Elasticsearch 如何保证写入过程中不丢失数据的
丢失数据的本质
在本文开始前,首先明白一个点,平时我们说的组件数据不丢失究竟是在指什么,如果你往ES写入数据,ES返回给你写入错误,这个不算数据丢失。如果你往ES写入数据,ES返回给你成功,但是后续因为ES节点重启或宕机导致写入的数据不见了,这个才叫数据丢失。
简而言之,丢失数据的本质是ES本身搞丢了返回结果是成功写入的数据。
数据写入流程
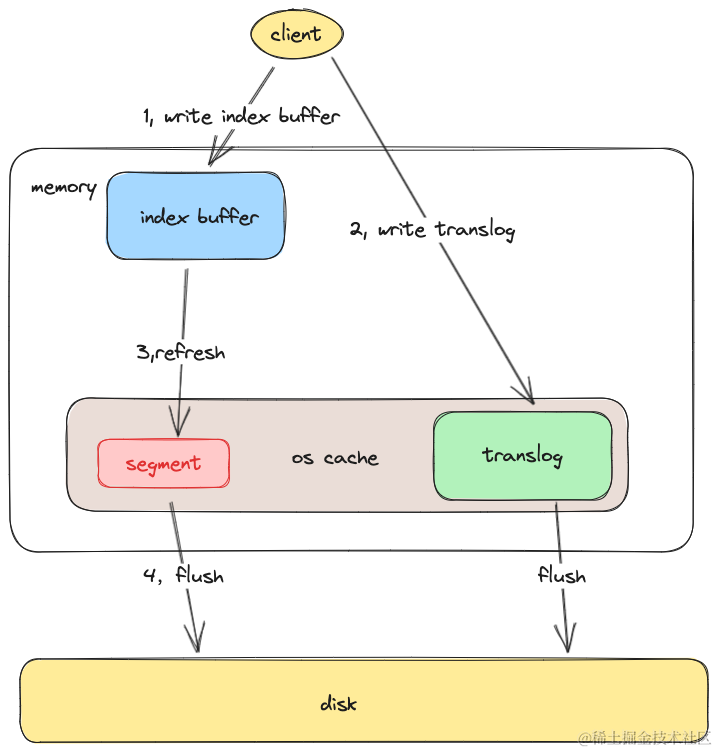
1,写入时,ES会首先往一块内存缓存中写入数据,这快内存缓存在ES中叫index buffer,此时数据是不可见的,只有经过refresh操作后,数据才能变得可见。
index buffer的大小设置可以通过 下面的请求去进行设置,如下,设置了index buffer的大小为总内存的30%
PUT /_cluster/settings
{
"persistent" : {
"indices.memory.index_buffer_size" : "30%"
}
}
2, 在写入index buffer成功后,会写translog 记录写入的数据。此时数据依然不可见。由于操作系统对文件写入,并不会立即落盘。所以ES提供了关于刷盘的配置,index.translog.durability两个选项值,如下,
request会在每次创建segment写入数据后就对translog进行刷盘操作。async则会定时对translog进行刷盘操作。定时刷新到磁盘的周期是通过index.translog.sync_interval参数去进行控制,默认是5s。
3,refresh 操作可以主动触发也可以定时触发,默认是1s会进行一次, 该操作会创建一个lucece的segment段用于存储新写入到index buffer中的数据,注意这里即使写入到了segment里,数据还是在os Cache系统文件系统缓存中,并没有落入磁盘,只有 在lucece将数据 commit 到磁盘后,数据才能落盘。
4, 在文件系统缓存中的segment总归还是要写入磁盘,默认每30分钟,或者当translog的日志量达到某个量级时,segment会进行落盘,同时删掉translog日志。这个量级由index.translog.flush_threshold_size 去进行控制,默认是512mb。
在了解了ES的写入数据的过程后,我们可以发现,如果将index.translog.durability 设置为request ,这样便能让每次请求返回客户端成功时,保证一定会有translog日志存储到磁盘上,后续如果在系统缓存中的segment因为系统宕机而没有落盘依然能够通过translog去进行恢复。
而如果index.translog.durability 设置为 async 则有可能会丢失5s的数据。
Elasticsearch 如何保证写入过程中不丢失数据的的更多相关文章
- Java中在时间戳计算的过程中遇到的数据溢出问题
背景 今天在跑定时任务的过程中,发现有一个任务在设置数据的查询时间范围异常,出现了开始时间戳比结束时间戳大的奇怪现象,计算时间戳的代码大致如下. package com.lingyejun.authe ...
- Bug,项目过程中的重要数据
作者|孙敏 为什么要做Bug分析? Bug是项目过程中的一个有价值的虫子,它不只是给开发的,而是开给整个项目组的. 通过Bug我们能获得什么? 积累测试方法,增强QA的测试能力,提升产品质量 发现项目 ...
- 安装Bind过程中提示丢失MSVCR110.dll的解决办法
前几天在线安装Visual Studio 2012 Update 3,由于在线安装需要不断下载安装文件,时间很长,后来等不下去,就取消了,不幸的是VS启动不了了,弹出“devenv.exe – 系统错 ...
