python-使用百度AipOcr实现表格文字图片识别
注:本博客中的代码实现来自百度问答:https://jingyan.baidu.com/article/c1a3101ef9131c9e646deb5c.html
代码运行环境:win10 python3.7
需要aip库,使用pip install baidu-aip即可
(1)目的
通过百度AipOcr库,来实现识别图片中的表格,并输出问表格文件。
(2)实现
仿照百度问答:https://jingyan.baidu.com/article/c1a3101ef9131c9e646deb5c.html,实现了以下代码:
1 # encoding: utf-8
2 import os
3 import sys
4 import requests
5 import time
6 import tkinter as tk
7 from tkinter import filedialog
8 from aip import AipOcr
9
10 # 定义常量
11 APP_ID = 'xxxxxx'
12 API_KEY = 'xxxxxxxxxxxxxxxxxxxxxx'
13 SECRET_KEY = 'xxxxxxxxxxxxxxxxxxxxxxxxx'
14 # 初始化AipFace对象
15 client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
16
17 # 读取图片
18 def get_file_content(filePath):
19 with open(filePath, 'rb') as fp:
20 return fp.read()
21
22
23 #文件下载函数
24 def file_download(url, file_path):
25 r = requests.get(url)
26 with open(file_path, 'wb') as f:
27 f.write(r.content)
28
29
30 if __name__ == "__main__":
31 root = tk.Tk()
32 root.withdraw()
33 data_dir = filedialog.askdirectory(title='请选择图片文件夹') + '/'
34 result_dir = filedialog.askdirectory(title='请选择输出文件夹') + '/'
35 num = 0
36 for name in os.listdir(data_dir):
37 print ('{0} : {1} 正在处理:'.format(num+1, name.split('.')[0]))
38 image = get_file_content(os.path.join(data_dir, name))
39 res = client.tableRecognitionAsync(image)
40 # print ("res:", res)
41 if 'error_code' in res.keys():
42 print ('Error! error_code: ', res['error_code'])
43 sys.exit()
44 req_id = res['result'][0]['request_id'] #获取识别ID号
45
46 for count in range(1, 20): #OCR识别也需要一定时间,设定10秒内每隔1秒查询一次
47 res = client.getTableRecognitionResult(req_id) #通过ID获取表格文件XLS地址
48 print(res['result']['ret_msg'])
49 if res['result']['ret_msg'] == '已完成':
50 break #云端处理完毕,成功获取表格文件下载地址,跳出循环
51 else:
52 time.sleep(1)
53
54 url = res['result']['result_data']
55 xls_name = name.split('.')[0] + '.xls'
56 file_download(url, os.path.join(result_dir, xls_name))
57 num += 1
58 print ('{0} : {1} 下载完成。'.format(num, xls_name))
59 time.sleep(1)
(3)实现效果
识别的表格图片为:

实现的效果为(注:表格的格式人为调整过,但内容没人为修改):
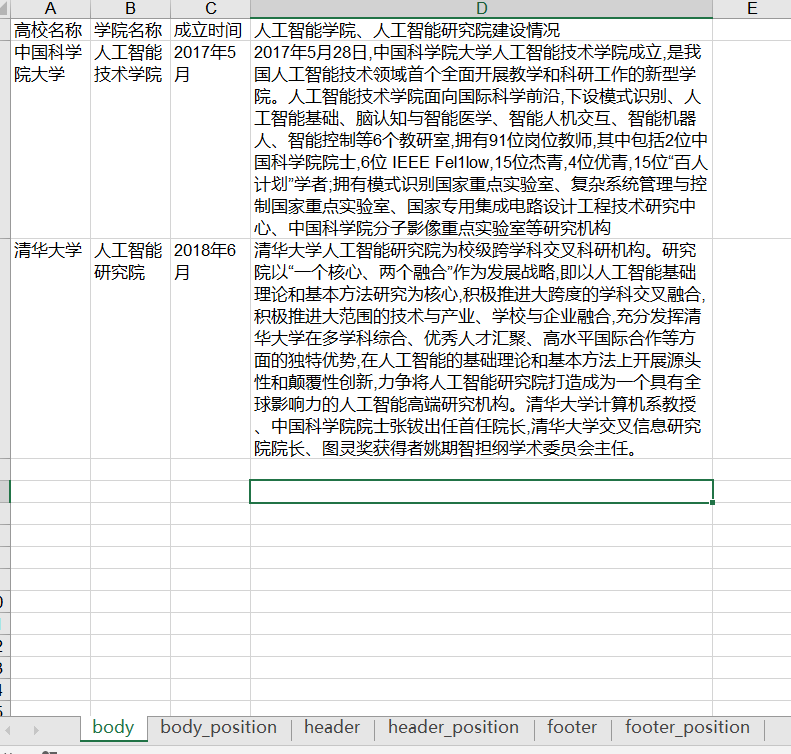
可以看出,识别的精度还是很高的,只有“Fellow”识别为了“Fel1low”。
(4)其它
百度智能云应用创建链接:https://console.bce.baidu.com/ai/?_=1585935093810#/ai/ocr/app/list,创建了一个应用之后,就可以获得APP_ID、API_KEY、SECRET_KEY。
百度智能云文字识别接口说明:https://cloud.baidu.com/doc/OCR/s/3k3h7yeqa。
python-使用百度AipOcr实现表格文字图片识别的更多相关文章
- 小白学Python——用 百度AI 实现 OCR 文字识别
百度AI功能还是很强大的,百度AI开放平台真的是测试接口的天堂,免费接口很多,当然有量的限制,但个人使用是完全够用的,什么人脸识别.MQTT服务器.语音识别等等,应有尽有. 看看OCR识别免费的量 快 ...
