SQL Server – Transaction & Isolation 事务与隔离
前言
上回在谈到 Concurrency 并发控制 时, 有提到过事务的概念. 这篇就补上它具体的实现.
以前写过相关的文章:
sql server 学习笔记 (nested transaction 嵌套事务)
Asp.net core 学习笔记 ( ef core transaction scope & change level )
Begin Trans, Commit, Rollback
begin tran; -- 开启事务
commit; -- 提交事务
rollback; -- 回滚事务
最基本的 3 个操作方式
实战版
begin tran; -- 开启事务 begin try
insert into Product ([Name], Price) values ('mk100', 500); -- 插入数据
if(RAND() > 0.5) -- 随机 commit or throw error 模拟报错
commit; -- 提交事务
else
throw 50000, 'custom error',1; --报错
end try
begin catch
rollback; -- 捕获错误并且回滚
end catch
事务通常会搭配 try catch 一起用.
Isolation Level 隔离级别
事务通常会搭配 Isolation Level 来管理. Level 越高锁的范围就越大. 锁是双刃剑.
锁越多就越安全, 但性能也越差. 所以我们需要按需求来设定锁的范围, 这样才能达到平衡.
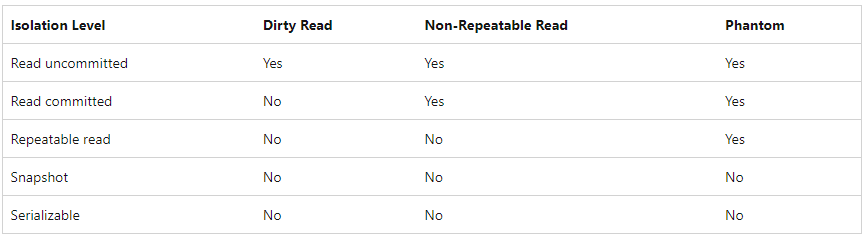
一共有 6 个 level. snapshot 其实有分 2 种, 但我不太熟, 这里就跳过它. 它的特点是利用了一些缓存 tempdb, 减少了锁. 算是, 有好有坏吧, 有兴趣的可以参考这篇和这篇
Read Uncommitted < Read Committed < Repeatable Read < Serializable
Serializable 等级最高, 锁也最多.
Dirty Read and Read Committed Level 脏读
你想读一个数据, 但这个数据却被另一个事务修改了, 而那个事务还没有完成提交. 这时数据是不稳定的. 因为事务最后可能被回滚.
这个就叫脏读, 数据正在被修改, 它是脏的.
如果我们不允许这种事情发生, 那么可以 set Isolation Level 为 Read Committed 或者更高 Level.
设定后, 遇到读脏数据它就会先等待. 等到对方事务提交后才会读取可靠的值.
注: SQL 默认的 Level 就是 Read Committed. 所以通常我们不需要设置这个的, 反之如果我们不希望等待则可以设定 Level 为 Read Uncommitted, 顾名思义它就是 uncommitted (未提交) 也照读出来用.
我方角度: 等别人写完, 我才读
Non-repeatable Read and Repeatable Read Level 重复读
你读了一个数据, 并拿这个数据做逻辑判断来完成后续的操作. 在你还没有完成这个事务的时候, 另一个事务修改了这个数据.
这时你的逻辑判断是 "旧" 的. 如果你提交事务, 可能业务逻辑就错了.
这就叫重复读. 如果我们想避开这个问题就需要升级 Isolation Level 到 Repeatable Read.
当我们读出数据以后, 这个数据就被锁上了. 其它事务无法写入. 它们会一直等到我们提交事务.
我方角度: 读了不许别人写
Phantom and Serializable Level 幻读
Repeatable Read 的锁是有漏洞的. 它防 update 但不防 insert.
举例
select * from table where id = 1;
这时 id 1 这条 row 被锁了, 无法 update. 成功实现了 repeatable read.
select * from table where name like '%abc%';
这时但凡 name 里有 'abc' 字符的 row 都被锁了. 无法 update. 但是依然可以 insert
insert into table (name) values ('x abc y'); 这句是可以跑的.
如果我依赖 row count 来做逻辑判断, 那么就不安全了. 这就叫幻读.
解决方法就是再提升 Level 到 Serializable.
