【原创】Kafka console consumer源代码分析(一)
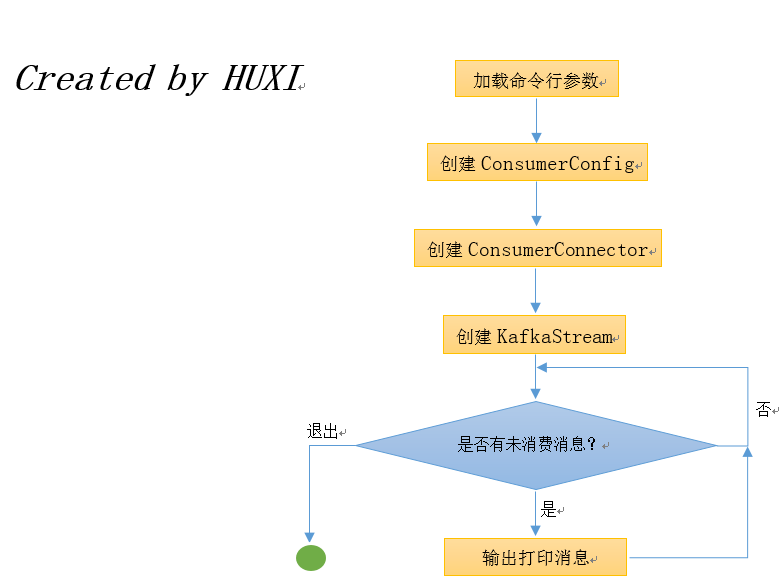
本质上来说,console consumer启动时会创建一个KafkaStream(可以简单翻译成Kafak流),该stream会不停地等待可消费的新消息——具体做法就是通过LinkedBlockingQueue阻塞队列来实现,后续会有详细描述。针对上面启动的顺序列表,我们在ConsoleConsumer.scala中逐一进行代码走读:
// REQUIRED表示这是一个必须要指定的参数
val zkConnectOpt = parser.accepts("zookeeper", "REQUIRED: The connection string for the zookeeper connection in the form host:port. " +
"Multiple URLS can be given to allow fail-over.").withRequiredArg.describedAs("urls").ofType(classOf[String])
2. 生成group.id
// 如果没有显式指定group.id,那么代码就自己合成一个
// 具体格式: console-consumer-[10万以内的一个随机数]
// 10万是一个很大的数,因此只有非常低的几率会碰到多个console consumer的group id相同的情况
if(!consumerProps.containsKey("group.id")) {
consumerProps.put("group.id","console-consumer-" + new Random().nextInt(100000))
groupIdPassed=false
}
3. 创建ConsumerConfig对象封装配置
确定了consumer的group.id之后console consumer需要把传入参数封装进ConsumerConfig类中并把后者传给Consumer的create方法以构造一个ConsumerConnector——即初始化consumer了,具体逻辑见下面的代码:
val config = new ConsumerConfig(consumerProps) // 封装ConsumerConfig配置类
val skipMessageOnError = if (options.has(skipMessageOnErrorOpt)) true else false
4. 创建默认的消息格式化类,其定义的writeTo方法会默认将消息输出到控制台
val messageFormatterClass = Class.forName(options.valueOf(messageFormatterOpt)) // 创建消息格式类,用于最后的输出显示
val formatterArgs = CommandLineUtils.parseKeyValueArgs(options.valuesOf(messageFormatterArgOpt))
val maxMessages = if(options.has(maxMessagesOpt)) options.valueOf(maxMessagesOpt).intValue else -1
5. 创建ZookeeperConsumerConnector
ZookeeperConsumerConnector非常重要,它实现了ConsumerConnector接口(该接口定义了创建KafkaStream和提交位移的操作,如createMessageStreams、commitOffsets等)。Kakfa官网把这个接口称为high level的consumer API。对于大多数consumer来说,这个high level的consumer API提供的功能已经足够了。不过很多用户可能需要对位移有更大的控制,这个时候Kafka推荐用户使用被称为low level的consumer API—— SimpleConsumer。大家参考这篇文章来深入学习high level API的用法。目前为止,我们只需要知道Kafka通过下面的语句构建了ConsumerConnector这个consumer的核心接口:
val connector = Consumer.create(config) // 创建ConsumerConnector,Consumer核心接口
val stream = connector.createMessageStreamsByFilter(filterSpec, 1, new DefaultDecoder(), new DefaultDecoder()).get(0)
val iter = if(maxMessages >= 0)
stream.slice(0, maxMessages)
else
stream
for(messageAndTopic <- iter) {
try {
formatter.writeTo(messageAndTopic.key, messageAndTopic.message, System.out) // 输出到控制台
numMessages += 1
} catch { ... }
...
}
好了,至此我们按照启动顺序概述了console consumer启动时的各个阶段。不过,ZookeeperConsumerConnector和创建和迭代器的实现我们并未详细展开,这部分内容将作为后面续篇的内容呈现给大家。敬请期待!