- Springboot 结合百度IORC实现自定义模板图片识别
前言: 首先呢,最近再公司的项目当中遇到这样的一个问题,就是需要识别图片,提取图片当中的关键语句,而且识别的语句当然是人家手写体识别,翻来覆去一想,最终还是决定使用百度的OCR帮助我解决这一项需求 话 ...
- python截图+百度ocr(图片识别)+ 百度翻译
一直想用python做一个截图并自动翻译的工具,恰好最近有时间就在网上找了资料,根据资料以及自己的理解做了一个简单的截图翻译工具.整理一下并把代码放在github给大家参考.界面用python自带的G ...
- Python通过百度Ai识别图片中的文字
版本:python3.7 工作中有需要识别图片中的汗字,查看了半天大神们的博客,但没找到完全可以用的源码,经过自己的实践,以下源码可以实现: 创建应用 首先你需要登录百度AI,选择文字识别,创建一个应 ...
- Python使用EasyOCR库对行程码图片进行OCR文字识别介绍与实践
关注「WeiyiGeek」点我,点我 设为「特别关注」,每天带你在B站玩转网络安全运维.应用开发.物联网IOT学习! 希望各位看友[关注.点赞.评论.收藏.投币],助力每一个梦想. 文章目录 0x00 ...
- 使用python爬取百度贴吧内的图片
1. 首先通过urllib获取网页的源码 # 定义一个getHtml()函数 def getHtml(url): try: page = urllib.urlopen(url) # urllib.ur ...
- Python人工智能之图片识别,Python3一行代码实现图片文字识别
1.Python人工智能之图片识别,Python3一行代码实现图片文字识别 2.tesseract-ocr安装包和中文语言包 注意:
- python基于百度AI开发文字识别
很多场景都会用到文字识别,比如app或者网站里都会上传身份证等证件以及财务系统识别报销证件等等 第一步,你需要去百度AI里去注册一个账号,然后新建一个文字识别的应用 然后你将得到一个API Key 和 ...
- python实现百度OCR图片识别
一.直接上代码 import base64 import requests class CodeDemo: def __init__(self,AK,SK,code_url,img_path): se ...
- Python实现图片识别加翻译【高薪必学】
Python使用百度AI接口实现图片识别加翻译 另外很多人在学习Python的过程中,往往因为没有好的教程或者没人指导从而导致自己容易放弃,为此我建了个Python交流.裙 :一久武其而而流一思(数字 ...
随机推荐
- 实训篇-Html-表格练习1
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- python异步字符串查找,asyncio和marisa_trie
自然语言处理当中经常需要字符串的查找操作,比如通过查找返回字串在文本当中的位置,比如通过匹配实现的ner import pandas as pd import asyncio # data = pd. ...
- 探索Kimi智能助手:如何用超长文本解锁高效信息处理新境界
目前,Kimi备受瞩目,不仅在社交平台上引起了广泛关注,而且在解决我们的实际问题方面也显示出了巨大潜力.其支持超长文本的特性使得我们能够更加灵活地配置信息,避免了频繁与向量数据库进行交互以及编写提示词 ...
- 力扣61(java&python)-旋转链表(中等)
题目: 给你一个链表的头节点 head ,旋转链表,将链表每个节点向右移动 k 个位置. 示例1: 输入:head = [1,2,3,4,5], k = 2 输出:[4,5,1,2,3] 示例2: 输 ...
- 力扣400(java)-第N位数字(中等)
题目: 给你一个整数 n ,请你在无限的整数序列 [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, ...] 中找出并返回第 n 位上的数字. 示例 1: 输入:n = 3输出: ...
- 力扣191(java)-位1的个数(简单)
题目: 编写一个函数,输入是一个无符号整数(以二进制串的形式),返回其二进制表达式中数字位数为 '1' 的个数(也被称为汉明重量). 提示: 请注意,在某些语言(如 Java)中,没有无符号整数类型. ...
- 疫情带火了这款APP:2600个学生一天点赞70万次
这几天,全国中小学生经历了"过山车"一样的心情. 因为疫情的不断蔓延,1月27日,教育部下发通知,2020年春季学期延期开学. 随后,教育部又提出"利用网络平台,停课 ...
- 一文详解 Serverless 架构模式
什么是 Serverless 架构?按照 CNCF 对 Serverless 计算的定义,Serverless 架构应该是采用 FaaS(函数即服务)和 BaaS(后端服务)服务来解决问题的一种设计. ...
- 龙蜥开源内核追踪利器 Surftrace:协议包解析效率提升 10 倍! | 龙蜥技术
简介:如何将网络报文与内核协议栈清晰关联起来精准追踪到关注的报文行进路径呢? 文/系统运维 SIG Surftrace 是由系统运维 SIG 推出的一个 ftrace 封装器和开发编译平台,让用 ...
- 阿里巴巴开源大规模稀疏模型训练/预测引擎DeepRec
简介:经历6年时间,在各团队的努力下,阿里巴巴集团大规模稀疏模型训练/预测引擎DeepRec正式对外开源,助力开发者提升稀疏模型训练性能和效果. 作者 | 烟秋 来源 | 阿里技术公众号 经历6 ...