awk(gawk)文本报告生成器
awk是gawk的链接文件,是一种优良的文本处理工具,实现格式化文本输出,是Linux和Unix现有环境中功能最强大的数据处理引擎之一。这种编程及数据操作语言的最大功能取决于一个人拥有的知识量,使用"man gawk"给出的简述为“模式扫描和处理语言”。
任何awk语句都是由模式和动作组成,一个awk脚本可以有多个语句,模式决定动作语句的触发条件和触发时间。
模式包含:正则表达式,/[正则表达式]/;关系运算符,<、<=、>、>=、!=、==;正则运算符,~(匹配)、!~(不匹配);赋值运算符,=、+=、-=、*=、/=、%=、**=;逻辑运算符||、&&;算术运算符+、-、*、/、++、--;其他运算符,$(用来对字段进行引用),空格(字符串连接符)。
动作包含:变量、命令、内置函数、流程控制语句。
语法:awk [选项] 'BEGIN{开始语句} 模式{动作} END{结束语句}' [文件]。其中BEGIN和END是awk的关键字,必须大写。不过开始模块和结束模块是可选部分,可以省略。并且开始语句和结束语句也是动作语句。另外,工作模块中的模式和动作可以都存在,也可以二者选其一。如果省略模式,那么文件的所有行都执行动作;如果省略动作,表示对符合条件的行执行默认的print动作。正因为可以二者选其一,所以一般用{}包裹动作,用于区分模式和动作。
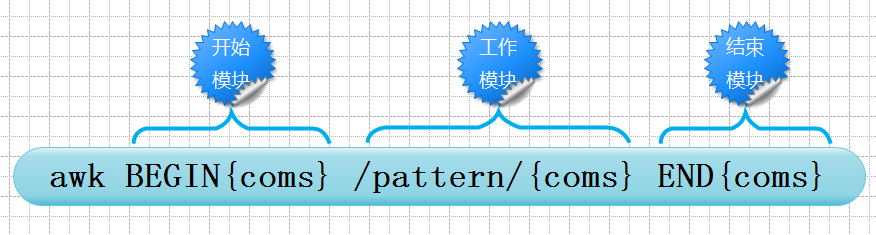
(1).特殊模块BEGIN和END
在awk中BEGIN和END都只能执行一次。BEGIN语句在动作语句之前执行,一般用于设置变量计数的起始值,打印头部信息和改变字段的分隔符。END语句在完成动作语句之后执行,一般用于输出统计结果,打印结尾信息。
(2).执行过程
awk的执行过程(工作步骤)可以简单分为一下几步:第一步,执行BRGIN模块;第二步,从文件、管道或标准输入中读取一行保存到内存中;第三步,对读取的行数据执行工作模块;第四步,判断是否到达文件、管道或标准输入的结尾,如果未到达结尾则重复第二步和第三步;第五步,到达文件、管道或标准输入的结尾后,执行END模块。
图示执行过程如下:

(3).awk的内置变量
awk支持两种不同的变量:内置变量和自定义变量。其中内置变量是awk自带的预定义变量。awk的内置变量如下
$n 表示当前行(记录)的第n个字段,比如$1表示第一个字段,$2表示第二个字段,以此类推
$0 表示执行过程中当前行(记录)的文本内容
FILENAME 表示当前行(记录)所在的文件名称
FS 表示字段分隔符,默认为空格
NF 表示字段数,在执行过程中当前行(记录)的总字段数,即存在多少列
FNR 表示当前行(记录)在当前文件的行(记录)号,从1开始
NR 表示执行过程中到目前位置的总行(记录)号,从1开始
OFS 表示输出字段分隔符,默认一个空格
ORS 表示输出行(记录)分隔符,默认一个换行符
RS 表示行(记录)分隔符,默认一个换行符

(4).常用选项
标准:
-f [脚本文件],--file=[脚本文件] 指定脚本文件,从脚本中读取awk命令
-F [字段分隔符],--field-separator=[字段分隔符] 指定FS(字段分隔符)
-v [变量名=变量值],--assign=[变量名=变量值] 创建一个自定义变量,并赋值
(5).实例
1)定义分隔符
定义分隔符可以使用-F选项指定,也可以在BEGIN模块中使用FS赋值进行更改
[root@youxi1 ~]# echo "A,B,C,D,E" | awk -F, '{print $2}'
B
[root@youxi1 ~]# echo "A,B;C,D;E" | awk -F"[,;]" '{print $2}'
B
[root@youxi1 ~]# echo "A,B;C,D;E" | awk 'BEGIN{FS=","} {print $2}'
B;C
[root@youxi1 ~]# echo "A,B;C,D;E" | awk 'BEGIN{FS="[,;]"} {print $2}'
B
2)awk内置变量
FS/OFS(输入/输出字段分隔符)、RS/ORS(输入/输出记录分隔符)
[root@youxi1 ~]# cp /etc/passwd .
