拆解LangChain的大模型记忆方案
之前我们聊过如何使用LangChain给LLM(大模型)装上记忆,里面提到对话链ConversationChain和MessagesPlaceholder,可以简化安装记忆的流程。下文来拆解基于LangChain的大模型记忆方案。
1. 安装记忆的原理
1.1. 核心步骤
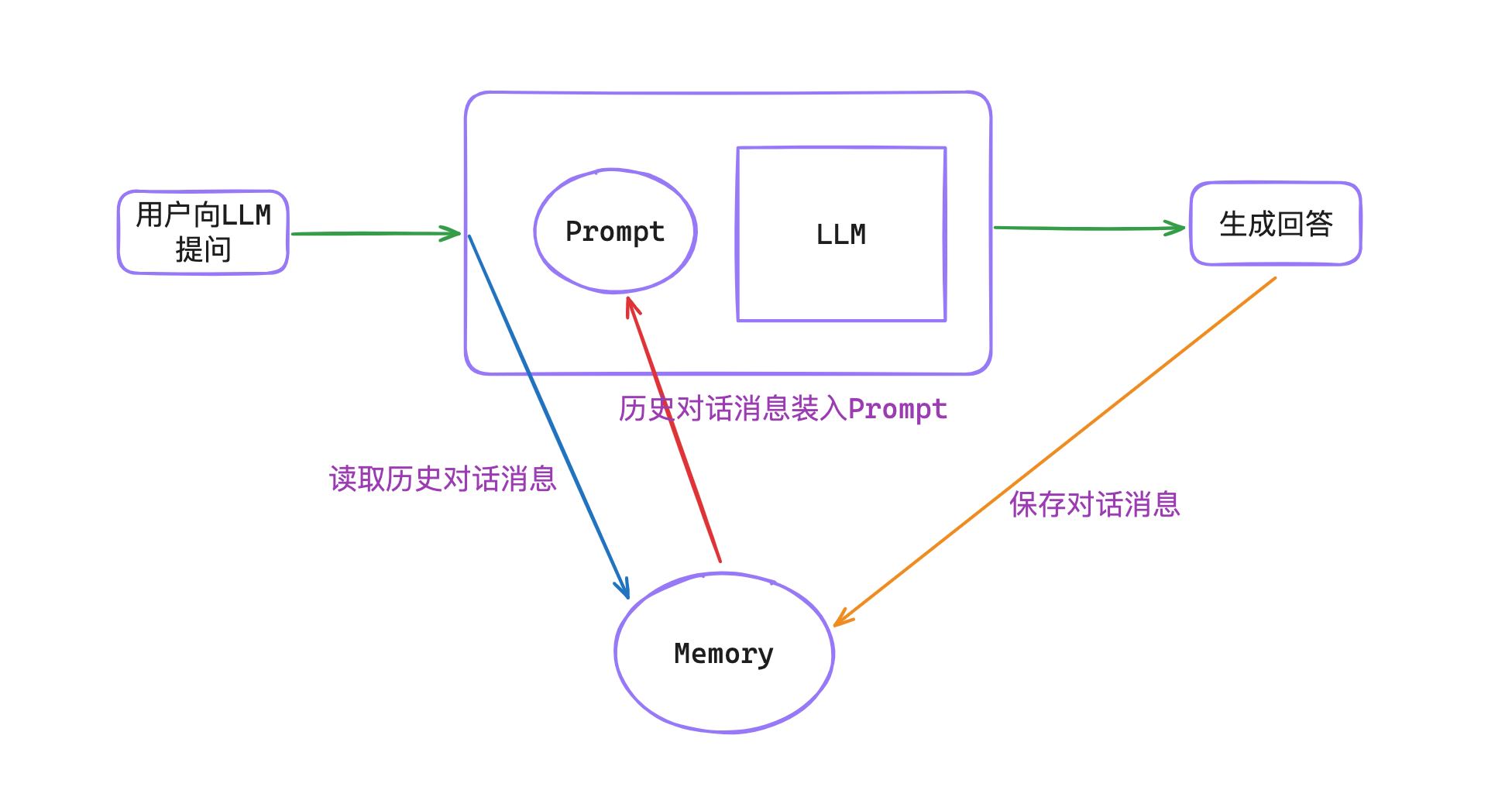
给LLM安装记忆的核心步骤就3个:
- 在对话之前调取之前的历史消息。
- 将历史消息填充到Prompt里。
- 对话结束后,继续将历史消息保存到到memory记忆中。
1.2. 常规使用方法的弊端
了解这3个核心步骤后,在开发过程中,就需要手动写代码实现这3步,这也比较麻烦,不仅代码冗余,而且容易遗漏这些模板代码。
为了让开发者聚焦于业务实现,LangChain贴心地封装了这一整套实现。使用方式如下。
2. 记忆的种类
记忆分为 短时记忆 和 长时记忆。
在LangChain中使用ConversationBufferMemory作为短时记忆的组件,实际上就是以键值对的方式将消息存在内存中。
如果碰到较长的对话,一般使用ConversationSummaryMemory对上下文进行总结,再交给大模型。或者使用ConversationTokenBufferMemory基于固定的token数量进行内存刷新。
如果想对记忆进行长时间的存储,则可以使用向量数据库进行存储(比如FAISS、Chroma等),或者存储到Redis、Elasticsearch中。
下面以ConversationBufferMemory为例,对如何快速安装记忆做个实践。
3. 给LLM安装记忆 — 非MessagesPlaceholder
3.1. ConversationBufferMemory使用示例
使用ConversationBufferMemory进行记住上下文:
memory = ConversationBufferMemory()
memory.save_context(
