Intel Pentium III CPU(Coppermine, Tualatin) L2 Cache Latency, Hardware Prefetch特性调查
这几天,偶然的机会想到了困扰自己和其他网友多年的Intel Pentium III系列处理器缓存延迟(L2 Cache Latency),以及图拉丁核心版本是否支持硬件预取(Hardware Prefetch)问题。
手头的支持图拉丁核心处理器的i815主板还在正常服役中,铜矿和图拉丁核心处理器也都有,所以就专门做了这一期调查,感兴趣的网友可以在评论区共同探讨指正错误。
参与评测的3款处理器
Intel Pentium III 1000MHz, Coppermine, 256KB L2, 133MHz FSB
Intel Celeron 1000MHz, Tualatin, 256KB L2, 100MHz FSB
Intel Pentium III -S 1400MHz, Tualatin, 512KB L2, 133MHz FSB
参与评测的操作系统是Windows 2000 SP4
首先,贴上测试结果截图,里面包含了缓存延迟,硬件预取相关测试信息,调查结果与原以为的结果大相径庭,后面会进行解释。
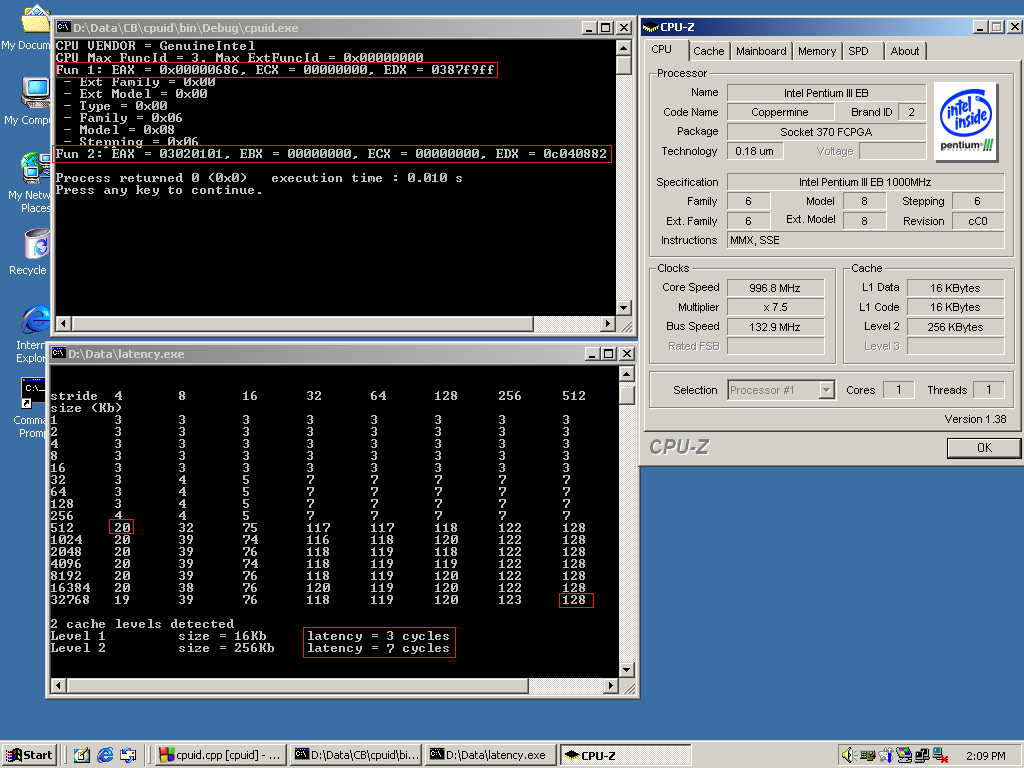
Intel Pentium III 1000MHz(铜矿奔腾3 1G)
Intel Celeron 1000MHz(图拉丁赛扬 1G)

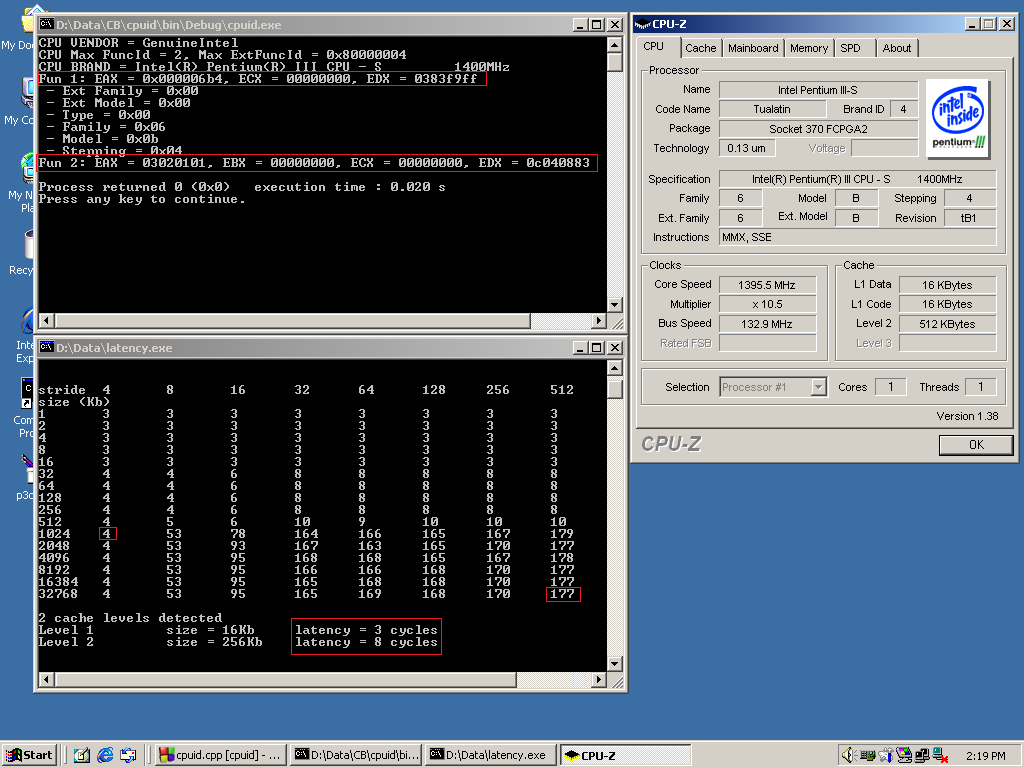
Intel Pentium III -S 1400MHz(图拉丁奔3-S 1.4G)
1)Cache latency
首先,声明一点,到了Pentium III处理器(含同级别赛扬),L2 Cache已经是内置的全速Cache了,最早期的赛扬处理器才有半速Cache的设计,这一点还可以通过AIDA64等硬件检测工具确认。
其次,本文的重点内容之一,具体latency数据,是通过CPU-Z 1.38自带的工具latency.exe测试出来的,图片中的latency.exe的输出就是。
