batch normalization的multi-GPU版本该怎么实现? 【Tensorflow 分布式PS/Worker模式下异步更新的情况】
最近由于实验室有了个AI计算平台,于是研究了些分布式和单机多GPU的深度学习代码,于是遇到了下面的讨论:
https://www.zhihu.com/question/59321480/answer/198077371
那么batch normalization的multi-GPU版本该怎么实现呢?由于个人只使用过Tensorflow 分布式PS/Worker模式下异步更新的情况,所以也就在这里说说自己对这个情况下如何实现。
batch nrmalization中的mean,variance是不可训练的局部参数,alpha,beta是可训练的全局参数,由于beta,gama是可训练参数所以和网络中的其他参数一样所以这里不特殊考虑,而需要特殊考虑的就是这里的mean,variance这两个不可训练的局部参数。
个人判断:
单机多GPU的网络参数的更新(包括 batch nrmalization中的mean,variance是不可训练的局部参数,beta,gama是可训练的全局参数),就是在使用loss对网络参数进行梯度更新前对batch_norlization中的mean,variance进行更新,代码如下:
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops): #保证train_op在update_ops执行之后再执行。
train_op = optimizer.minimize(loss)
多GPU或分布式环境下的PS/Worker异步更新模式下,batch normalization这个操作会怎么表示呢,个人观点如下:
分布式环境下的PS/Worker异步更新模式下:
batch normalization这个操作:

说的就是在train_op之前对网络中的batch_normalization操作中的全局mean和variance进行动量更新:
global_mean=(1- m)*global_mean+m*batch_mean
global_var=(1- m)*global_var+m*batch_var
而在PS/Worker异步更新模式下, 我们一般这么设置变量的所在设备:

而这也意味着 局部变量的mean,variance也是存在于 PS 端的,那么在 PS/Worker异步更新模式下 我们是没有必要对mean,variance这两个局部变量做什么特殊处理的,因为这两个局部变量和全局变量一样自然会进行异步的更新。
给出一个PS异步更新模式下打印分配设备的图:

从上图可以看到,mean,variance 与 beta,gama 一样都是分配在PS 端的。
所以,PS异步更新模式下 无需对 batch_normalization再做其他的改动便可以实现异步更新了。
单机多GPU情况下:
1. 计算各全局可训练variable的梯度
# Calculate the gradients for the batch of data on this CIFAR tower.
grads = opt.compute_gradients(loss)
2. 计算多个GPU中对variable的的梯度的平均
average_gradients
3. 将得到的各GPU种对variable的梯度的平均更新回variable中
# Apply the gradients to adjust the shared variables.
apply_gradient_op = opt.apply_gradients(grads, global_step=global_step)
以上1,2,3步骤是对可训练的variable的操作,这里我们如果有batch_normalization操作时对于不可训练的batch_normalization中的mean,var局部变量也需要更新。
第一种做法: 如果将操作
tf.GraphKeys.UPDATE_OPS
不加入到计算图的依赖中的话,我们可以这么做:
需要手动改动的地方则在1中,需要将各GPU中的batch_mean,batch_var如可训variable那样进行收集;
在2步骤中,需要单独将不可训练的各GPU中的batch_mean,batch_var如可训variable那样进行手动取均值(其实,这里我们是不是可以获得所有gpu上batch数据的均值,然后再获得所有GPU上数据的方差呢);
在3步骤中,手动将计算的平均后的batch_mean,batch_var更新到global_mean,global_var中。
该种做法对 mean,var两个不可训练参数同其他可训练参数一样进行了同步更新。
第二种做法: 如果将操作
tf.GraphKeys.UPDATE_OPS
加入到计算图的依赖中的话,我们可以这么做:
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops): #保证train_op在update_ops执行之后再执行。
train_op = opt.compute_gradients(loss)