{"input": "你好,我的名字是半支烟,我是一个程序员"}, {"output": "你好,半支烟"}
)
memory.load_memory_variables({})
3.2. LLMChain+ConversationBufferMemory使用示例
# prompt模板
template = """
你是一个对话机器人,以下<history>标签中是AI与人类的历史对话记录,请你参考历史上下文,回答用户输入的问题。
历史对话:
<history>
{customize_chat_history}
</history>
人类:{human_input}
机器人:
"""
prompt = PromptTemplate(
template=template,
input_variables=["customize_chat_history", "human_input"],
)
memory = ConversationBufferMemory(
memory_key="customize_chat_history",
)
model = ChatOpenAI(
model="gpt-3.5-turbo",
)
chain = LLMChain(
llm=model,
memory=memory,
prompt=prompt,
verbose=True,
)
chain.predict(human_input="你知道我的名字吗?")
# chain.predict(human_input="我叫半支烟,我是一名程序员")
# chain.predict(human_input="你知道我的名字吗?")
此时,已经给LLM安装上记忆了,免去了我们写那3步核心的模板代码。
对于PromptTemplate使用以上方式,但ChatPromptTemplate因为有多角色,所以需要使用MessagesPlaceholder。具体使用方式如下。
4. 给LLM安装记忆 — MessagesPlaceholder