从测试结果看,缓存延迟数据最佳的,竟然是铜矿奔腾3,图拉丁赛扬毕竟是低端,然而图拉丁奔腾3-S 1.4GHz就是整个奔腾3系列处理器里面的顶配了,按说应该是所有参数拉满才对,实际数据说明:
L2 Cache Latency排名(越低越好):
铜矿奔腾
图拉丁赛扬
图拉丁奔腾3-S
2)Hardware Prefetch
硬件预取特性,是根据CPUID信息来检测的,x86处理器的CPUID指令会根据输入EAX的数值,决定功能编号,不同的功能编号,会返回不同的特性数据,截图里面cpuid.exe程序是基于CodeBlocks开源IDE
编译出来的。
根据Intel公司官网发布的cpuid相关文档,找到了CPUID(2),也即CPUID #2号功能的返回值,可以确定CPU是否支持硬件预取,以下截图来自Intel公司2011年发布的文档:
processor-identification-cpuid-instruction-note.pdf

CPUID(2)的部分描述符含义解释:
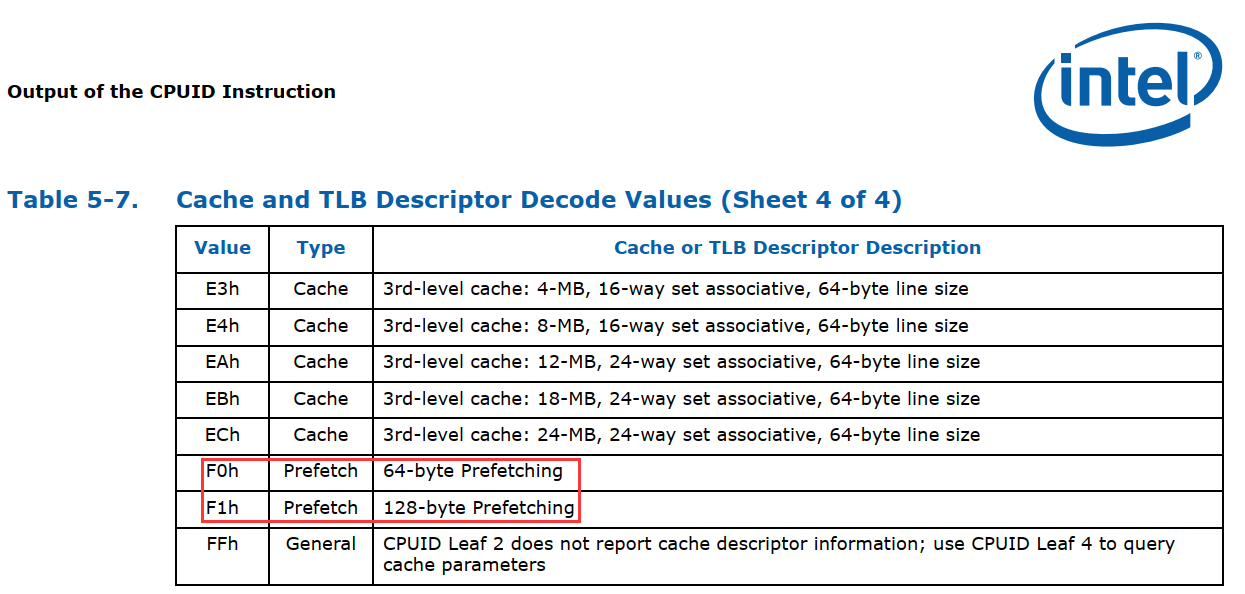
如果CPUID(2)输出寄存器中(EAX,EBX,ECX,EDX)中包含有0xF0或者0xF1,则表示该处理器支持硬件预取,而且预取数据宽度是64字节或者128字节。
然而,从cpuid.exe的输出看,Fun #2的输出里面,三款处理器都没有0xF0或者0xF1,说明:
Intel Pentium III系列,包括铜矿和图拉丁系列处理器,均不支持硬件预取(Hardware Prefetch)。
3)CPUID相关其他信息
另外,顺便解释一下cpuid.exe里面的Fun #1,即CPUID(1)的输出,这个1号功能,用来查询该CPU的Family-Model-Stepping信息(由EAX寄存器输出),这里参与评测的3款处理器的这些信息不同,
所以EAX寄存器内容不同,具体可以参考右边cpu-z的截图。另外,ECX和EDX输出的是指令集特性,比如是否支持MMX,SSE,VME,PSN(处理器序列号)等特性,可以看到差异:
铜矿奔腾的EDX = 0387F9FF,两款图拉丁处理器的EDX = 0383F9FF。