[root@youxi1 ~]# awk 'BEGIN{FS=":";OFS="|";RS="\n";ORS=" "} {print $1}' passwd
root bin daemon adm lp sync shutdown halt mail operator games ftp nobody systemd-network dbus polkitd sshd postfix chrony
NF(当前行的总字段数)
[root@youxi1 ~]# vim NF.txt
root:x
root:1:x
root:1:2:x
root:1:2:3:x
[root@youxi1 ~]# awk -F: '{print NF}' NF.txt
2
3
4
5
[root@youxi1 ~]# awk -F: '{print $(NF-1)}' NF.txt
root
1
2
3
FNR(在当前文件的当前行号)、NR(在执行过程中的当前行号)
[root@youxi1 ~]# cat a
1234
[root@youxi1 ~]# cat b
abcd
1234
[root@youxi1 ~]# awk '{print FNR}' a b
1
1
2
[root@youxi1 ~]# awk '{print NR}' a b
1
2
3
FILENAME(当前行所在的文件名称)
[root@youxi1 ~]# awk '{print FILENAME}' passwd a b NF.txt
passwd
passwd
passwd
passwd
passwd
passwd
passwd
passwd
passwd
passwd
passwd
passwd
passwd
passwd
passwd
passwd
passwd
passwd
passwd
a
b
b
NF.txt
NF.txt
NF.txt
NF.txt
3)动作语句
awk的变量可以从外部传参,也可以内部自定义。详见:linux shell awk获得外部变量(变量传值)简介;linux awk数组操作详细介绍。这里主要介绍一下外部传参和自定义数组,如下:
//获取普通外部变量
[root@youxi1 ~]# test="awk code"
[root@youxi1 ~]# echo |awk '{print test}' test="$test"
awk code
//BEGIN模块获取普通外部变量
[root@youxi1 ~]# echo |awk -v test="$test" 'BEGIN{print test}'
awk code
//获取环境变量
[root@youxi1 ~]# awk 'BEGIN{for (i in ENVIRON) {print i"="ENVIRON[i];}}'
AWKPATH=.:/usr/share/awk
LANG=zh_CN.UTF-8
HISTSIZE=1000
XDG_RUNTIME_DIR=/run/user/0
USER=root
_=/usr/bin/awk
TERM=linux
SHELL=/bin/bash
...... //手动自定义数组
[root@youxi1 ~]# awk 'BEGIN{list[1]=1;list[two]=2;print list[1],list[two]}'
1 2
//数组的下标并非一定为数字,也可以是字符串
[root@youxi1 ~]# awk 'BEGIN{list["abc"]=3;list["xyz"]=4;print list["abc"],list["xyz"]}'
3 4
//通过函数将字符串转换为数组
[root@youxi1 ~]# awk 'BEGIN{string="hello world This is String";split(string,list," ");print list[2]}'
world
//获取数组长度
[root@youxi1 ~]# awk 'BEGIN{string="it is a test";lens=split(string,list," ");print length(list),lens}'
4 4 //split函数切割字符串可以返回新生成的数组长度,也可以使用length函数获取数组长度
[root@youxi1 ~]# awk 'BEGIN{string="it is a test";split(string,list," ");print asort(list)}'
4 //asort函数排序也可以获取数组长度
//删除键值
[root@youxi1 ~]# awk 'BEGIN{list[1]=1;list[2]=2;delete list[1];for (i in list){print i,list[i];}}'
2 2
//二维数组或多维数组
[root@youxi1 ~]# awk 'BEGIN{list[1,1]=1;list[1,2]=2;print list[1,1]}'
1
awk的内置函数主要分为算术函数、字符串函数、时间函数、其他一般函数。详见:linux awk 内置函数详细介绍(实例)。这里主要介绍printf格式化输出函数,函数格式为printf "格式",变量1,变量2...。注意事项:printf不会自动打印换行符,转义换行符\n一般在格式的最后。