MessagesPlaceholder主要就是用于ChatPromptTemplate场景。ChatPromptTemplate模式下,需要有固定的格式。
4.1. PromptTemplate和ChatPromptTemplate区别
ChatPromptTemplate主要用于聊天场景。ChatPromptTemplate有多角色,第一个是System角色,后续的是Human与AI角色。因为需要有记忆,所以之前的历史消息要放在最新问题的上方。
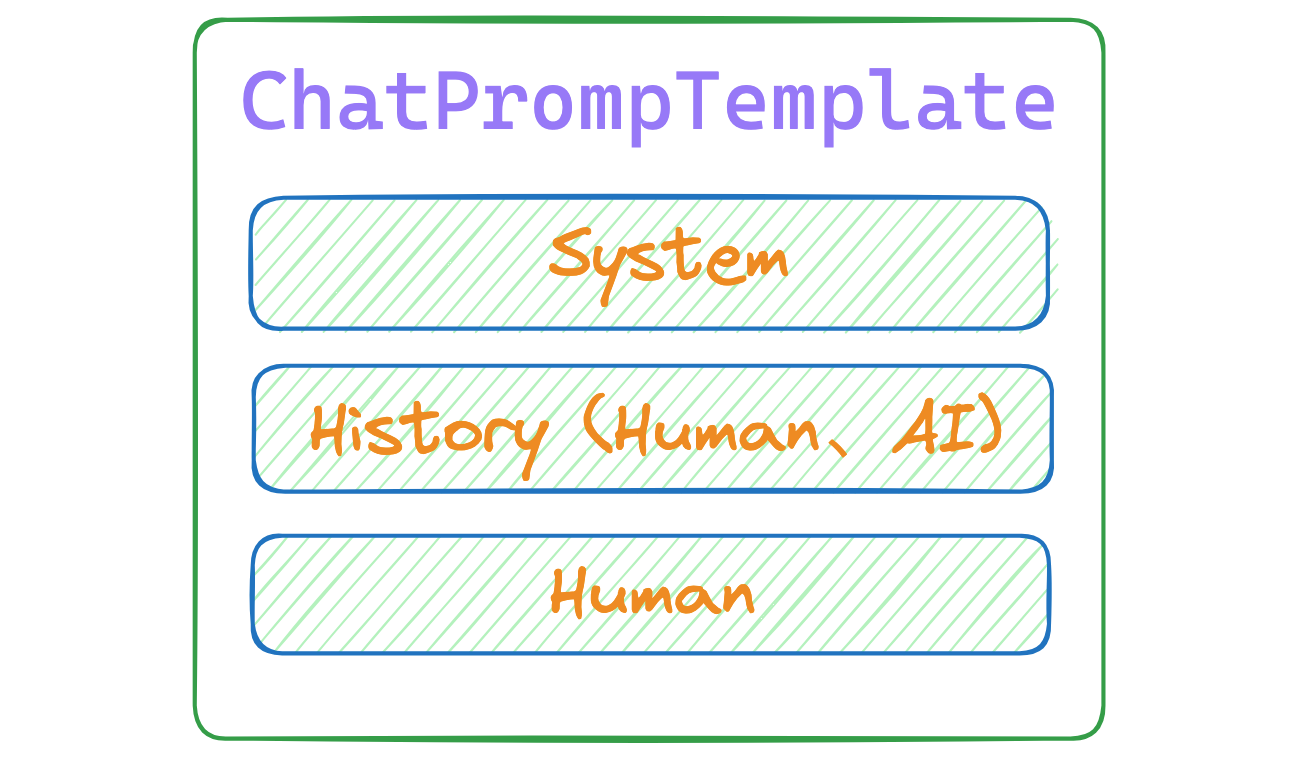
4.2. 使用MessagesPlaceholder安装
最终的ChatPromptTemplate + MessagesPlaceholder代码如下:
chat_prompt = ChatPromptTemplate.from_messages(
[
("system", "你是一个乐于助人的助手。"),
MessagesPlaceholder(variable_name="customize_chat_history"),
("human", "{human_input}"),
]
)
memory = ConversationBufferMemory(
memory_key="customize_chat_history",
return_messages=True,
)
model = ChatOpenAI(
model="gpt-3.5-turbo",
)
chain = LLMChain(
llm=model,
memory=memory,
prompt=chat_prompt,
verbose=True,
)
chain.predict(human_input="你好,我叫半支烟,我是一名程序员。")
至此,我们使用了ChatPromptTemplate简化了构建prompt的过程。
5. 使用对话链ConversationChain
如果连ChatPromptTemplate都懒得写了,那直接使用对话链ConversationChain,让一切变得更简单。实践代码如下:
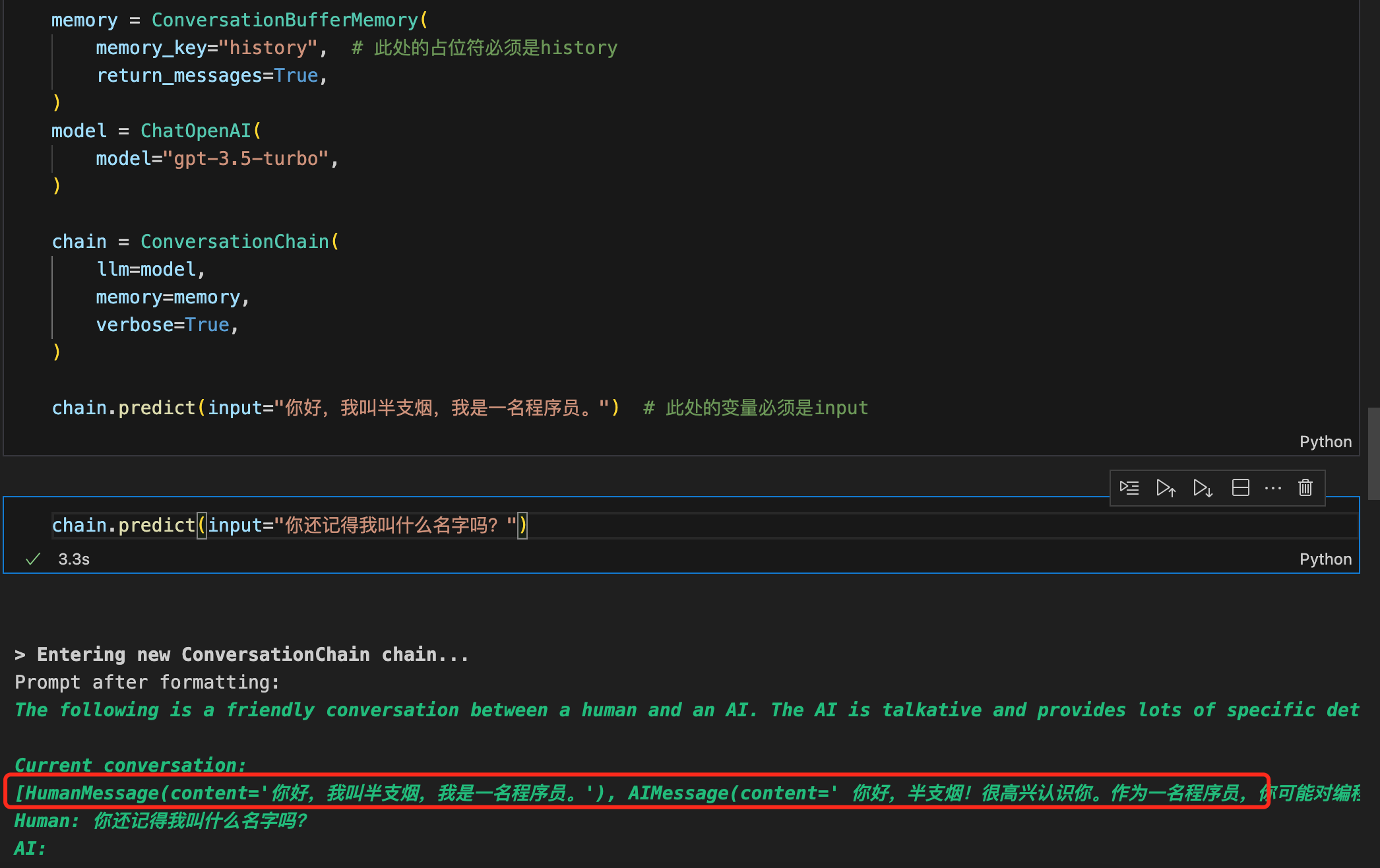
memory = ConversationBufferMemory(
memory_key="history", # 此处的占位符必须是history
return_messages=True,
)
model = ChatOpenAI(
model="gpt-3.5-turbo",
)
chain = ConversationChain(
llm=model,
memory=memory,
verbose=True,
)
chain.predict(input="你好,我叫半支烟,我是一名程序员。") # 此处的变量必须是input
ConversationChain提供了包含AI角色和人类角色的对话摘要格式。ConversationChain实际上是对Memory和LLMChain和ChatPrompt进行了封装,简化了初始化Memory和构建ChatPromptTemplate的步骤。
6. ConversationBufferMemory
6.1. memory_key
ConversationBufferMemory有一个入参是memory_key,表示内存中存储的本轮对话的键,后续可以根据键找到对应的值。
6.2. 使用"chat_history"还是"history"
ConversationBufferMemory的memory_key,有些资料里是设置是memory_key="history",有些资料里是"chat_history"。
这里有2个规则,如下:
- 在使用
MessagesPlaceholder和ConversationBufferMemory时,MessagesPlaceholder的variable_name和ConversationBufferMemory的memory_key可以自定义,只要相同就可以。比如这样:
chat_prompt = ChatPromptTemplate.from_messages(
