solr添加中文IK分词器,以及配置自定义词库
Solr是一个基于Lucene的Java搜索引擎服务器。Solr 提供了层面搜索、命中醒目显示并且支持多种输出格式(包括 XML/XSLT 和 JSON 格式)。它易于安装和配置,而且附带了一个基于HTTP 的管理界面。Solr已经在众多大型的网站中使用,较为成熟和稳定。Solr 包装并扩展了Lucene,所以Solr的基本上沿用了Lucene的相关术语。更重要的是,Solr 创建的索引与 Lucene搜索引擎库完全兼容。通过对Solr 进行适当的配置,某些情况下可能需要进行编码,Solr 可以阅读和使用构建到其他 Lucene 应用程序中的索引。此外,很多 Lucene 工具(如Nutch、Luke)也可以使用Solr 创建的索引。
solr默认是不支持中文分词的,这样就需要我们手工配置中文分词器,在这里我们选用IK Analyzer中文分词器。
IK Analyzer下载地址:https://code.google.com/p/ik-analyzer/downloads/list
如图: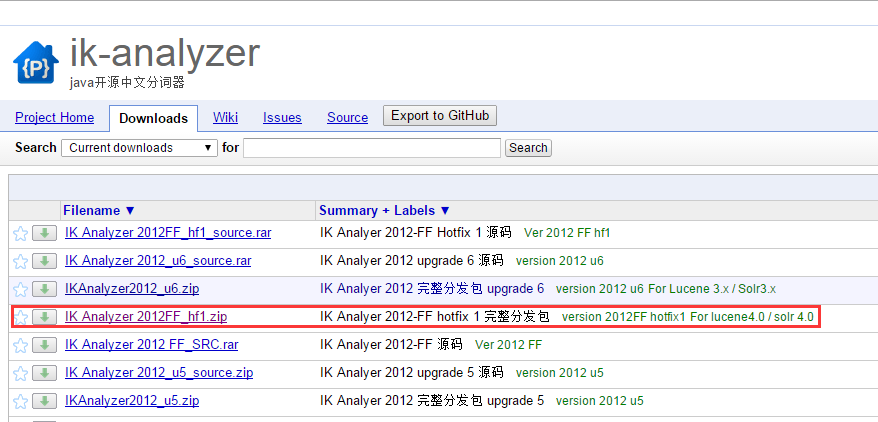
默认大家已经下载并解压了solr,在这里我们使用solr 4.10.4版本
试验环境centos 6.5 ,JDK1.7
整合步骤
1:解压下载的IK Analyzer_2012_FF_hf1.zip压缩包,把IKAnalyzer2012FF_u1.jar拷贝到solr-4.10.4/example/solr-webapp/webapp/WEB-INF/lib目录下
2:在solr-4.10.4/example/solr-webapp/webapp/WEB-INF目录下创建目录classes,然后把IKAnalyzer.cfg.xml和stopword.dic拷贝到新创建的classes目录下即可。
3:修改solr core的schema文件,默认是solr-4.10.4/example/solr/collection1/conf/schema.xml,添加如下配置
<fieldType name="text_ik" class="solr.TextField">
