[转帖]oracle导出千万级数据为csv格式
当数据量小时(20万行内),plsqldev、sqlplus的spool都能比较方便进行csv导出,但是当数据量到百万千万级,这两个方法非常慢而且可能中途客户端就崩溃,需要使用其他方法。
一、 sqluldr2工具
1. 优缺点
- 优点:高效;支持功能较多;用户只需有对应表查询权限;可以在从库执行
- 缺点:目前已没有再维护,只能找到基于oracle 10.2的版本(高版本目前还可以用);密码必须要跟在用户名后面输,安全性不足
2. 下载安装
- 百度云链接:https://pan.baidu.com/s/1V8eqyyYsbJqQSD-Sn-RQGg 提取码:6mdn
下载完后并解压会生成4个文件
- sqluldr2.exe 用于32位windows平台
- sqluldr264.exe 用于64位windows平台
- sqluldr2_linux32_10204.bin 用于linux32位操作系统
- sqluldr2_linux64_10204.bin 用于linux64位操作系统
Windows的可以直接用,Linux的需要加执行权限。
chmod +x sqluldr2_linux64_10204.bin
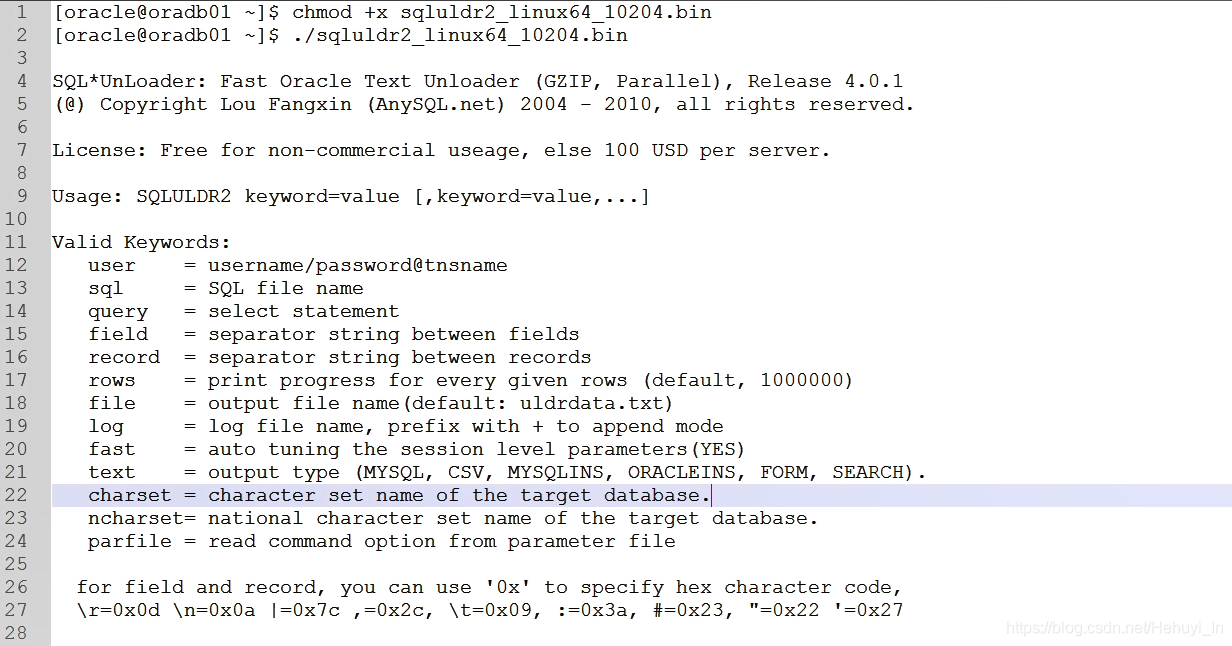
3. 导出csv格式数据
/data/bak目录需要预先建好,oracle用户可写。如果查询语句较复杂,可以建成一个临时视图,通过视图导出,避免写一堆语句。
./sqluldr2_linux64_10204.bin myuser/xxxxxxx query="select * from tmp1201_all_v" head=yes file=/data/bak/tmp1201_all_v.csv
测试700万左右数据导出约12分钟(15:47开始执行),主要是视图查询较慢,导出表应该更快。

二、 利用存储过程
1. 优缺点
- 优点:效率较高;原生sql、目前无版本问题;可自行增加需要功能
- 缺点:需要sys权限;只能在主库执行;功能相对较少
2. sys用户建存储过程
代码转载自 https://blog.csdn.net/lxp90/article/details/80926236
-
CREATE OR REPLACE PROCEDURE SQL_TO_CSV
-
(
-
P_QUERY IN VARCHAR2, -- PLSQL文
-
P_DIR IN VARCHAR2, -- 导出的文件放置目录
-
P_FILENAME IN VARCHAR2 -- CSV名
-
)
-
IS
-
L_OUTPUT UTL_FILE.FILE_TYPE;
-
L_THECURSOR INTEGER DEFAULT DBMS_SQL.OPEN_CURSOR;
-
L_COLUMNVALUE VARCHAR2(4000);
-
L_STATUS INTEGER;
-
L_COLCNT NUMBER := 0;
-
L_SEPARATOR VARCHAR2(1);
-
L_DESCTBL DBMS_SQL.DESC_TAB;
-
P_MAX_LINESIZE NUMBER := 32000;
-
BEGIN
-
--OPEN FILE
-
L_OUTPUT := UTL_FILE.FOPEN(P_DIR, P_FILENAME, 'W', P_MAX_LINESIZE);
-
--DEFINE DATE FORMAT
-
EXECUTE IMMEDIATE 'ALTER SESSION SET NLS_DATE_FORMAT=''YYYY-MM-DD HH24:MI:SS''';
-
--OPEN CURSOR
-
DBMS_SQL.PARSE(L_THECURSOR, P_QUERY, DBMS_SQL.NATIVE);