[
("system", "你是一个乐于助人的助手。"),
MessagesPlaceholder(variable_name="customize_chat_history"),
("human", "{input}"),
]
)
memory = ConversationBufferMemory(
memory_key="customize_chat_history", # 此处的占位符可以是自定义
return_messages=True,
)
model = ChatOpenAI(
model="gpt-3.5-turbo",
)
chain = ConversationChain(
llm=model,
memory=memory,
prompt=chat_prompt,
verbose=True,
)
chain.predict(input="你好,我叫半支烟,我是一名程序员。") # 此处的变量必须是input
- 如果只是使用
ConversationChain,又没有使用MessagesPlaceholder的场景下,ConversationBufferMemory的memory_key,必须用history。
7. MessagesPlaceholder的使用场景
MessagesPlaceholder其实就是在与AI对话过程中的Prompt的一部分,它代表Prompt中的历史消息这部分。它提供了一种结构化和可配置的方式来处理这些消息列表,使得在构建复杂Prompt时更加灵活和高效。
说白了它就是个占位符,相当于把从memory读取的历史消息插入到这个占位符里了。
比如这样,就可以表示之前的历史对话消息:
chat_prompt = ChatPromptTemplate.from_messages(
[
("system", "你是一个乐于助人的助手。"),
MessagesPlaceholder(variable_name="customize_chat_history"),
("human", "{human_input}"),