<!--索引时候的分词器-->
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<!--查询时候的分词器-->
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
4:启动solr,bin/solr start
5:进入solr web界面http://localhost:8983/solr,看到下图操作结果即为配置成功
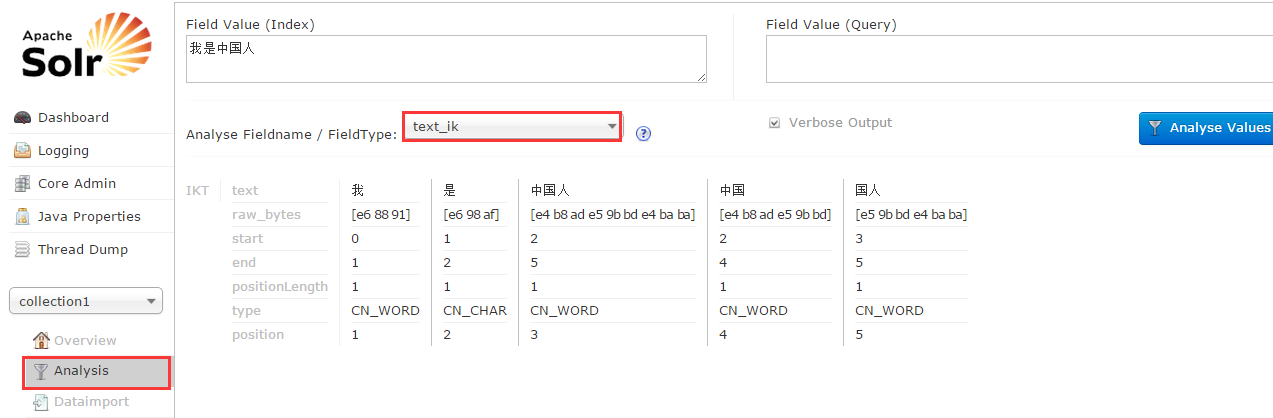
到现在为止,solr就和IK Analyzer中文分词器整合成功了。
但是,如果我想自定义一些词库,让IK分词器可以识别,那么就需要自定义扩展词库了。
操作步骤:
1:修改solr-4.10.4/example/solr-webapp/webapp/WEB-INF/classes目录下的IKAnalyzer.cfg.xml配置文件,添加如下配置
<entry key="ext_dict">ext.dic;</entry>
2:新建ext.dic文件,在里面添加如下内容(注意:ext.dic的编码必须是Encode in UTF-8 without BOM,否则自定义的词库不会被识别)
超人学院
3:重启solr
4:在solr web界面进行如下操作,看到图中操作结果即为配置成功。
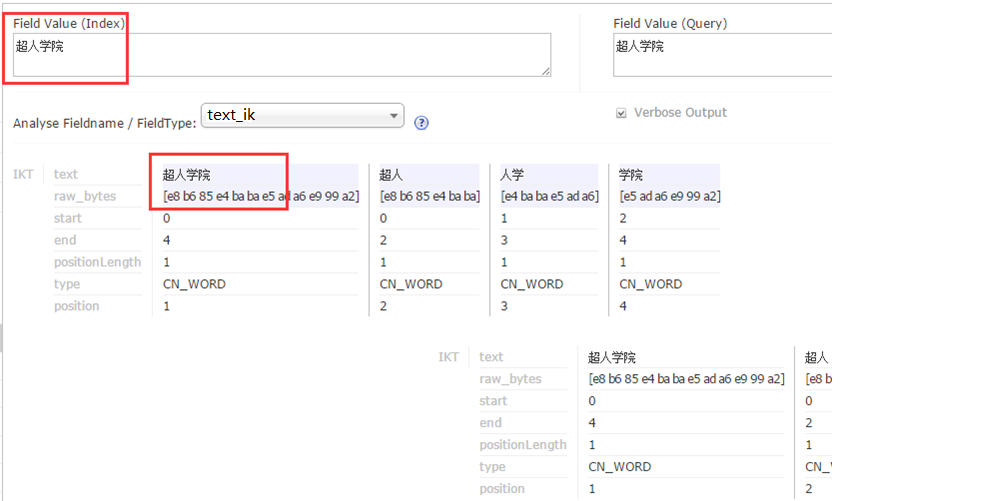
solr添加中文IK分词器,以及配置自定义词库的更多相关文章
- Solr4.4入门,介绍Solr的安装、IK分词器的配置及高亮查询结果(转)
一.Windows下安装solr-4.4.0 1. 下载solr.4.4 2. 下载绿色版tomcat6.0.18 3. 解压下载的solr到d:\study\solr,将dist目录下的sol ...
- 如何开发自己的搜索帝国之安装ik分词器
Elasticsearch默认提供的分词器,会把每个汉字分开,而不是我们想要的根据关键词来分词,我是中国人 不能简单的分成一个个字,我们更希望 “中国人”,“中国”,“我”这样的分词,这样我们就需要 ...