这里的16进制的7,比3多出了一个使能位,就是Bit 18,查询上述CPUID手册,可以发现,这个位就是PSN标志位,说明:
Intel铜矿核心处理器,才支持PSN(96位的唯一处理器序列号),图拉丁赛扬和奔腾,并不支持PSN。
处理器的PSN,是通过CPUID(3)来获取的,所以,对应的铜矿核心处理器,比图拉丁核心处理器的最大基础CPUID功能号是3,图拉丁的则是2(即截图中的Max FuncId)。
还有一点,就是铜矿处理器的最大扩展CPUID功能号是0(表示不支持扩展功能),图拉丁的则是0x80000004。扩展功能号里面的0x80000001 ~ 0x80000004,用于获取CPU的商标品牌信息(CPU BRAND)。
最大基础CPUID功能号,就是CPUID(0)的EAX输出。
最大扩展CPUID功能号,就是CPUID(0x80000000)的EAX输出,如果是0,说明不支持扩展功能号。所以:
Intel图拉丁核心处理器,才支持CPUID扩展功能,铜矿核心处理器不支持扩展功能。
这也是铜矿和图拉丁处理器的一个差异,cpu-z工具里面显示的处理器BRAND信息,是通过其他CPUID信息确定出来的,有兴趣可以进一步查阅Intel公司发布的CPUID相关手册。
附上我自己编写的C++语言版的cpuid函数:
void cpuid(u32 in, u32 &eax, u32 &ebx, u32 &ecx, u32 &edx)
{
__asm volatile ("cpuid" : "=a"(eax), "=b"(ebx), "=c"(ecx), "=d"(edx) : "a"(in));
}
4)小结
综合上述调查内容,可以得出结论:
Intel在2000年前后推出的铜矿和图拉丁核心处理器,并不能简单地认为,图拉丁核心一定比同频的铜矿核心处理器要好,硬件预取特性两种核心都不具备,图拉丁的L2 Cache延迟明显比铜矿核心要大些。
图拉丁核心处理器的优势,主要体现在,制造工艺提升到了0.13um,功耗和发热更低,频率更高,上市的产品里面,图拉丁赛扬/奔腾/奔腾-S均有最高1.4GHz的产品,而铜矿核心,止步于1GHz(不过,我在
网上见过1.1GHz 100MHz FSB的铜矿奔腾/赛扬)。没想到的是,图拉丁奔腾III-S的L2缓存延迟,居然比图拉丁赛扬的还要高。