]
)
是否需要使用MessagesPlaceholder,记住2个原则:
PromptTemplate类型的模板,无需使用MessagesPlaceholderChatPromptTemplate类型的聊天模板,需要使用MessagesPlaceholder。但是在使用ConversationChain时,可以省去创建ChatPromptTemplate的过程(也可以不省去)。省去和不省去在输出过程中有些区别,如下: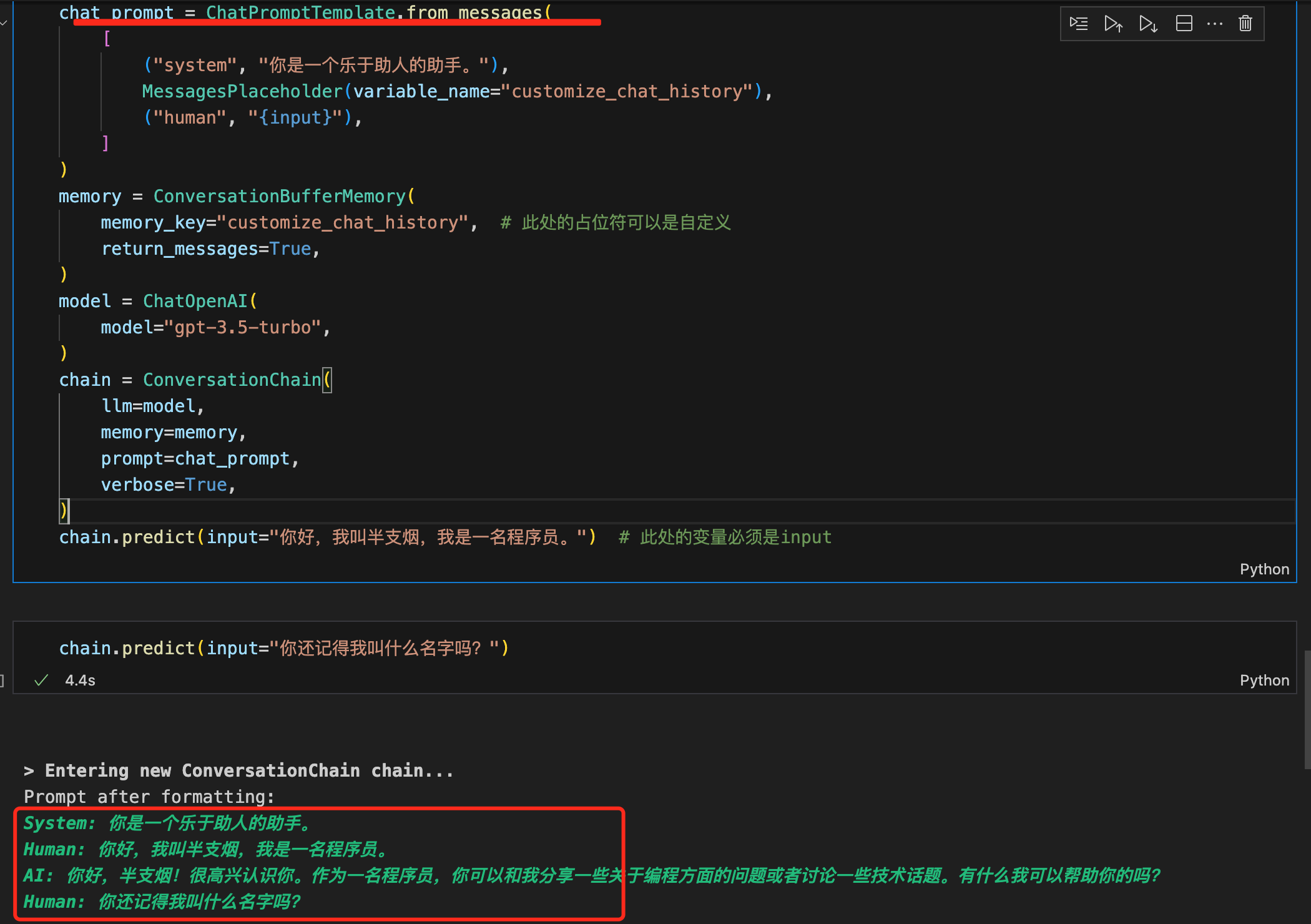
8. 总结
本文主要聊了安装记忆的基本原理、快速给LLM安装记忆、ConversationBufferMemory、MessagesPlaceholder的使用、对话链ConversationChain的使用和原理。希望对你有帮助!
=====>>>>>> 关于我 <<<<<<=====
本篇完结!欢迎点赞 关注 收藏!!!
原文链接:https://mp.weixin.qq.com/s/cRavfyu--AjBOO3-1aY0UA

拆解LangChain的大模型记忆方案的更多相关文章
- Sqlserver 高并发和大数据存储方案
Sqlserver 高并发和大数据存储方案 随着用户的日益递增,日活和峰值的暴涨,数据库处理性能面临着巨大的挑战.下面分享下对实际10万+峰值的平台的数据库优化方案.与大家一起讨论,互相学习提高! ...
- NYOJ16|嵌套矩形|DP|DAG模型|记忆化搜索
矩形嵌套 时间限制:3000 ms | 内存限制:65535 KB 难度:4 描述 有n个矩形,每个矩形可以用a,b来描述,表示长和宽.矩形X(a,b)可以嵌套在矩形Y(c,d)中当且仅当a& ...
- 千亿参数开源大模型 BLOOM 背后的技术
假设你现在有了数据,也搞到了预算,一切就绪,准备开始训练一个大模型,一显身手了,"一朝看尽长安花"似乎近在眼前 -- 且慢!训练可不仅仅像这两个字的发音那么简单,看看 BLOOM ...