这样的话不需要对batch_normalization中的mean,var进行额外操作,该种做法对 mean,var两个不可训练参数进行异步更新,而对同其他可训练参数进行同步更新。
第二种方法比第一种要方便简单些,同时对全局mean,var的更新不会有太大的影响。
---------------------------------
对于 PS模式下同步更新的情况:
个人观点该情况下和单机多GPU中的第二种方法相同,就是将
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
加入到图的依赖中。
因为在PS下的同步更新中只对可训练的variable进行梯度平均后更新,因此此种情况下和单机多GPU中的第二种方法相同对全局mean,var进行异步更新也是OK的,而且不太会有太大性能上的影响。
--------------------------------------------------------------------------------
其实对于多GPU, 或者分布式的环境下讨论batch_normalization中的全局mean和var如果更新获得(异步方式,同步方式)意义并不大,个人感觉这问题甚至有些伪命题的感觉。(只为个人观点)
batch_normalizaiton中的batch的mean,var是指通过batch中的少量数据估计某层输出tensor的均值,方差,并用其动量的更新全局mean,var。如果一个GPU运行100steps,就是更新100次全局mean,var; 如果4个GPU就是每个进行25steps, 每个step是把各gpu上batch内的数据求均值,方差,然后再求4个GPU的平均的 均值,方差,然后再更新全局均值,方差 (也或许将4个GPU上的batch数据全部拼在一起求均值,方差);这两种方法本身都是种估计,两者之间会有很大差距吗,个人很是怀疑。
由于水平问题,不能实现上面说的各种方法以探讨不同方式对全局mean,var的影响,但是给出下面模拟一个分布的数据集,已知其全局均值,方差,通过单个batch数据更新全局mean,var或使用几个batch的数据各自的mean,var 的均值更新,或是使用几个batch的数据拼在一起的mean,var 来进行更新,试着模拟一下网络训练中的过程,看看这几种方法的最终结果的差距:
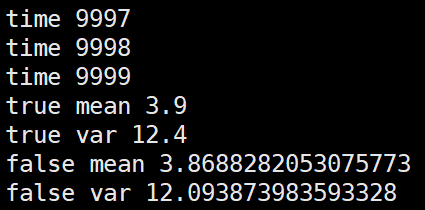
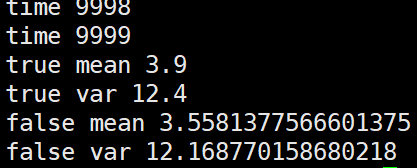
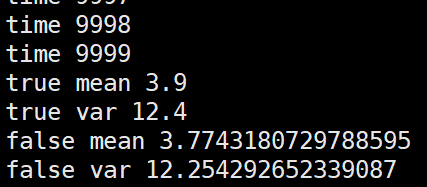
第一种,逐个batch的更新全局mean,var
import numpy as np m = 3.9
v = 12.4 alpha=0.1 false_mean = 0
false_var = 0 for i in range(10000):
sub_data_0 = np.random.normal(m, v, 100) _false_mean = np.mean(sub_data_0)
_false_var = np.var(sub_data_0)**0.5
false_mean = (1-alpha)*false_mean + alpha*_false_mean
false_var = (1-alpha)*false_var + alpha*_false_var print("time", i) print("true mean", m)
print("true var", v)
print("false mean", false_mean)
print("false var", false_var)

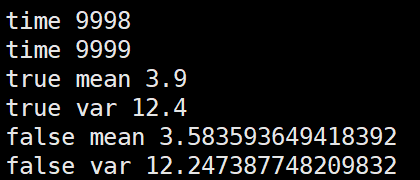
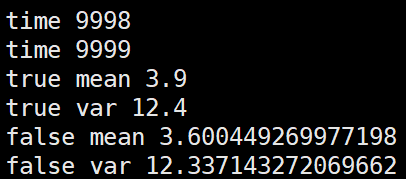
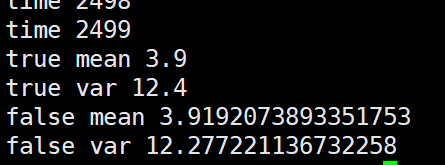
第二种,根据几个batch的mean,var求均值后再更新全局mean,var
import numpy as np m = 3.9
v = 12.4 alpha=0.1 false_mean = 0
false_var = 0 for i in range(10000//4):
sub_data_0 = np.random.normal(m, v, 100)
_false_mean_0 = np.mean(sub_data_0)
_false_var_0 = np.var(sub_data_0)**0.5 sub_data_1 = np.random.normal(m, v, 100)
_false_mean_1 = np.mean(sub_data_0)
_false_var_1 = np.var(sub_data_0)**0.5 sub_data_2 = np.random.normal(m, v, 100)
_false_mean_2 = np.mean(sub_data_0)
_false_var_2 = np.var(sub_data_0)**0.5 sub_data_3 = np.random.normal(m, v, 100)
