.blockedByThreadId}_td_id"}>
Thread {thread.blockedByThreadId} {thread.blockedByLock}</a>
</div>
case None => Text("")
}
val heldLocks = thread.holdingLocks.mkString(", ") <tr id={s"thread_${threadId}_tr"} class="accordion-heading"
onclick={s"toggleThreadStackTrace($threadId, false)"}
onmouseover={s"onMouseOverAndOut($threadId)"}
onmouseout={s"onMouseOverAndOut($threadId)"}>
<td id={s"${threadId}_td_id"}>{threadId}</td>
<td id={s"${threadId}_td_name"}>{thread.threadName}</td>
<td id={s"${threadId}_td_state"}>{thread.threadState}</td>
<td id={s"${threadId}_td_locking"}>{blockedBy}{heldLocks}</td>
<td id={s"${threadId}_td_stacktrace"} class="hidden">{thread.stackTrace.html}</td>
</tr>
} <div class="row-fluid">
<p>Updated at {UIUtils.formatDate(time)}</p>
{
// scalastyle:off
<p><a class="expandbutton" onClick="expandAllThreadStackTrace(true)">
Expand All
</a></p>
<p><a class="expandbutton hidden" onClick="collapseAllThreadStackTrace(true)">
Collapse All
</a></p>
<div class="form-inline">
<div class="bs-example" data-example-id="simple-form-inline">
<div class="form-group">
<div class="input-group">
Search: <input type="text" class="form-control" id="search" oninput="onSearchStringChange()"></input>
</div>
</div>
</div>
</div>
<p></p>
// scalastyle:on
}
<table class={UIUtils.TABLE_CLASS_STRIPED + " accordion-group" + " sortable"}>
<thead>
<th onClick="collapseAllThreadStackTrace(false)">Thread ID</th>
<th onClick="collapseAllThreadStackTrace(false)">Thread Name</th>
<th onClick="collapseAllThreadStackTrace(false)">Thread State</th>
<th onClick="collapseAllThreadStackTrace(false)">Thread Locks</th>
</thead>
<tbody>{dumpRows}</tbody>
</table>
</div>
}.getOrElse(Text("Error fetching thread dump"))
UIUtils.headerSparkPage(request, s"Thread dump for executor $executorId", content, parent)
}
}
该页面主要展示当前executor中thread运行情况。
参考:
《Apache Spark源码走读之21 -- WEB UI和Metrics初始化及数据更新过程分析》
《Spark Structrued Streaming源码分析--(四)ProgressReporter每个流处理进度计算、StreamQueryManager管理运行的流》
《Spark Core源码精读计划#13:度量系统MetricsSystem的建立》
《Spark Core源码精读计划#14:Spark Web UI界面的实现》
Spark(四十七):Spark UI 数据可视化的更多相关文章
- Spark GraphX 的数据可视化
概述 Spark GraphX 本身并不提供可视化的支持, 我们通过第三方库 GraphStream 和 Breeze 来实现这一目标 详细 代码下载:http://www.demodashi.com ...
- Spark(十七)图计算GraphX
一.图概念术语 1.1 基本概念 图是由顶点集合(vertex)及顶点间的关系集合(边edge)组成的一种数据结构. 这里的图并非指代数中的图.图可以对事物以及事物之间的关系建模,图可以用来表示自然发 ...
- Spark学习笔记——Spark上数据的获取、处理和准备
数据获得的方式多种多样,常用的公开数据集包括: 1.UCL机器学习知识库:包括近300个不同大小和类型的数据集,可用于分类.回归.聚类和推荐系统任务.数据集列表位于:http://archive.ic ...
- Spark记录-本地Spark读取Hive数据简单例子
注意:将mysql的驱动包拷贝到spark/lib下,将hive-site.xml拷贝到项目resources下,远程调试不要使用主机名 import org.apache.spark._ impor ...
- Spark(四) -- Spark工作机制
一.应用执行机制 一个应用的生命周期即,用户提交自定义的作业之后,Spark框架进行处理的一系列过程. 在这个过程中,不同的时间段里,应用会被拆分为不同的形态来执行. 1.应用执行过程中的基本组件和形 ...
- 量化派基于Hadoop、Spark、Storm的大数据风控架构--转
原文地址:http://www.csdn.net/article/2015-10-06/2825849 量化派是一家金融大数据公司,为金融机构提供数据服务和技术支持,也通过旗下产品“信用钱包”帮助个人 ...
- Spark使用Java读取mysql数据和保存数据到mysql
原文引自:http://blog.csdn.net/fengzhimohan/article/details/78471952 项目应用需要利用Spark读取mysql数据进行数据分析,然后将分析结果 ...
- spark新能优化之数据本地化
数据本地化的背景: 数据本地化对于Spark Job性能有着巨大的影响.如果数据以及要计算它的代码是在一起的,那么性能当然会非常高.但是,如果数据和计算它的代码是分开的,那么其中之一必须到另外一方的机 ...
- [Spark性能调优] 第四章 : Spark Shuffle 中 JVM 内存使用及配置内幕详情
本课主题 JVM 內存使用架构剖析 Spark 1.6.x 和 Spark 2.x 的 JVM 剖析 Spark 1.6.x 以前 on Yarn 计算内存使用案例 Spark Unified Mem ...
随机推荐
- jenkens 安装是git版本过低 升级
Jenkins本机默认使用"yum install -y git" 安装的git版本比较低,应该自行安装更高版本的git. 查看jenkins本机的git版本 1 2 [root@ ...
- JSON空值处理与 StringUtils工具类使用
JSON 动态查询时,需要的条件本应是null,前端传入的是" " //null转换为"" private static ValueFilter filter ...
- 关于RGBDSLAMV2学习、安装、调试过程
Step1:https://github.com/felixendres/rgbdslam_v2/wiki/Instructions-for-Compiling-Rgbdslam-(V2)-on-a- ...
- 2013.6.24 - OpenNE第四天
今天晚上跟师兄讨论,这那几篇论文,对于<领域多词表 达翻译对的自动抽取及其应用>那篇,我的感觉是跟实体识别不太吻合.他的大概意思就是先讲所有有可能的多词表达都找出来,然后在用C-value ...
- 生成1~n的排列(模板),生成可重集的排列(对应紫书P184, P185)
生成1~n的排列: #include<iostream> using namespace std; void print_permutation(int n, int *A, int cu ...
- Bias vs. Variance(2)--regularization and bias/variance,如何选择合适的regularization parameter λ(model selection)
Linear regression with regularization 当我们的λ很大时,hθ(x)≍θ0,是一条直线,会出现underfit:当我们的λ很小时(=0时),即相当于没有做regul ...
- Visual Studio 2017 许可证已过期解决方案
1.卸载并重安VS2017 2.安装后打开VS2017,点击帮助=>注册产品,输入序列号NJVYC-BMHX2-G77MM-4XJMR-6Q8QF(企业版), KBJFW-NXHK6-W4WJM ...
- 关于Djiango中 前端多对多字段点(,)的显示问题
去除点的方法: <td> {% for roles_son in roles.permissions.all %} {% if forloop.last %} # 利用模板语言中的循环机制 ...
- 关于 or 判断都是Ture的问题
问题: 1. ret1 = [1, 2, 3, 4] if 11 or 33 in ret1: print("ok") else: print("no") 2. ...
- 学到了林海峰,武沛齐讲的Day34 完 线程 进程 协程 很重要
线程 进程 协程 很重要 ...儿子满月回家办酒,学的有点慢,坚持