切记, Isolation Level 越高 > 锁越多 > 等待越多 > 死锁机率越高
Serializable 几乎是锁整个表了 (题外话: 它可以通过 index 做到一些优化哦, 不是每次都需要锁整张表)
Set Isolation Level
set transaction isolation level read uncommitted;
set transaction isolation level read committed;
set transaction isolation level repeatable read;
set transaction isolation level serializable;
Changing Isolation Level 后, 之前的锁, 怎办?
参考: Docs – SET TRANSACTION ISOLATION LEVEL Remark
Isolation 是可以来来回回切换的.
当 Level 改变后, 往后的 query 都会依据这个 Level 的限制度去加锁. 而那些在改变 Level 以前就已经加好的锁则会一直保留着.
当 Isolation 遇上 Trigger 和 Stored Procedures
参考: Docs – SET TRANSACTION ISOLATION LEVEL Remark
在 Trigger 和 SP 中修改 Isolation Level, 它只会在作用域内有效. 当执行完退出 Trigger 或 SP 后. Isolation Level 会自动被设置回之前 (before Trigger/SP) 的 Level.
Transaction + Isolation
Repeatable Read
begin tran; set transaction isolation level repeatable read; -- 设置 Isolation Level declare @value nvarchar(50);
select @value = [Value] from Table where Id = 1; -- 这时 row id 1 被锁了. 其它人不允许修改
insert into Table2 ([value]) values (@value); -- 依赖刚 select 的 value 做一些事儿 commit; -- 提交
Serializable
begin tran; set transaction isolation level serializable; -- 设置 Isolation Level declare @count nvarchar(50); -- 所有 row value contains 'abc' 都被锁, 同时表也不允许插入, 也无法修改其它 row value 到 contains 'abc'
-- 总之就是确保 count 是绝对稳定的.
select @count = count(*) from Table where value like '%abc%'; insert into Table2 ([count]) values (@count); -- 依赖 count 做一些事儿 commit; -- 提交
Serializable 会大范围的锁表或 row, 以确保 count 是稳定的
事务嵌套 (nested transaction)
上面我们说, 一个事务由多个操作语句组合而成. 要嘛全部成功, 要嘛全部失败.
这个适用于简单的场景. 但当业务需求变得复杂以后, 我们需要更灵活的管理能力.
比如, 事务嵌套
一个事务可以由多个事务组成. 封装事务可以通过 Stored Proceduces.
同时, 我们要有能力选择性 rollback 单个小事务, 而不是每一次都强制 rollback 所有事务.
遗憾的是, SQL Server 并不直接支持事务嵌套 (Oracle 是支持的). 但是它有一些规则可以共我们使用, 从而达模拟出类似嵌套事务的效果.
trans, commit, rollbak, @@TRANCOUNT 和 save transaction 的玩法
参考: SQL Server嵌套事务探讨
begin tran 和 @@TRANCOUNT
每一次 begin trans 后 @@TRANCOUNT 会累加 1
begin tran;
select @@TRANCOUNT; -- 1
begin tran;
select @@TRANCOUNT; -- 2
commit 和 @@TRANCOUNT
每一次 commit 后 @@TRANCOUNT 会递减 1, 同时如果递减前 @@TRANCOUNT 是 1 那么还会持久化所有的数据.
在简单场景中过程是这样的.
1. begin tran 一开始 count++ 变成 1
2. do something...
3. commit, 这时 count = 1 于是持久化数据, 然后 count-- 回到 0
rollback 和 @@TRANCOUNT
rollback 会立刻回滚所有数据 (从 begin tran 之后的所有的数据操作都会被还原). 同时 @@TRANCOUNT 被设定成 0 (无论它当前是多少)
在简单场景中过程是这样的.
1. begin tran 一开始 count++ 变成 1
2. do something...
3. rollback, 还原数据, 然后 count = 0
save transaction (Save Point) and rollback transaction
在 begin tran 后, 任何一个时刻我们都可以做一个 save point (记入点)
save transaction save_point_name;
它是搭配 rollback transaction 一起用的.
rollback; 表示完全回滚到 begin tran
rollback transaction save_point_name 表示只回滚到 save point 那一刻 (而不是全部)
rollback transaction 和 @@TRANCOUNT
上面提到 rollback 会把 @@TRANCOUNT 变成 0.