_false_mean_3 = np.mean(sub_data_0)
_false_var_3 = np.var(sub_data_0)**0.5 _false_mean = np.mean([_false_mean_0,_false_mean_1,_false_mean_2,_false_mean_3])
_false_var = np.mean([_false_var_0,_false_var_1,_false_var_2,_false_var_3]) false_mean = (1-alpha)*false_mean + alpha*_false_mean
false_var = (1-alpha)*false_var + alpha*_false_var print("time", i) print("true mean", m)
print("true var", v)
print("false mean", false_mean)
print("false var", false_var)
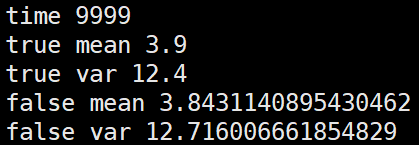
第三种,将几个batch的数据拼在一起求mean,var后再更新全局mean,var
import numpy as np m = 3.9
v = 12.4 alpha=0.1 false_mean = 0
false_var = 0 for i in range(10000//4):
sub_data_0 = np.random.normal(m, v, 100)
sub_data_1 = np.random.normal(m, v, 100)
sub_data_2 = np.random.normal(m, v, 100)
sub_data_3 = np.random.normal(m, v, 100) _false_mean = np.mean([sub_data_0, sub_data_1, sub_data_2, sub_data_3])
_false_var = np.var([sub_data_0, sub_data_1, sub_data_2, sub_data_3])**0.5 false_mean = (1-alpha)*false_mean + alpha*_false_mean
false_var = (1-alpha)*false_var + alpha*_false_var print("time", i) print("true mean", m)
print("true var", v)
print("false mean", false_mean)
print("false var", false_var)
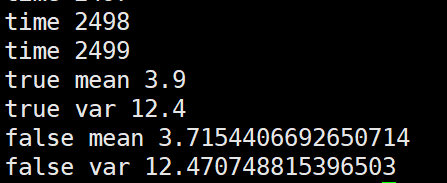
个人观点就是这几种更新方法没有太大的,太明显的性能差距。
----------------------
batch normalization的multi-GPU版本该怎么实现? 【Tensorflow 分布式PS/Worker模式下异步更新的情况】的更多相关文章
- Linux服务器配置GPU版本的pytorch Torchvision TensorFlow
最近在Linux服务器上配置项目,项目需要使用GPU版本的pytorch和TensorFlow,而且该项目内会同时使用TensorFlow的GPU和CPU. 在服务器上装环境,如果重新开始,就需要下载 ...
- 【转载】 深度学习总结:用pytorch做dropout和Batch Normalization时需要注意的地方,用tensorflow做dropout和BN时需要注意的地方,
原文地址: https://blog.csdn.net/weixin_40759186/article/details/87547795 ------------------------------- ...
- Angular版本1.2.4在IE11的IE8模式下出错解决方案
今天,群里一个兄弟抛出一个问题(如上),截图说明. 打断点调试下,貌似是console里面的log方法出错了,如下: 这个是console的log方法,为什么错呢,继续: 我们会发现,在这里是检测fu ...
- keras使用多GPU并行训练模型 | keras multi gpu training
本文首发于个人博客https://kezunlin.me/post/95370db7/,欢迎阅读最新内容! keras multi gpu training Guide multi_gpu_model ...
- [C2W3] Improving Deep Neural Networks : Hyperparameter tuning, Batch Normalization and Programming Frameworks
第三周:Hyperparameter tuning, Batch Normalization and Programming Frameworks 调试处理(Tuning process) 目前为止, ...
