HStore表全了解:实时入库与高效查询利器
摘要:本文章将从使用者角度介绍HStore概念以及使用。
本文分享自华为云社区《GaussDB(DWS)HStore表讲解》,作者:大威天龙:- 。
HStore表简介
面对实时入库和实时查询要求越来越高的趋势,已有的列存储无法支持并发更新入库,行存查询性能无法做到实时返回且空间压缩表现不佳。GaussDB(DWS)基于列存储格式设计和实现了全新的HStore表,同时提供高效的并发插入、更新入库,以及高性能实时查询。本文章将从使用者角度介绍HStore概念以及使用。
HStore表的背景
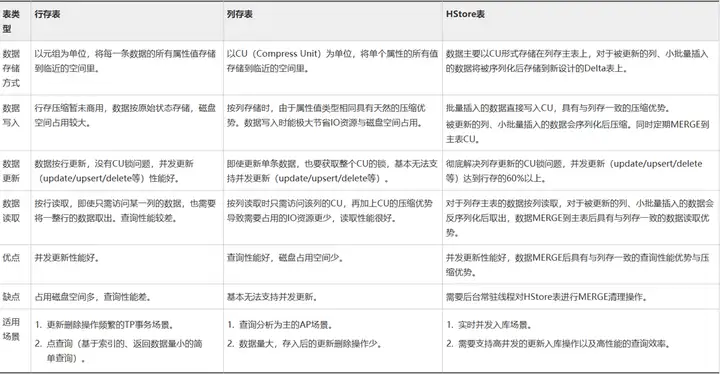
为什么要有HStore表呢?在具体讲解HStore表之前,我们先来回顾一下GaussDB(DWS)中几种已有的表类型:
行存表(row-store)
最基础的表类型,顾名思义,数据按行存储,在实际的物理块中,数据的将按下列图示的方式存储:
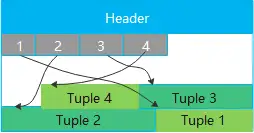
优势很明显,点查场景下,直接就能索引到行存某行元组的位置,点查性能好。数据库中的系统表就是行存表,对于用户的一些对点查性能要求高或者频繁更新的小表,都推荐用行存表。
列存表(column-store)
AP场景下,常常需要对某列进行批量查询来做分析业务,这时候采用行存的话就会把所有列都读出来产生冗余IO, 同时AP场景下的表数据量往往很大,行存表压缩暂未商用,使用行存表也会导致占用空间过大。
GaussDB(DWS)中的列存表就是针对这种场景实现的,列存表数据的实际存储示意图如下:
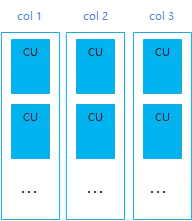
列存表将每列的数据批量存储成一个CU(Compress Unit), 能带来了很好的空间压缩与批量查询性能提升,对于一些涉及多表关联的分析类复杂查询、数据不经常更新的表,推荐使用列存表。
列存带Delta表
对于列存表,如果业务是频繁的小批量插入,那么将产生大量的小CU(单个CU里只有几百条甚至几条数据), 每个列的CU都是有压缩代价的,小CU过多将严重影响列存表的查询性能。
列存的Delta表就是针对这种场景实现的,让小批量插入的数据先存储到行存delta表,满6w后由后台autovacuum异步merge到主表CU。
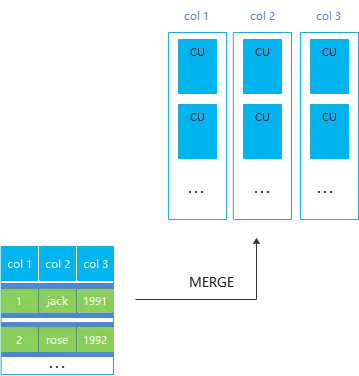
需要注意的是列存带Delta表只解决小批量入库产生的小CU问题,不解决同一个CU上的并发更新问题
HStore表
前面提到,虽然列存老Delta表解决了小批量入库产生的小CU问题,但是没有解决同一个CU上的并发更新产生的锁冲突问题。
而实时入库的场景下,需要将insert+upsert+update操作实时并发入库,数据来源于上游的其他数据库或者应用,同时要求入库后的数据要能及时查询,且对于查询的效率要求很高。
目前的列存表由于锁冲突的原因无法支持并发upsert/update入库,导致这些有需要的局点只能使用行存表,但是行存表因为格式的天然劣势,在AP查询场景下一方面性能较慢,另一方面由于压缩差导致占用了大量的磁盘空间,对用户产生额外成本。
GaussDB(DWS)中的HStore表, 在使用列存储格式尽量降低磁盘占用的同时,支持高并发的更新操作入库以及高性能的查询效率。面向对于实时入库和实时查询有较强诉求的场景,同时拥有处理传统TP场景的事务能力。
HStore表的示意图如下:
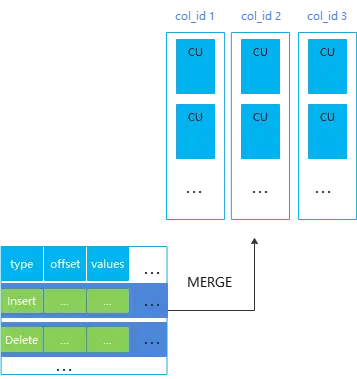
GaussDB(DWS) 中几种表类型的对比
HStore的Delta表
HStore表的实现主要依靠一张新设计的delta表以及内存并发控制机制,这里简单讲一下delta表的实现以及简单的观察delta表。
