Elasticsearch 如何保证写入过程中不丢失数据的
丢失数据的本质
在本文开始前,首先明白一个点,平时我们说的组件数据不丢失究竟是在指什么,如果你往ES写入数据,ES返回给你写入错误,这个不算数据丢失。如果你往ES写入数据,ES返回给你成功,但是后续因为ES节点重启或宕机导致写入的数据不见了,这个才叫数据丢失。
简而言之,丢失数据的本质是ES本身搞丢了返回结果是成功写入的数据。
数据写入流程
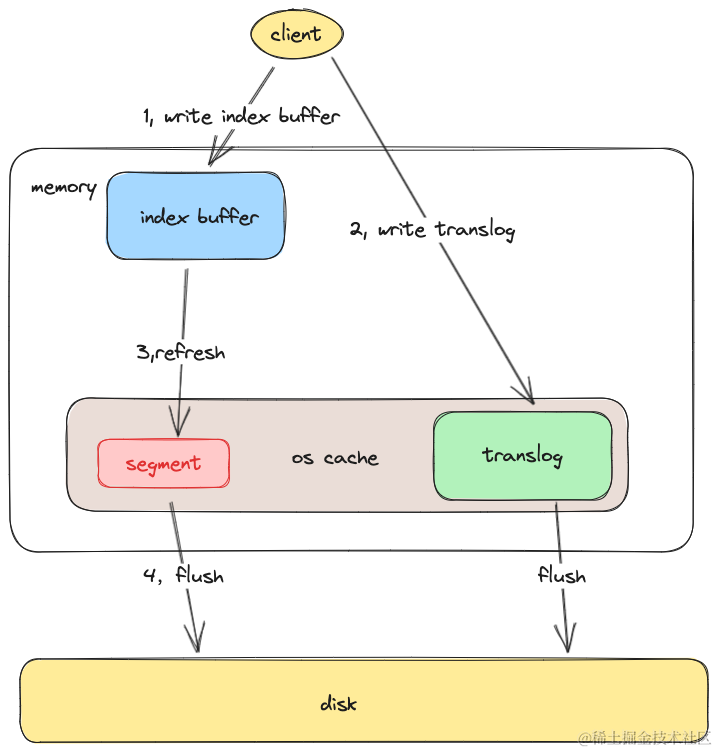
1,写入时,ES会首先往一块内存缓存中写入数据,这快内存缓存在ES中叫index buffer,此时数据是不可见的,只有经过refresh操作后,数据才能变得可见。
index buffer的大小设置可以通过 下面的请求去进行设置,如下,设置了index buffer的大小为总内存的30%
PUT /_cluster/settings
{
"persistent" : {
"indices.memory.index_buffer_size" : "30%"
}
}
2, 在写入index buffer成功后,会写translog 记录写入的数据。此时数据依然不可见。由于操作系统对文件写入,并不会立即落盘。所以ES提供了关于刷盘的配置,index.translog.durability两个选项值,如下,
request会在每次创建segment写入数据后就对translog进行刷盘操作。async则会定时对translog进行刷盘操作。定时刷新到磁盘的周期是通过index.translog.sync_interval参数去进行控制,默认是5s。
3,refresh 操作可以主动触发也可以定时触发,默认是1s会进行一次, 该操作会创建一个lucece的segment段用于存储新写入到index buffer中的数据,注意这里即使写入到了segment里,数据还是在os Cache系统文件系统缓存中,并没有落入磁盘,只有 在lucece将数据 commit 到磁盘后,数据才能落盘。
4, 在文件系统缓存中的segment总归还是要写入磁盘,默认每30分钟,或者当translog的日志量达到某个量级时,segment会进行落盘,同时删掉translog日志。这个量级由index.translog.flush_threshold_size 去进行控制,默认是512mb。
在了解了ES的写入数据的过程后,我们可以发现,如果将index.translog.durability 设置为request ,这样便能让每次请求返回客户端成功时,保证一定会有translog日志存储到磁盘上,后续如果在系统缓存中的segment因为系统宕机而没有落盘依然能够通过translog去进行恢复。
而如果index.translog.durability 设置为 async 则有可能会丢失5s的数据。
Elasticsearch 如何保证写入过程中不丢失数据的的更多相关文章
- Java中在时间戳计算的过程中遇到的数据溢出问题
背景 今天在跑定时任务的过程中,发现有一个任务在设置数据的查询时间范围异常,出现了开始时间戳比结束时间戳大的奇怪现象,计算时间戳的代码大致如下. package com.lingyejun.authe ...
- Bug,项目过程中的重要数据
作者|孙敏 为什么要做Bug分析? Bug是项目过程中的一个有价值的虫子,它不只是给开发的,而是开给整个项目组的. 通过Bug我们能获得什么? 积累测试方法,增强QA的测试能力,提升产品质量 发现项目 ...