- [源码解析] NVIDIA HugeCTR,GPU 版本参数服务器---(7) ---Distributed Hash之前向传播
[源码解析] NVIDIA HugeCTR,GPU 版本参数服务器---(7) ---Distributed Hash之前向传播 目录 [源码解析] NVIDIA HugeCTR,GPU 版本参数服务 ...
- [源码解析] NVIDIA HugeCTR,GPU 版本参数服务器---(8) ---Distributed Hash之后向传播
[源码解析] NVIDIA HugeCTR,GPU 版本参数服务器---(8) ---Distributed Hash之后向传播 目录 [源码解析] NVIDIA HugeCTR,GPU 版本参数服务 ...
- [源码解析] NVIDIA HugeCTR,GPU 版本参数服务器 --(9)--- Local hash表
[源码解析] NVIDIA HugeCTR,GPU 版本参数服务器 --(9)--- Local hash表 目录 [源码解析] NVIDIA HugeCTR,GPU 版本参数服务器 --(9)--- ...
- 从Bayesian角度浅析Batch Normalization
前置阅读:http://blog.csdn.net/happynear/article/details/44238541——Batch Norm阅读笔记与实现 前置阅读:http://www.zhih ...
- [CS231n-CNN] Training Neural Networks Part 1 : activation functions, weight initialization, gradient flow, batch normalization | babysitting the learning process, hyperparameter optimization
课程主页:http://cs231n.stanford.edu/ Introduction to neural networks -Training Neural Network ________ ...
随机推荐
- INFINI Easysearch 与兆芯完成产品兼容互认证
近日,极限科技旗下软件产品 INFINI Easysearch 搜索引擎软件 V1.0 与兆芯完成兼容性测试,功能与稳定性良好,并获得兆芯产品兼容互认证书. 此次兼容适配基于银河麒麟高级服务器操作系统 ...
- redis数据持久化篇
为什么需要持久化 Redis是个基于内存的数据库. 那服务一旦宕机,内存中的数据将全部丢失. 通常的解决方案是从后端数据库恢复这些数据,但后端数据库有性能瓶颈 如果是大数据量的恢复,1.会对数据库带来 ...
- 燕千云 YQCloud 数智化业务服务管理平台 发布1.13版本
2022年6月10日,燕千云 YQCloud 数智化业务服务管理平台发布1.13版本.本次燕千云1.13版本新增了远程桌面.知识库多人在线协作.移动端疫苗核酸信息管理.单据委托代理.技能管理.产品自助 ...
- 反模式 DI anti-patterns
反模式 DI anti-patterns 反模式DI anti-patterns <Dependency Injecttion Prinsciples,Practices, and Patter ...
- Java解析微信获取手机号信息
在微信中,用户手机号的获取通常是通过微信小程序的getPhoneNumber接口来实现的.这个接口允许用户在授权后,将加密的手机号数据传递给开发者.由于隐私保护,微信不会直接提供用户的明文手机号,而是 ...
- Redis八股文(大厂面试真题)
号:tutou123com我是小宋编码,Java程序员 ,只熬夜但不秃头. 关注我,带你轻松过面试.提升简历亮点如果你觉得对你有帮助,欢迎关注[1] 内容目录 1.说说redis,了解redis源码 ...
- Kafka Stream 以及其他流处理框架对比
1. Kafka Stream Introduction 假设我们需要对kafka 消息做流数据分析,例如: 对部分消息做过滤 每分钟计算一次收到了多少消息 这种情况下,对于消息过滤以及定时统计,甚至 ...
- XIP技术与Flash
XIP技术与Flash 参考: 串行NAND Flash的两大特性导致其在i.MXRT FLASH控制器下无法XiP norflash芯片内执行(XIP) NOR Flash 和 NAND Flash ...
- Android 7 修改启动动画和开机声音
背景 在修改开机音量的时候,发现找不到对应的声音功能调用. 因此了解了一下安卓的开机声音是如何实现的. 安卓4~安卓7 都可以这么做. 参考: https://blog.csdn.net/chen82 ...
- 修改Git Commit提交记录的用户名Name和邮箱Email
修改Git 本次Commit提交记录的用户名Name和邮箱Email git commit --amend --author="new-name <xxx@new.com>&qu ...