但 rollback transaction 则不会, 它完全不会修改 @@TRANCOUNT (不会 set to 0, 也不会递减, 完全不动就是了)
模拟事务嵌套
参考:
Docs – SAVE TRANSACTION (Transact-SQL)
Stack Overflow – SAVE TRANSACTION vs BEGIN TRANSACTION (SQL Server) how to nest transactions nicely
假设我们用 Stored Procedures 来封装小事务.
那在 Stored Procedures 里面会是这样控制的.
1. 先查看当前是否有正在运行的 transaction. 通过 @@TRANCOUNT <> 0 来判断.
2. 如果没有, 那 SP 负责 begin tran. 如果已经有了那 SP 只做一个 save point 就好.
3. 接着就是各种数据操作
4. 当数据操作全部都成功后, 如果是 SP 负责 begin tran 那这时需要 commit, 如果 SP 只是负责 save point, 那不需要做任何 commit 把职责留给外面.
5. 当遇到 error 的时候, 如果是 SP 负责 begin tran 那么就直接 rollback, 如果 SP 只是负责 save point 那就 rollback transaction save point 就好了. 最后 throw error 到外面
Why it work? 我们看看它是如何实现模拟事务嵌套的.
1. SP 判断是否已存在 transaction. 这一步就确保了全场只有一个 begin tran. @@TRANCOUNT 绝对不会超过 1
2. 当 SP 要 commit 的时候交由外部去 commit. 因为如果外部已有 transaction 那么肯定外面 (最上层) 至少会有一个 commit. (如果内部 commit @@TRANCOUNT 就会 -1 变成 0 那就会立刻持久化, 这不是想要的)
3. 当出现 error 的时候, 只 rollback SP 内的执行, 其余的交由外部. 外部捕获 error 后可以选择是否要忽略 SP 的问题 (skip 掉 SP), 或者连外部一柄 rollback.
在 SP 内 rollback save point 是不会修改 @@TRANCOUNT 的, 也相等于整个 SP 对外部完全没有产生任何副作用.
oh yeah, 至此 SQL Server 利用了许多规则终于实现了事务嵌套.
SP 大概长这样
create procedure SP_DoSomething
AS
declare @startCount int;
set @startCount = @@TRANCOUNT;
if @startCount = 0
begin tran;
else
save transaction SavePoint1; begin try
-- do anything your want
if @startCount = 0
commit;
end try
begin catch
if @startCount = 0
rollback;
else
IF XACT_STATE() <> -1
rollback transaction SavePoint1;
throw;
end catch
补充说明:
XACT_STATE() 会返回一个数 (1, 0 或者 -1)
1 表示 transaction 中没有任何 query 报错. 那进入到 catch 的原因可能是其它的逻辑问题 (比如 convert 失败等等)
0 表示 transaction 中没有任何 side effect 的 query. 没有 insert, update, 都是 select 操作
-1 表示 transaction 中有执行失败的 query. 在这个时候我们就必须执行 rollback 了.
SQL Server – Transaction & Isolation 事务与隔离的更多相关文章
- 转载 SQL Server 2008 R2 事务与隔离级别实例讲解
原文:http://blog.itpub.net/13651903/viewspace-1082730/ 一.事务简介 SQL Server的6个隔离级别中有5个是用于隔离事务的,它们因而被称作事务隔 ...
- SQL Server中的事务与其隔离级别之脏读, 未提交读,不可重复读和幻读
原本打算写有关 SSIS Package 中的事务控制过程的,但是发现很多基本的概念还是需要有 SQL Server 事务和事务的隔离级别做基础铺垫.所以花了点时间,把 SQL Server 数据库中 ...
- (转)深入sql server中的事务
原文地址:http://www.cnblogs.com/chnking/archive/2007/05/27/761209.html 参考文章:http://www.cnblogs.com/zhuif ...
- SQL Server 中的事务与事务隔离级别以及如何理解脏读, 未提交读,不可重复读和幻读产生的过程和原因
原本打算写有关 SSIS Package 中的事务控制过程的,但是发现很多基本的概念还是需要有 SQL Server 事务和事务的隔离级别做基础铺垫.所以花了点时间,把 SQL Server 数据库中 ...
- Sql Server中的事务隔离级别
数据库中的事物有ACID(原子性,一致性,隔离性,持久性)四个特性.其中隔离性是用来处理并发执行的事务之间的数据访问控制.SqlServer中提供了几种不同级别的隔离类型. 概念 Read UnCom ...