-
DBMS_SQL.DESCRIBE_COLUMNS(L_THECURSOR, L_COLCNT, L_DESCTBL);
-
--DUMP TABLE COLUMN NAME
-
FOR I IN 1 .. L_COLCNT LOOP
-
UTL_FILE.PUT(L_OUTPUT,L_SEPARATOR || '"' || L_DESCTBL(I).COL_NAME || '"'); --输出表字段
-
DBMS_SQL.DEFINE_COLUMN(L_THECURSOR, I, L_COLUMNVALUE, 4000);
-
L_SEPARATOR := ',';
-
END LOOP;
-
UTL_FILE.NEW_LINE(L_OUTPUT); --输出表字段
-
--EXECUTE THE QUERY STATEMENT
-
L_STATUS := DBMS_SQL.EXECUTE(L_THECURSOR);
-
-
--DUMP TABLE COLUMN VALUE
-
WHILE (DBMS_SQL.FETCH_ROWS(L_THECURSOR) > 0) LOOP
-
L_SEPARATOR := '';
-
FOR I IN 1 .. L_COLCNT LOOP
-
DBMS_SQL.COLUMN_VALUE(L_THECURSOR, I, L_COLUMNVALUE);
-
UTL_FILE.PUT(L_OUTPUT,
-
L_SEPARATOR || '"' ||
-
TRIM(BOTH ' ' FROM REPLACE(L_COLUMNVALUE, '"', '""')) || '"');
-
L_SEPARATOR := ',';
-
END LOOP;
-
UTL_FILE.NEW_LINE(L_OUTPUT);
-
END LOOP;
-
--CLOSE CURSOR
-
DBMS_SQL.CLOSE_CURSOR(L_THECURSOR);
-
--CLOSE FILE
-
UTL_FILE.FCLOSE(L_OUTPUT);
-
EXCEPTION
-
WHEN OTHERS THEN
-
RAISE;
-
END;
-
/
3. 创建导出目录
/data/bak目录需要预先建好,oracle用户可写。如果查询语句较复杂,可以建成一个临时视图(sys用户下),通过视图导出,避免写一堆语句。
create or replace directory OUT_PATH_TEMP as '/data/bak';
4. 执行存储过程
-
begin
-
sql_to_csv('select * from tmp1201_all_v','OUT_PATH_TEMP','tmp1201_all_v.csv');
-
end;
-
/
测试700万左右数据导出约23分钟,主要是视图查询较慢,导出表应该更快。

参考
[转帖]oracle导出千万级数据为csv格式的更多相关文章
- php 连接oracle 导出百万级数据
1,我们一般做导出的思路就是,根据我们想要的数据,全部查询出来,然后导出来,这个对数据量很大的时候会很慢,这里我提出来的思想就是分页和缓冲实现动态输出. 2.普通的我就不说了,下面我说一下分页和内存刷 ...
- mysql循环插入千万级数据
mysql使用存储过程循环插入大量数据,简单的一条条循环插入,效率会很低,需要考虑批量插入. 测试准备: 1.建表: CREATE TABLE `mysql_genarate` ( `id` ) NO ...
- 使用POI导出百万级数据到excel的解决方案
1.HSSFWorkbook 和SXSSFWorkbook区别 HSSFWorkbook:是操作Excel2003以前(包括2003)的版本,扩展名是.xls,一张表最大支持65536行数据,256列 ...