| 格式符 | 说明 |
| %d | 十进制有符号整数 |
| %u | 十进制无符号整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %c | 单个字符 |
| %p | 指针的值 |
| %e | 指数形式的浮点数 |
| %x | %X 无符号以十六进制表示的整数 |
| %o | 无符号以八进制表示的整数 |
| %g | 自动选择合适的表示法 |
printf实例如下:
[root@youxi1 ~]# awk -F: '/root/{printf "USERNAME:%s\n",$1}' /etc/passwd
USERNAME:root
USERNAME:operator
//在格式符中间加一个数字可以控制格式符的长度
[root@youxi1 ~]# awk -F: '/root/{printf "%10s\n",$1}' /etc/passwd
root
operator
//在格式符中间加一个减号,可以使得格式符左对齐
[root@youxi1 ~]# awk -F: '/root/{printf "%-10s\n",$1}' /etc/passwd
root
operator
//做一个awk文件实例
[root@youxi1 ~]# vim test.awk
BEGIN{
print "UserID\t\t\tShell"
print "-----------------------------------"
FS=":"
}
$3>=500 && $NF=="/sbin/nologin"{
printf "%-20s%-20s\n",$1,$NF
}
END{
print "-----------------------------------"
}
[root@youxi1 ~]# awk -f test.awk /etc/passwd
UserID Shell
-----------------------------------
polkitd /sbin/nologin
chrony /sbin/nologin
-----------------------------------
awk的流程控制语句:条件判断语句(if、?:)、循环语句(do-while、while、for)。详见:linux shell awk 流程控制语句(if,for,while,do)详细介绍。
if语句格式如下:
if (判断表达式1) {
语句1
}
else if (判断表达式2) {
语句2
}
else {
语句3
}
?:语句其实就是if-else语句(双分支语句)的缩写,格式如下:
判断表达式?成立时执行语句:不成立时执行语句
do-while语句格式如下:
do{
语句
} while (判断条件)
while语句格式如下:
while (判断表达式) {
语句
}
for语句格式如下:
for (变量 in 数组) {
语句
}
for (变量;判断条件;表达式) {
语句
}
awk动作语句调用shell命令,该方法需要通过system()函数。如下:
[root@youxi1 ~]# ls
anaconda-ks.cfg test.awk
[root@youxi1 ~]# vim filename
a
b
c
d
[root@youxi1 ~]# awk '{cmd="touch "$0;system(cmd)}' filename
[root@youxi1 ~]# ls
a anaconda-ks.cfg b c d filename test.awk
[root@youxi1 ~]# awk '{system("rm -rf "$0)}' filename
[root@youxi1 ~]# ls
anaconda-ks.cfg filename test.awk
参考:https://www.cnblogs.com/chengmo/archive/2013/01/17/2865479.html
awk(gawk)文本报告生成器的更多相关文章
- awk实现 文本内的换行符 为分隔符,输出变为逗号
awk实现 文本内的换行符 为分隔符,输出变为逗号 [liujianzuo@ow2 scripts]$ awk -F $ '{print $0}' ldap_member.log ruanshujun ...
- Pyp 替代sed,awk的文本处理工具
Linux上文本处理工具虽不少,像cut,tr,join,split,paste,sort,uniq,sed,awk这些经典工具让人眼花缭乱,而且都太老了,使用方法都不太人性化,尤其awk,语法简直反 ...
- 如何使用 awk 输出文本中的字段和列
首先我们要知道,awk 能够自动将输入的行,分隔为若干字段.每一个字段就是一组字符,它们和其他的字段由一个内部字段分隔符分隔开来. 如果你熟悉 Unix/Linux 或者懂得 bash shell 编 ...
- Shell基础(六):使用awk提取文本、awk处理条件、awk综合脚本应用、awk流程控制、awk扩展应用
一.使用awk提取文本 目标: 本案例要求使用awk工具完成下列过滤任务: 1> 练习awk工具的基本用法 2> 提取本机的IP地址.根分区使用率 3> 格式化输出/et ...