- Microsoft SQL Server中的事务与并发详解
本篇索引: 1.事务 2.锁定和阻塞 3.隔离级别 4.死锁 一.事务 1.1 事务的概念 事务是作为单个工作单元而执行的一系列操作,比如查询和修改数据等. 事务是数据库并发控制的基本单位,一条或者一 ...
- 【转】SQL Server中的事务与锁
SQL Server中的事务与锁 了解事务和锁 事务:保持逻辑数据一致性与可恢复性,必不可少的利器. 锁:多用户访问同一数据库资源时,对访问的先后次序权限管理的一种机制,没有他事务或许将会一塌糊涂 ...
- SQL Server与Oracle中的隔离级别
在SQL92标准中,事务隔离级别分为四种,分别为:Read Uncommitted.Read Committed.Read Repeatable.Serializable 其中Read Uncommi ...
- sql server 锁与事务拨云见日(中)
一.事务的概述 上一章节里,重点讲到了锁,以及锁与事务的关系.离上篇发布时间好几天了,每天利用一点空闲时间还真是要坚持.听<明朝那些事儿>中讲到"人与人最小的差距是聪明,人与人最 ...
- Sql Server并发和事务
锁的作用范围通常在事务中,事务是建立在并发模式下. 从SQL Server 2005开始,加入了一种新的并发模式-----乐观并发.不管使用哪种并发模式,如果多个会话同时修改相同的数据,都会产生资源争 ...
随机推荐
- ArkTS基础知识
[习题]ArkTS基础知识 及格分85/ 满分100 判断题 1. 循环渲染ForEach可以从数据源中迭代获取数据,并为每个数组项创建相应的组件. 正确(True)错误(False) 回答正确 ...
- [oeasy]python020在游戏中体验数值自由_勇闯地下城_终端文字游戏
继续运行 回忆上次内容 上次使用shell环境中的命令 命令 作用 cd 改变文件夹 pwd 显示当前文件夹 ls 列出当前文件夹下的内容 最终 进入 目录 找到 游戏 如果git clone 根 ...
- Vue 基于VSCode结合Vetur+ESlint+Prettier统一Vue代码风格
基于VSCode结合Vetur+ESlint+Prettier统一Vue代码风格 插件安装 安装Vetur,ESlint, Prettier - Code formatter插件 安装方法(安装ESl ...
- Rust 中 *、&、mut、&mut、ref、ref mut 的用法和区别
Rust 中 *.&.mut.&mut.ref.ref mut 的用法和区别 在 Rust 中,*.ref.mut.& 和 ref mut 是用于处理引用.解引用和可变性的关键 ...
- mysql 主从复制 + thinkphp 读写分离
好处:加快查询速度.数据库热备份等 注意:要跨服务器,先准备一个虚拟机或者docker,同一个服务器意义不大,而且风险大. 注意:本文档学习原理使用,线上可使用阿里云rds自带的读写分离 主从复制: ...
- 免费正版 IntelliJ IDEA license 详细指南
一.前言 IntelliJ IDEA 一直是我非常喜欢的 IDE 自从用上之后就回不了头了,但是 Ultimate 版本的费用十分昂贵,其实 JetBrains 自己就提供了6种免费申请授权的方式:本 ...
- 代码随想录Day2
209.长度最小的子数组 给定一个含有 n 个正整数的数组和一个正整数 target . 找出该数组中满足其总和大于等于 target 的长度最小的 子数组 $ [nums_l, nums_{l+1} ...
- 9、SpringMVC之处理静态资源
9.1.环境搭建 9.1.1.在project创建新module 9.1.2.选择maven 9.1.3.设置module名称和路径 9.1.4.module初始状态 9.1.5.配置打包方式和引入依 ...
- 【Java】部门集合树状顺序展示
一.需求效果: 表单的部门下拉选择时,可以展示部门的层级: 按照这个效果展示,但是不是树,还是原来的集合 二.实现方案: 用Java代码实现两个部分 1.展示Label效果处理 2.处理集合的树状排序 ...
- 【ActiveJdbc】01 入门
官方快速上手文档: https://javalite.io/activejdbchttps://javalite.io/getting_started 完整介绍: https://javalite.i ...