HStore的Delta表主要用于存放入库产生的Insert/Delete/Update操作,小批量Insert的数据会先进入Delta形成一条类型是I(Insert)的记录;删除会往Delta表插入一条类型是D(Delete)的记录;更新操作(Upsert与Update)会拆分成Delete + Insert,会插入一条类型X(表示由更新产生的删除)的记录以及一条类型I的记录;
(类型是U(Update)的记录由轻量化Update产生,不过当前轻量化更新默认关闭,所以不用管。)
可以看到,入库时的Upsert/Update/Delete都会转换成相应类型的记录插入的HStore的Delta表中,再结合内存并发控制机制,就能保证同一个CU上更新于删除操作不会阻塞。同时,由于小批量的插入只会在Delta表上形成一条记录,相比与列存老Delta的直接存储数据,能减少IO占用,提高MERGE效率。
HStore的Delta表 与 列存老Delta表的对比

HStore的视图与函数
当前HStore表提供了视图,可以用来观察Delta表的给类型元组数量以及Delta的膨胀情况。
select * from pgxc_get_hstore_delta_info('tableName');
同时也提供了函数可以对Delta表做轻量清理以及全量清理。
-- 轻量Merge满6万的I记录以及CU上的删除信息,持有四级锁不阻塞业务增删改查,但空间不会还给操作系统。
select hstore_light_merge('tableName');
-- 全量Merge所有记录,然后truncate清空Delta表返还空间给系统,不过持有八级锁会阻塞业务。
select hstore_full_merge('tableName');
这里做一个简单的观察实验:
1.往HStore表上批量插入一百条数据,能看到生成了一条类型是I的记录(n_i_tup 为1)
gaussdb=# create table data(a int primary key, b int);
NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "data_pkey" for table "data"
CREATE TABLE
gaussdb=# insert into data values(generate_series(1,100),1);
INSERT 0 100
gaussdb=# create table hs(a int primary key, b int)with(orientation=column, enable_hstore=on);
NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "hs_pkey" for table "hs"
CREATE TABLE
gaussdb=# insert into hs select * from data;
INSERT 0 100
gaussdb=# select * from pgxc_get_hstore_delta_info('hs'); --观察hstore表的delta表上的各类型数据
node_name | part_name | live_tup | n_i_type | n_d_type | n_x_type | n_u_type | n_m_type | data_size
-----------+---------------------+----------+----------+----------+----------+----------+----------+-----------
dn_1 | non partition table | 1 | 1 | 0 | 0 | 0 | 0 | 8192
(1 row)
2.执行hstore_full_merge后能观察到Delta表上没有元组(live_tup为0),并且Delta表的空间大小data_size是0.