- .Net Core导入千万级数据至Mysql
最近在工作中,涉及到一个数据迁移功能,从一个txt文本文件导入到MySQL功能. 数据迁移,在互联网企业可以说经常碰到,而且涉及到千万级.亿级的数据量是很常见的.大数据量迁移,这里面就涉及到一个问题 ...
- 用php导入10W条+ 级别的csv大文件数据到mysql。导出10W+级别数据到csv文件
转自:http://blog.csdn.net/think2me/article/details/12999907 1. 说说csv 和 Excel 这两者都是我们平时导出或者导入数据一般用到的载体. ...
- 数组转xls格式的excel文件&数据转csv格式的excle
/** * 数组转xls格式的excel文件 * @param array $data 需要生成excel文件的数组 * @param string $filename 生成的excel文件名 * 示 ...
- python 爬虫数据存入csv格式方法
python 爬虫数据存入csv格式方法 命令存储方式:scrapy crawl ju -o ju.csv 第一种方法:with open("F:/book_top250.csv" ...
- mysql千万级数据表,创建表及字段扩展的几条建议
一:概述 当我们设计一个系统时,需要考虑到系统的运行一段时间后,表里数据量大约有多少,如果在初期,就能估算到某几张表数据量非常庞大时(比如聊天消息表),就要把表创建好,这篇文章从创建表,增加数据,以及 ...
- Oracle导出数据结构和数据表的方法
1.PLSQL导出数据结构(数据表.序列.触发器.函数.视图) 1)在左侧 点击tables 2)Tools-->Export User Objects 3)红色1 是你要选择导出的表,红色2 ...
- Python数据写入csv格式文件
(只是传递,基础知识也是根基) Python读取数据,并存入Excel打开的CSV格式文件内! 这里需要用到bs4,csv,codecs,os模块. 废话不多说,直接写代码!该重要的内容都已经注释了, ...
随机推荐
- influxdb 进行数据删除和修改
本文为博主原创,转载请注明出处: 1.条件删除数据 InfluxDB 只支持基于时间的删除操作. 可以使用 DELETE 语句来删除指定时间范围内的数据.例如,以下的 SQL 语句将删除 measur ...
- Golang标准库 container/list(双向链表) 的图文解说
Golang标准库 container/list(双向链表) 的图文解说 提到单向链表,大家应该是比较熟悉的了.今天介绍的是 golang 官方库提供的 双向链表. 1.基础介绍 单向链表中的每个节点 ...
- Shell脚本实践总结
对比大小 符号用法:(必须使用双括号) < 小于 (( "$a" < "$b" )) <= 小于等于 (( "$a&q ...
- kubernetes安装(一)
参考: https://www.cnblogs.com/liuyangQAQ/p/17299871.html 部署组件包 名称 安装包 kubeadm集群组件 kubelet-1.20.9 kubea ...
- Java 并发编程(六)并发容器和框架
传统 Map 的局限性 HashMap JDK 1.7 的 HashMap JDK 1.7 中 HashMap 的实现只是单纯的 "数组 + 链表 " 的组合方式,具体的组成如下: ...
- PyTorch项目源码学习(3)——Module类初步学习
torch.nn.Module Module类是用户使用torch来自定义网络模型的基础,Module的设计要求包括低耦合性,高模块化等等.一般来说,计算图上所有的子图都可以是Module的子类,包括 ...
- Java程序接入ChatGPT
目录 0 前言 1 还想体验的小伙伴可以试试 2 Java接入前准备 3 官方支持接入语言 4 调用费用 5 接口调用说明 6 代码实现 6.1 postman调用 6.2 Java调用 7 小结 0 ...
- Java 展开或折叠PDF中的书签
PDF中的书签功能可快速定位到指定阅读位置.对多层书签可根据阅读喜好设置层级展开或折叠.本文将通过Java程序代码介绍如何来实现PDF书签展开或折叠. 程序环境 Spire.Pdf.jar( 免费版3 ...
- Volcano:带你体验容器与批量计算的碰撞的火花
摘要:今年(2020)7月初,Volcano 发布了1.0版本.1.0做为里程碑版本,在Volcano整个规划中起到了承上启下的作用.此次发布的1.0版本支持了GPU共享,作业动态扩缩容,批任务抢占等 ...
- 手把手带你写Node.JS版本小游戏
摘要:今天就利用Node.JS为大家带来简单有趣的的剪刀石头布的小游戏. JavaScript的出现催动了前端开发的萌芽,前后端分离促进了Vue.React等开发框架的发展,Weex.React-Na ...