如果两种核心频率相差不大或者相同的话,优先使用铜矿核心处理器,如果更想体验新制程高主频,在乎发热方面的话,就选择图拉丁核心吧。我个人而言,两种核心都会交替使用,因为我会根据需要做各种
相关性能测试跑分什么的,有些对L2 Cache延迟比较敏感,有些对主频比较敏感,具体使用哪一款,根据具体情况而定。
Intel Pentium III CPU(Coppermine, Tualatin) L2 Cache Latency, Hardware Prefetch特性调查的更多相关文章
- L1 Cache, L2 Cache读取命中率与时钟周期计算
CPU在Cache中找到有用的数据被称为命中,当Cache中没有CPU所需的数据时(这时称为未命中),CPU才访问内存.从理论上讲,在一颗拥有2级Cache的CPU中,读取L1 Cache的命中率为8 ...
- TMS320C64x DSP L1 L2 Cache架构(1)——C64x Cache Architecture
[前沿]研究生阶段从事于DSP和FPGA技术的相关研究工作,学习并整理了大量的技术资料,包括TI公司的官方文档和网络上的详细笔记,花费了大量的时间和精力总结了前人的工作成果.无奈工作却从事于嵌入式技术 ...
- intel Xeon(R) CPU E5-2650 v2 性能测试报告
intel Xeon(R) CPU E5-2650 v2 ...
- 使用GetLogicalProcessorInformation获取逻辑处理器的详细信息(NUMA节点数、物理CPU数、CPU核心数、逻辑CPU数、各级Cache)
不过必须XP SP3以上才行.所有API大全: https://msdn.microsoft.com/en-us/library/windows/desktop/aa363804(v=vs.85).a ...
- cpu性能探究 :cache line 原理
參考: 一个解说Direct Mapped Cache很深入浅出的文章: http://www.cs.umd.edu/class/sum2003/cmsc311/Notes/Memory/dir ...
