SparkStreaming运行原理
SparkStreaming运行原理的更多相关文章
- SparkStreaming 运行原理与核心概念
SparkStreaming 运行原理 sparkstreaming 的高层抽象DStream Dstream与RDD的关系 Batch duration
- Spark Streaming概念学习系列之SparkStreaming运行原理
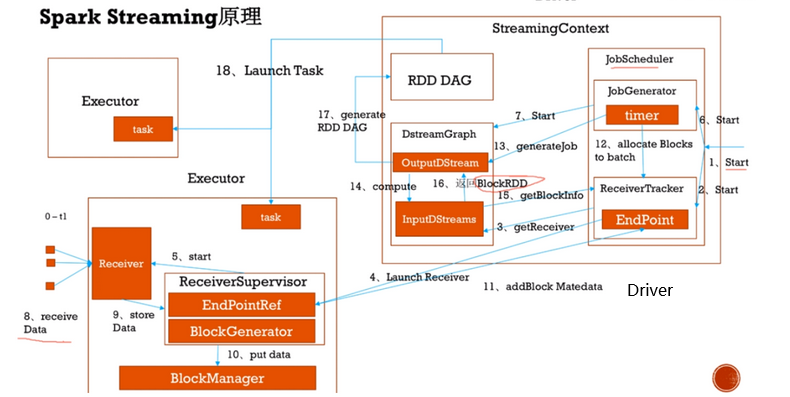
SparkStreaming运行原理 Spark Streaming不断的从数据源获取数据(连续的数据流),并将这些数据按照周期划分为batch. Spark Streaming将每个batch的数据 ...
- Flink 集群运行原理兼部署及Yarn运行模式深入剖析
1 Flink的前世今生(生态很重要) 原文:https://blog.csdn.net/shenshouniu/article/details/84439459 很多人可能都是在 2015 年才听到 ...
- iis6.0与asp.net的运行原理
这几天上网翻阅了不少前辈们的关于iis和asp.net运行原理的博客,学的有点零零散散,花了好长时间做了一个小结(虽然文字不多,但也花了不少时间呢),鄙人不才,难免有理解不道的地方,还望前辈们不吝赐教 ...
- ASP.NET Core 运行原理剖析2:Startup 和 Middleware(中间件)
ASP.NET Core 运行原理剖析2:Startup 和 Middleware(中间件) Startup Class 1.Startup Constructor(构造函数) 2.Configure ...
- ASP.NET Core 运行原理剖析1:初始化WebApp模版并运行
ASP.NET Core 运行原理剖析1:初始化WebApp模版并运行 核心框架 ASP.NET Core APP 创建与运行 总结 之前两篇文章简析.NET Core 以及与 .NET Framew ...
- 场景9 深入RAC运行原理
场景9 深入RAC运行原理 OPS(Oracle Parallel Server)通过磁盘的节点判定数据是否最新 —> Data Guard —> RAC(Real Ap ...
- Camel运行原理分析
Camel运行原理分析 以一个简单的例子说明一下camel的运行原理,例子本身很简单,目的就是将一个目录下的文件搬运到另一个文件夹,处理器只是将文件(限于文本文件)的内容打印到控制台,首先代码如下: ...
- Web程序的运行原理及流程(一)
自己做Web程序的开发也有两年多了 从最开始跟风学框架 到第一用上框架的欣喜若狂 我相信每个程序员都是这样过来的 在大学学习一门语言 学会后往往很想做一个实际的项目出来 我当时第一次做WEB项目看 ...
随机推荐
- CentOS忘记密码修改方案以及centos卡在开机登录界面,命令失效的解决方法
CentOS忘记密码修改方案 应用场景 linux管理员忘记root密码,需要进行找回操作. 注意事项:本文基于CentOS7.2环境进行操作的,由于CentOS的版本之间是有差异的,继续之前请先确定 ...
- Linux常用基础(三)
1.gcc编译器 (1)简介 前期的GCC是GNU C Compiler,仅仅用于C语言的编译,经过多年的发展,现在的GCC为GNU Compiler Collection,并且目前支持多种编程语言的 ...
- 【转帖】普通程序员如何转向AI方向
普通程序员如何转向AI方向 https://www.cnblogs.com/subconscious/p/6240151.html 眼下,人工智能已经成为越来越火的一个方向.普通程序员,如何转向人工智 ...
- [转帖]算法精解:DAG有向无环图
算法精解:DAG有向无环图 https://www.cnblogs.com/Evsward/p/dag.html DAG是公认的下一代区块链的标志.本文从算法基础去研究分析DAG算法,以及它是如何运用 ...
- Apache Kafka使用默认配置执行一些负载测试来完成性能测试和基准测试
Kafka是一种分布式,分区,复制的提交日志服务.它提供了消息传递系统的功能. 我们先来看看它的消息传递术语: Kafka在称为主题的类别中维护消息的提要. 我们将调用向Kafka主题生成器发布消 ...
- go ---作用域及判断变量类型的方式。
package main import ( "fmt" ) var v = "1, 2, 3" func main() { v := []int{1, 2, 3 ...
- texstudio基本设置
一开始默认为英文,在上面菜单栏,“option” 1.设置中文:options->general->language->zh-cn 2.编辑和查看按钮: 3.设置默认编译器:选项-& ...
- 浅浅的叙WPF之数据驱动与命令
之前一直开发Winfrom程序,由于近一段时间转开发Wpf程序,刚好拜读刘铁锰<深入浅出WPF>对此有一些理解,如有误导指出,还望斧正!!! 说道WPF数据驱动的编程思想,MVVM,是为W ...
- Git 理解修改
参考链接:https://www.liaoxuefeng.com/wiki/896043488029600/897884457270432 Git之所以比其他版本控制系统设计得优秀,就是因为Git跟踪 ...
- Java IO---缓冲流和转换流
一. 缓冲流 缓冲流是处理流的一种,也叫高效流,是对4个基本输入输出流的增强,它让输入输出流具有1个缓冲区,能显著减小与外部的IO次数,从而提高读写的效率,并且提供了一些额外的读写方法. 因为 ...