【原创】Kafka console consumer源代码分析(一)的更多相关文章
- 【原创】Kafka console consumer源代码分析(二)
我们继续讨论console consumer的实现原理,本篇着重探讨ZookeeperConsumerConnector的使用,即后续所有的内容都由下面这条语句而起: val connector = ...
- 【原创】kafka consumer源代码分析
顾名思义,就是kafka的consumer api包. 一.ConsumerConfig.scala Kafka consumer的配置类,除了一些默认值常量及验证参数的方法之外,就是consumer ...
- 【原创】Kakfa utils源代码分析(三)
Kafka utils包最后一篇~~~ 十五.ShutdownableThread.scala 可关闭的线程抽象类! 继承自Thread同时还接收一个boolean变量isInterruptible表 ...
- 【原创】Kakfa utils源代码分析(二)
我们继续研究kafka.utils包 八.KafkaScheduler.scala 首先该文件定义了一个trait:Scheduler——它就是运行任务的一个调度器.任务调度的方式支持重复执行的后台任 ...
- 【原创】Kakfa utils源代码分析(一)
Kafka.utils,顾名思义,就是一个工具套件包,里面的类封装了很多常见的功能实现——说到这里,笔者有一个感触:当初为了阅读Kafka源代码而学习了Scala语言,本以为Kafka的实现会用到很多 ...
- Kafka 源代码分析之LogManager
这里分析kafka 0.8.2的LogManager logmanager是kafka用来管理log文件的子系统.源代码文件在log目录下. 这里会逐步分析logmanager的源代码.首先看clas ...
- Kafka 0.10 SocketServer源代码分析
1概要设计 Kafka SocketServer是基于Java NIO来开发的,采用了Reactor的模式,其中包含了1个Acceptor负责接受客户端请求,N个Processor负责读写数据,M个H ...
- Spark SQL 源代码分析之 In-Memory Columnar Storage 之 in-memory query
/** Spark SQL源代码分析系列文章*/ 前面讲到了Spark SQL In-Memory Columnar Storage的存储结构是基于列存储的. 那么基于以上存储结构,我们查询cache ...
- Spark SQL Catalyst源代码分析之TreeNode Library
/** Spark SQL源代码分析系列文章*/ 前几篇文章介绍了Spark SQL的Catalyst的核心执行流程.SqlParser,和Analyzer,本来打算直接写Optimizer的,可是发 ...
随机推荐
- Microservice 微服务的理论模型和现实路径
两年前接触到了微服务的概念,面对日益膨胀的系统感觉豁然开朗.之后的两年逐步把系统按微服务的架构理念进行了重构,并将业务迁移到了新架构之上.感觉现在差不多是时候写一篇关于微服务的总结文章了. 定义 在 ...
- 仿花田:相亲网站 意中人 已在GitHub上开源
在园友的强烈呼唤下,我还是负责任的分享给大家,因为对代码比较熟悉一下,还是有些问题要说明,不然别人看起来会比较费劲.说实话除了这个bootstrap的界面风格和这件事情本身对大家有吸引力之外,内部的逻 ...
- [.net 面向对象程序设计进阶] (19) 异步(Asynchronous) 使用异步创建快速响应和可伸缩性的应用程序
[.net 面向对象程序设计进阶] (19) 异步(Asynchronous) 使用异步创建快速响应和可伸缩性的应用程序 本节导读: 本节主要说明使用异步进行程序设计的优缺点及如何通过异步编程. 使用 ...
- 表格搞定 Asp.net Web 状态管理
最近在网上搜罗了 ASP.NET WEB 状态管理方面的一些内容,终于把这些内容整合总结了一下. 1. 希望自己通过整理,能够掌握一些,为自己投资. 2. 以便自己忘记,又要浪费时间搜罗. 3. 希望 ...
- 为CentOS7(文字界面操作)系统安装gnome图形界面程序
1.安装gnome sudo yum groupinstall "GNOME Desktop" "Graphical Administration Tools" ...
- 导入镜像文件,分区启动liunx
1:更改虚拟机配置 2:导入系统镜像 3:启动虚拟机,选择第一个选项回车 4:这里问你是否检查镜像,我们的镜像肯定没问题不需要检查,点击Skip 5:语言选择,按提示默认下一步 6:主机名也默认 7: ...
- C#中通过反射方法获取控件类型和名称
这个方法是简单的也是神奇的. 有木有想过,将自己项目中的所有类型,包括自定义类型的命名空间和名称全部获取出来? 有木有想过,有一种简便的方法可以自动化管理项目中的控件和窗体? 有木有想过... 首先, ...
- 美图WEB开放平台环境配置
平台环境配置 1.1.设置crossdomain.xml 下载crossdomain.xml文件,把解压出来的crossdomain.xml文件放在您保存图片或图片来源的服务器根目录下,比如: htt ...
- 关于ie11 的开发者工具
win7旗舰系统64为,更新ie11: 新安装了ie11浏览器,安装以后发现原来可以正常使用的开发者工具不能使用,提示 Imposible use F12 Developer Tools (Excep ...
- Ado.Net Destination 用法
Ado Net Destination Component 使用Ado net Connection manager,其Data Access Mode 只有一种, table or view,组件的 ...