- 安装Bind过程中提示丢失MSVCR110.dll的解决办法
前几天在线安装Visual Studio 2012 Update 3,由于在线安装需要不断下载安装文件,时间很长,后来等不下去,就取消了,不幸的是VS启动不了了,弹出“devenv.exe – 系统错 ...
- Java基础之写文件——在通道写入过程中的缓冲区状态(BufferStateTrace)
控制台程序,在Junk目录中将字符串“Garbage in, garbage out\n”写入到名为charData.txt的文件中. import static java.nio.file.Stan ...
- Elasticsearch如何保证数据不丢失?
目录 如何保证数据写入过程中不丢 直接落盘的 translog 为什么不怕降低写入吞吐量? 如何保证已写数据在集群中不丢 in-memory buffer 总结 LSM Tree的详细介绍 参考资料 ...
- LTE 切换过程中的数据切换
http://blog.sina.com.cn/s/blog_673b30dd0100j4p4.html LTE中的切换,根据无线承载(Radio Bearer)的QoS要求的不同,可以分为无缝切换( ...
- elasticsearch与kibana安装过程(linux)
elasticsearch与kibana安装 下载 Elasticsearch 官网:https://www.elastic.co/,elastic search应用本质就是一个jvm进程,所以需要J ...
- 在Web界面中实现Excel数据大量导入的处理方式
在早期Bootstrap框架介绍中,我的随笔<结合bootstrap fileinput插件和Bootstrap-table表格插件,实现文件上传.预览.提交的导入Excel数据操作流程> ...
- ES 18 - (底层原理) Elasticsearch写入索引数据的过程 以及优化写入过程
目录 1 Lucene操作document的流程 1.1 添加document的流程 1.2 删除document的流程 2 优化写入流程 - 实现近实时搜索 2.1 流程的改进思路 2.2 设置re ...
- kafka如何保证不重复消费又不丢失数据_Kafka写入的数据如何保证不丢失?
我们暂且不考虑写磁盘的具体过程,先大致看看下面的图,这代表了 Kafka 的核心架构原理. Kafka 分布式存储架构 那么现在问题来了,如果每天产生几十 TB 的数据,难道都写一台机器的磁盘上吗?这 ...
随机推荐
- 【深度学习项目三】ResNet50多分类任务【十二生肖分类】
相关文章: [深度学习项目一]全连接神经网络实现mnist数字识别 [深度学习项目二]卷积神经网络LeNet实现minst数字识别 [深度学习项目三]ResNet50多分类任务[十二生肖分类] 『深度 ...
- Flask Echarts 实现历史图形查询
Flask前后端数据动态交互涉及用户界面与服务器之间的灵活数据传递.用户界面使用ECharts图形库实时渲染数据.它提供了丰富多彩.交互性强的图表和地图,能够在网页上直观.生动地展示数据.EChart ...
- Python 基础知识点归纳
Python 是一种跨平台的计算机程序设计语言,是一种面向对象的动态类型语言,笔记内容包括编译安装python,python列表,字典,元组,文件操作等命令的基本使用技巧. 编译安装 Python P ...
- window下部署单机hadoop环境
window本地部署单机hadoop,修改配置文件和脚本如下,只记录关键配置和步骤,仅供参考 hadoop-2.6.5 spark-2.3.3 1.配置文件core-site.xml <conf ...
- 【scikit-learn基础】--『回归模型评估』之损失分析
分类模型评估中,通过各类损失(loss)函数的分析,可以衡量模型预测结果与真实值之间的差异.不同的损失函数可用于不同类型的分类问题,以便更好地评估模型的性能. 本篇将介绍分类模型评估中常用的几种损失计 ...
- 如何在 macOS Sonoma 虚拟机中安装 VMware Tools
vmware-tools VMware Tools 简介 VMware Tools 中包含一系列服务和模块,可在 VMware 产品中实现多种功能,从而使用户能够更好地管理客户机操作系统,以及与客户机 ...
- yapi tag的问题,暂时只保留一个tag
yapi 的tag是需要先在网页上建立好,如:
- Linux 将命令的输出保存到文件
当你在 Linux 终端中运行命令或脚本时,它会在终端中打印输出方便你立即查看.方法 1:使用重定向将命令输出保存到文件中你可以在 Linux 中使用重定向来达成目的.使用重定向操作符,它会将输出保存 ...
- 浅谈 2-SAT
SAT 是适定性(Satisfiability)问题的简称.一般形式为 k - 适定性问题,简称 k-SAT.而当 \(k>2\) 时该问题为 NP 完全的.所以我们只研究 \(k=2\) 的情 ...
- Shell 特殊符号(变量)用法小结
Shell | 特殊变量 $n 基本语法: $n (功能描述:n 为数字,$0 代表该脚本名称,$1-$9 代表第一到第九个参数,十以上的参数,十以上的参数需要用大括号包含,如${10}) 例如: ...