- Elasticsearch教程(二),IK分词器安装
elasticsearch-analysis-ik 是一款中文的分词插件,支持自定义词库,也有默认的词库. 开始安装. 1.下载 下载地址为:https://github.com/medcl/ela ...
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例二.
为了更好的排版, 所以将IK分词器的安装重启了一篇博文, 大家可以接上solr的安装一同查看.[Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一: http://ww ...
- 三、Solr多核心及分词器(IK)配置
多核心的概念 多核心说白了就是多索引库.也可以理解为多个"数据库表" 说一下使用multicore的真实场景,比若说,产品搜索和会员信息搜索,不使用多核也没问题,这样带来的问题是 ...
- Solr多核心及分词器(IK)配置
Solr多核心及分词器(IK)配置 多核心的概念 多核心说白了就是多索引库.也可以理解为多个"数据库表" 说一下使用multicore的真实场景,比若说,产品搜索和会员信息搜索 ...
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一.
在这里一下讲解着三个的安装和配置, 是因为solr需要使用tomcat和IK分词器, 这里会通过图文教程的形式来详解它们的安装和使用.注: 本文属于原创文章, 如若转载,请注明出处, 谢谢.关于设置I ...
- Solr和IK分词器的整合
IK分词器相对于mmseg4J来说词典内容更加丰富,但是没有mmseg4J灵活,后者可以自定义自己的词语库.IK分词器的配置过程和mmseg4J一样简单,其过程如下: 1.引入IKAnalyzer.j ...
- ElasticSearch7.3学习(十五)----中文分词器(IK Analyzer)及自定义词库
1. 中文分词器 1.1 默认分词器 先来看看ElasticSearch中默认的standard 分词器,对英文比较友好,但是对于中文来说就是按照字符拆分,不是那么友好. GET /_analyze ...
随机推荐
- Mysql一些常见语句
Mysql一些常见语句 (1)展示所有的数据库名 SHOW DATABASES (2)选中某一个数据库 USE 数据库名字 (3)查看某一个表的结构 DESC 表名 (4)数据库的创建 CREATE ...
- sublme text 3 快捷键
1. 插件 codeFormatter 格式化插件 json格式化MAC快捷键 control + option + F
- 浏览器性能监控performance使用
浏览器中有一个performance的性能监控,平时我也没有用到,接手了一个大数据的项目,发现页面打开的比较慢,使用浏览器的performance分析可以看到各个步骤花费的时间. 关于项目的性能分析如 ...
- Redis : REmote DIctionary Server
REmote DIctionary Server(Redis) 是一个由Salvatore Sanfilippo写的key-value存储系统. Redis是一个开源的使用ANSI C语言编写.遵守B ...
- Ansible自动部署tomcat
1.首先准备3台机器 ansible机器:192.168.52.34 目标主机:192.168.52.35 目标主机:192.168.52.36 2.关闭防火墙 [root@localhost ~]# ...
- MySQL8.0忘记密码后重置密码(亲测有效)
实测,在mysql8系统下,用mysqld --console --skip-grant-tables --shared-memory可以无密码启动服务 服务启动后,以空密码登入系统 mysql.ex ...
- CCF 201812-3 CIDR合并
CCF 201812-3 CIDR合并 //100分 93ms #include<stdio.h>//CCF上stdio.h比cstdio快!!! #include<string.h ...
- 【CSGRound2】逐梦者的初心(洛谷11月月赛 II & CSG Round 2 T3)
题目描述# 给你一个长度为\(n\)的字符串\(S\). 有\(m\)个操作,保证\(m≤n\). 你还有一个字符串\(T\),刚开始为空. 共有两种操作. 第一种操作: 在字符串\(T\)的末尾加上 ...
- nginx 反向代理之 proxy_cache
proxy_cache将从C上获取到的数据根据预设规则存放到B上(内存+磁盘)留着备用,A请求B时,B会把缓存的这些数据直接给A,而不需要再去向C去获取. proxy_cache相关功能生效的前提是, ...
- pathlib.Path 类的使用
from pathlib import Path 参考 https://www.jb51.net/article/148789.htm