- 文本三剑客---awk(gawk)基础
gawk程序是Unix中原始awk程序的GNU版本.gawk程序让流编辑器迈上了一个新的台阶,它提供了一种编程语言而不只是编辑器命令.在gawk编程语言中,可以完成下面的事情: (1)定义变量来保存数 ...
- 使用awk处理文本
http://blog.wuxu92.com/using-awk/ 在Liux下我们经常需要对一些文本文档做一些处理,尤其像从日志里提取一些数据,这是我们一般会用awk工具和sed工具去实现需求,这里 ...
- awk(gawk)
awk,逐行处理文本内容.Linux里的awk其实是“gawk”. 使用格式: awk [选项] '模式匹配 {命令 命令参数}' file1, file2, …… 支持的选项 说明 -f progr ...
- 【Linux进阶】使用grep、find、sed以及awk进行文本操作
目录 一.元字符 二.grep命令 1. 过滤出包含某字符串的行 2. 过滤出以某字符串开头(结尾)的行 3. 过滤出包含某字符串及其相邻的行 4. 过滤出不包含某关键字的行 5. 过滤出包含多个字符 ...
- 一个利用sed和awk处理文本的小栗子
这两天做<Linux操作系统>课程的作业,碰到了一个题目,感觉很有意思,很考验对awk掌握的熟练度,故特意拿来分享. 首先说题目是这样的,有这样一段文本: RECORD #这是多余的注释行 ...
随机推荐
- 折腾deepin修改终端语言
原创作品,作者是博客园sogeisetsu,转载请注明来源sogeisetsu.cnblogs.com 唉-都怪当初没学扎实,改个终端语言花费了半天. 首先,介绍一下我的情况 有两个用户,一个是roo ...
- 项目Beta冲刺--7/7
项目Beta冲刺--7/7 作业要求 这个作业属于哪个课程 软件工程1916-W(福州大学) 这个作业要求在哪里 项目Beta冲刺 团队名称 基于云的胜利冲锋队 项目名称 云评:高校学生成绩综合评估及 ...
- 项目Beta冲刺(团队6/7)
项目Beta冲刺(团队) --6/7 作业要求: 项目Beta冲刺(团队) 1.团队信息 团队名 :男上加男 成员信息 : 队员学号 队员姓名 个人博客地址 备注 221600427 Alicesft ...
- es6 -- rest 参数
es6 引入了rest参数(形式:...变量名),用于获取函数的多余参数,这样就不需要使用arguments对象了.rest参数搭配的变量是一个数组,该变量将多余的参数放入数组中. function ...
- Tomcat不能访问ln -s软连接文件夹的前因后果
为了部署方便,把webapps下的大文件(图片等资源)放到工程外,通过软连接的方式设置 命令最常用的参数是-s,具体用法是:ln -s 源文件 目标文件. ln -s /usr/local/pic/i ...
- 【测试题】sequence
题目 给定一个长度为n(n<=5000)的由['0'..'9']组成的字符串s,v[i,j]表示由字符串s第i到第j位组成的十进制数字. 将它的某一个上升序列定义为:将这个字符串切割成m段不含前 ...
- MySQL binlog2sql实现MySQL误操作的恢复
对于MySQL数据库中的误操作删除数据的恢复问题,可以使用基于MySQL中binlog做到类似于闪回或者生成反向操作的SQL语句来实现,是MySQL中一个非常实用的功能.原理不难理解,基于MySQL的 ...
- linux学习16 Linux用户和组管理命令演练和实战应用
一.上集回顾 1.bash globing,IO重定向及管道 glob:*,?,[],[^] IO重定向: >,>>, 2>,2>> &>,& ...
- Hibernate的批量查询——原生sql查询
1.查询所有的学生信息: (1)查询结果中,一条信息放入到一个数组中,从list集合中取出数组,并对数组进行遍历. public class GeneratorTest { public static ...
- rust crates 国内镜像加速配置
rust 很不错,但是crates 经常下载有点慢,当前阿里云还没有相关的镜像,还有科大为我们提供了一个 配置方法 添加crates 配置 $HOME/.cargo/config 目录 [regist ...