- 无插件的大模型浏览器Autodesk Viewer开发培训-武汉-2014年8月28日 9:00 – 12:00
武汉附近的同学们有福了,这是全球第一次关于Autodesk viewer的教室培训. :) 你可能已经在各种场合听过或看过Autodesk最新推出的大模型浏览器,这是无需插件的浏览器模型,支持几十种数 ...
- tomcat中间件提交表单数据量过大警告处理方案
http://www.bubuko.com/infodetail-976418.html http://www.cnblogs.com/yg_zhang/p/4248061.html tomcat中间 ...
- 优秀后端架构师必会知识:史上最全MySQL大表优化方案总结
本文原作者“ manong”,原创发表于segmentfault,原文链接:segmentfault.com/a/1190000006158186 1.引言 MySQL作为开源技术的代表作之一,是 ...
- MySQL 大表优化方案(长文)
当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化: 单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑.部署.运维的各种复杂度,一般以整型 ...
- PowerDesigner 学习:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- PowerDesigner 15学习笔记:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- 比赛:大奔的方案solution
分析: 此题是小奔的方案的改进.小奔的方案思路:倒推,每次都从小到大排序并且保证小号在前,然后使每一个人分到的金币都是上一次加一,直到金币分完或者自己可以存活(投票率大于等于所需概率),如果不行就-1 ...
随机推荐
- gRPC入门学习之旅(八)
gRPC入门学习之旅(一) gRPC入门学习之旅(二) gRPC入门学习之旅(三) gRPC入门学习之旅(四) gRPC入门学习之旅(五) gRPC入门学习之旅(六) gRPC入门学习之旅(七) 3. ...
- 好玩的vue组件
https://gitee.com/zheng_yongtao/jyeontu-component-warehouse 推荐这个大佬,很厉害悬浮按钮 评论组件 词云 瀑布流照片容器 视频动态封面 3D ...
- Machine Learning - 梯度下降
一.梯度下降:目的是为了寻找到最合适的 $w$ 和 $b$ ,让成本函数的值最小 \[w = w - α\frac{\partial J(w,b)}{\partial w} \] \[b = b - ...
- 使用interface化解一场因操作系统不同导致的编译问题
场景描述 起因: 因项目需求,需要编写一个agent, 需支持Linux和Windows操作系统. Agent里面有一个功能需要获取到服务器上所有已经被占用的端口. 实现方式:针对不同的操作系统,实现 ...
- 从零开始写 Docker(十五)---实现 mydocker run -e 支持环境变量传递
本文为从零开始写 Docker 系列第十五篇,实现 mydocker run -e, 支持在启动容器时指定环境变量,让容器内运行的程序可以使用外部传递的环境变量. 完整代码见:https://gith ...
- Spring6 对 集成MyBatis 开发运用(附有详细的操作步骤)
1. Spring6 对 集成MyBatis 开发运用(附有详细的操作步骤) @ 目录 1. Spring6 对 集成MyBatis 开发运用(附有详细的操作步骤) 每博一文案 2. 大概的实现步骤概 ...
- Android 13 - Media框架(28)- MediaCodec(三)
关注公众号免费阅读全文,进入音视频开发技术分享群! 上一节我们了解到 ACodec 执行完 start 流程后,会把所有的 input buffer 都提交给 MediaCodec 层,MediaCo ...
- 全网最全100个AI工具导航网站合集
随着ChatGPT年前的爆火,人工智能也变成当今最热门的领域之一,它正在改变着我们的生活和工作方式.无论你是想要学习人工智能的基础知识,还是想要利用人工智能来提升你的业务效率和创新能力,都需要找到合适 ...
- LLM 大模型学习必知必会系列(八):10分钟微调专属于自己的大模型
LLM 大模型学习必知必会系列(八):10分钟微调专属于自己的大模型 1.环境安装 # 设置pip全局镜像 (加速下载) pip config set global.index-url https:/ ...
- itest work 开源接口测试&敏捷测试管理平台 9.5.0 GA_u1,优化及修复关键 BUG
(一)itest work 简介 itest work (爱测试) 一站式工作站让测试变得简单.敏捷,"好用.好看,好敏捷" ,是itest wrok 追求的目标.itest w ...