- 怎么让小白理解intel处理器(CPU)的分类
https://www.zhihu.com/question/32669957 目录 如何选购台式机CPU? 1. 英特尔处理器简介(本文) 1.1 聊聊Intel Tick-Tock 2. AMD处 ...
- CPU缓存L1/L2/L3工作原理
点击上方"开源Linux",选择"设为星标" 回复"学习"获取独家整理的学习资料! 一.前言 在过去的几年中,计算机处理器取得了相当大的进步 ...
- intel和AMD CPU性能对比(2016年CPU天梯图)组装电脑必读!
http://www.365pcbuy.com/article-411.html 特别提示:此文已经于2016年10月12日更新!内容变动较大,请细细品鉴! 如何为客户推荐高性价比机型是我站的重要工作 ...
- INTEL 7代CPU I5 7500 集显HD630 WIN7 64位
HD630 在WIN7 下的硬件ID (在设备管理器 - 显卡 - 属性 中查看): PCI\VEN_8086&DEV_5912&SUBSYS_D0001458&REV_04 ...
- Intel processor brand names-Xeon,Core,Pentium,Celeron----Celeron
http://en.wikipedia.org/wiki/Celeron Celeron From Wikipedia, the free encyclopedia Celeron Produ ...
随机推荐
- 使用docker运行nginx服务,挂载自定义配置文件
错误命令: 下面的方式,启动容器时,-d 后面跟一个指定容器ID的参数写在前面,导致容器不能正常启动,出现异常 docker run --name testnginx -d 7f0fd59e0094 ...
- KafkaProducerDemo
package com.lxw.kafkademo; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache ...
- KingbaseES 服务器运行参数配置
Kingbase 服务器运行参数配置 说明: KingbaseES 数据库中,服务器运行参数配和需改有多种方式和注意事项,根据不同的分类配置,修改配置方式不同.关于服务器参数分类请参照[Kingbas ...
- BeautifulSoup 库 和 re 库 解析腾讯视频电影
1 import requests 2 import json 3 from bs4 import BeautifulSoup #网页解析获取数据 4 import sys 5 import re 6 ...
- 在Keycloak中实现多租户并在ASP.NET Core下进行验证
Keycloak是一个功能强大的开源身份和访问管理系统,提供了一整套解决方案,包括用户认证.单点登录(SSO).身份联合.用户注册.用户管理.角色映射.多因素认证和访问控制等.它广泛应用于企业和云服务 ...
- flutter系列之:按比例缩放的AspectRatio和FractionallySizedBox
目录 简介 AspectRatio FractionallySizedBox 总结 简介 我们在构建UI的时候,为了适应不同的屏幕大小,通常需要进行一些自适应的配置,而最常见的自适应就是根据某个宽度或 ...
- JDK 14的新特性:switch表达式
目录 简介 写在前面 连写case switch返回值 yield 总结 简介 switch的新特性可是源远流长,早在JDK 12就以预览功能被引入了,最终在JDK 14成为了正式版本的功能:JEP ...
- OpenHarmony 3.1 Release版本关键特性解析——ArkUI框架又有哪些新增能力?
ArkUI 是一套 UI 开发框架,它提供了开发者进行应用 UI 开发时所必须的能力.随着 OpenAtom OpenHarmony(以下简称"OpenHarmony") 3.1 ...
- C# 面向对象编程进阶:构造函数详解与访问修饰符应用
C# 构造函数 构造函数是一种特殊的方法,用于初始化对象.构造函数的优势在于,在创建类的对象时调用它.它可以用于为字段设置初始值: 示例 获取您自己的 C# 服务器 创建一个构造函数: // 创建一个 ...
- 成为一名 BI数据分析师,这些能力不能少
近些年来,随着数据技能的日益普及和数据工具的不断简化,大数据技术的迅速发展催生了很多新生职业,BI数据分析师就是其中一个岗位. 说到BI数据分析,我们首先要说的是 BI,它的全称是 Business ...