- Java基础之写文件——在通道写入过程中的缓冲区状态(BufferStateTrace)
控制台程序,在Junk目录中将字符串“Garbage in, garbage out\n”写入到名为charData.txt的文件中. import static java.nio.file.Stan ...
- Elasticsearch如何保证数据不丢失?
目录 如何保证数据写入过程中不丢 直接落盘的 translog 为什么不怕降低写入吞吐量? 如何保证已写数据在集群中不丢 in-memory buffer 总结 LSM Tree的详细介绍 参考资料 ...
- LTE 切换过程中的数据切换
http://blog.sina.com.cn/s/blog_673b30dd0100j4p4.html LTE中的切换,根据无线承载(Radio Bearer)的QoS要求的不同,可以分为无缝切换( ...
- elasticsearch与kibana安装过程(linux)
elasticsearch与kibana安装 下载 Elasticsearch 官网:https://www.elastic.co/,elastic search应用本质就是一个jvm进程,所以需要J ...
- 在Web界面中实现Excel数据大量导入的处理方式
在早期Bootstrap框架介绍中,我的随笔<结合bootstrap fileinput插件和Bootstrap-table表格插件,实现文件上传.预览.提交的导入Excel数据操作流程> ...
- ES 18 - (底层原理) Elasticsearch写入索引数据的过程 以及优化写入过程
目录 1 Lucene操作document的流程 1.1 添加document的流程 1.2 删除document的流程 2 优化写入流程 - 实现近实时搜索 2.1 流程的改进思路 2.2 设置re ...
- kafka如何保证不重复消费又不丢失数据_Kafka写入的数据如何保证不丢失?
我们暂且不考虑写磁盘的具体过程,先大致看看下面的图,这代表了 Kafka 的核心架构原理. Kafka 分布式存储架构 那么现在问题来了,如果每天产生几十 TB 的数据,难道都写一台机器的磁盘上吗?这 ...
随机推荐
- 人工智能大语言模型微调技术:SFT 监督微调、LoRA 微调方法、P-tuning v2 微调方法、Freeze 监督微调方法
人工智能大语言模型微调技术:SFT 监督微调.LoRA 微调方法.P-tuning v2 微调方法.Freeze 监督微调方法 1.SFT 监督微调 1.1 SFT 监督微调基本概念 SFT(Supe ...
- python:spacy、gensim库的安装遇到问题及bug处理
1.spacy SpaCy最新版V3.0.6版,在CMD 模式下可以通过 pip install spacy -U 进行安装 注意这个过程进行前可以先卸载之前的旧版本 pip uninstall sp ...
- Linux系统的一些实用操作 [补档-2023-07-30]
Linux的实用操作 4-1.常用快捷键 强制停止:当某些程序运行时,或者命令输入错误时,可以通过 ctrl + c 来强制结束当前的操作. 退出或登出:当我们要退出某些用户时,或者要退出某些特殊的页 ...
- SSM整合思维(随手记)
整合方向(整合思路): 用Spring去整合SpringMVC和Mybatis. 一.先创建Spring项目测试运行成功后,再创建SpringMVC项目再单独测试SpringMVC项目如果运行成功后即 ...
- Win10已死!微软发布Windows 11大更新:引入ChatGPT、升级巨大
今天凌晨微软在开发者大会上公布了Windows 11的新版本更新"Moment 3",整体升级幅度非常的大. 新系统的多任务有了改进,现在按下Alt+Tab时,可以显示更多的Edg ...
- shell 两个数组比较,得到元素的并集、交集等
linux shell 实现数组比较,取元素的并集.交集时,可以使用sort排序.uniq统计和awk数据过滤. shell 实现如下 file_list_1=("test1" & ...
- CF1861
只做出 A,身败名裂 A 显然不管怎么排,13,31 总有一个会出现,看看哪个出现. B 给定两个 01 串,每次可以挑一个串的一个子串,要求两端相同,然后把这个子串全部变得和两端相同. 问经过若干次 ...
- 精通C语言:打造高效便捷的通讯录管理系统
欢迎大家来到贝蒂大讲堂 养成好习惯,先赞后看哦~ 所属专栏:C语言项目 贝蒂的主页:Betty's blog 引言: 在我们大致学习完C语言之后,我们就可以利用目前所学的知识去做一些有意思的项目,而今 ...
- 2023年多校联训NOIP层测试5
2023年多校联训NOIP层测试5 T1 糖果 \(10pts\) 首先考虑一些异或的性质: 归零率:\(a \bigoplus a=0\) 恒等律:\(a \bigoplus 0=a\) 交换律:\ ...
- JS Leetcode 374. 猜数字大小 题解分析
壹 ❀ 引 本题来自LeetCode 374. 猜数字大小,题目难度简单,与昨天的题目一样,也是一道标准二分法的题目,不知道是不是端午节的缘故,这两天的题目都比较简单,题目描述如下: 猜数字游戏的规则 ...