gaussdb=# select hstore_full_merge('hs');
hstore_full_merge
-------------------
1
(1 row)
gaussdb=# select * from pgxc_get_hstore_delta_info('hs'); --观察hstore表的delta表上的各类型数据
node_name | part_name | live_tup | n_i_type | n_d_type | n_x_type | n_u_type | n_m_type | data_size
-----------+---------------------+----------+----------+----------+----------+----------+----------+-----------
dn_1 | non partition table | 0 | 0 | 0 | 0 | 0 | 0 | 0
(1 row)
3.执行删除,能观察到Delta表上有一条类型是D的记录(n_d_tup为1)。
gaussdb=# delete hs where a = 1;
DELETE 1
gaussdb=# select * from pgxc_get_hstore_delta_info('hs'); --观察hstore表的delta表上的各类型数据
node_name | part_name | live_tup | n_i_type | n_d_type | n_x_type | n_u_type | n_m_type | data_size
-----------+---------------------+----------+----------+----------+----------+----------+----------+-----------
dn_1 | non partition table | 1 | 0 | 1 | 0 | 0 | 0 | 8192
(1 row)
其它的操作这里不再一一尝试,感兴趣的读者可以自己下来试一下。
HStore表的简单使用实验
准备工作
当需要使用HStore表时,需要同步修改以下几个清理相关的参数默认值,否则会导致HStore表性能严重劣化。推荐的参数修改配置是:autovacuum_max_workers_hstore=3,autovacuum_max_workers=6,autovacuum=true。
并发更新实验
在列存表上插入一批数据后,开启两个会话,
1.会话1删除某一条数据,然后不结束事务:
gaussdb=# create table col(a int , b int)with(orientation=column);
CREATE TABLE
gaussdb=# insert into col select * from data;
INSERT 0 100
gaussdb=# begin;
BEGIN
gaussdb=# delete col where a = 1;
DELETE 1
2.会话2删除另一条数据,能看到会话2等待会话1,
gaussdb=# begin;
BEGIN
gaussdb=# delete col where a = 2;
会话1提交后会话2才能继续执行,这就复现了列存的CU锁问题:
3. 使用HStore表重复上面实验,能观察到会话2直接执行成功,不会锁等待。
gaussdb=# begin;
BEGIN
gaussdb=# delete hs where a = 2;
DELETE 1
压缩效率实验
1.构建一张有三百万数据的数据表data
gaussdb=# create table data( a int, b bigint, c varchar(10), d varchar(10));
CREATE TABLE
gaussdb=# insert into data values(generate_series(1,100),1,'asdfasdf','gergqer');
INSERT 0 100
gaussdb=# insert into data select * from data;
INSERT 0 100
gaussdb=# insert into data select * from data;
INSERT 0 200
---循环插入,直到数据量达到三百万
gaussdb=# insert into data select * from data;
INSERT 0 1638400
gaussdb=# select count(*) from data;
count
---------
3276800
(1 row)
2.批量导入到行存表,观察大小为223MB
gaussdb=# create table row (like data including all);
CREATE TABLE
gaussdb=# insert into row select * from data;
INSERT 0 3276800
gaussdb=# select pg_size_pretty(pg_relation_size('row'));
pg_size_pretty
----------------
223 MB
(1 row)
3.批量导入到列存表,观察大小为3.5MB
gaussdb=# create table hs(a int, b bigint, c varchar(10),d varchar(10))with(orientation= column, enable_hstore=on);
CREATE TABLE
gaussdb=# insert into hs select * from data;
INSERT 0 3276800
gaussdb=# select pg_size_pretty(pg_relation_size('hs'));
pg_size_pretty
----------------
3568 KB
(1 row)
4.总结
这个表结构比较简单,数据也都是重复数据,所以HStore表的压缩效果很好,一般情况下HStore表相比行存能有3-5倍的压缩。
批量查询性能实验
还是使用上面建的表,这里简单验证一下批量查询
1.查询行存表的第四列,耗时在4s左右
gaussdb=# explain analyze select d from data;
explain analye QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------
id | operation | A-time | A-rows | E-rows | Peak Memory | E-memory | A-width | E-width | E-costs
----+------------------------------+----------------------+---------+---------+--------------+----------+---------+---------+----------
1 | -> Streaming (type: GATHER) | 4337.881 | 3276800 | 3276800 | 32KB | | | 8 | 61891.00
2 | -> Seq Scan on data | [1571.995, 1571.995] | 3276800 | 3276800 | [32KB, 32KB] | 1MB | | 8 | 61266.00
2.查询HStore表的第四列,耗时300毫秒左右
gaussdb=# explain analyze select d from hs;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------
id | operation | A-time | A-rows | E-rows | Peak Memory | E-memory | A-width | E-width | E-costs
----+----------------------------------------+--------------------+---------+---------+----------------+----------+---------+---------+----------
1 | -> Row Adapter | 335.280 | 3276800 | 3276800 | 24KB | | | 8 | 15561.80
2 | -> Vector Streaming (type: GATHER) | 111.492 | 3276800 | 3276800 | 96KB | | | 8 | 15561.80
3 | -> CStore Scan on hs | [111.116, 111.116] | 3276800 | 3276800 | [254KB, 254KB] | 1MB | | 8 | 14936.80
3.总结
这里只验证了批量查询场景,该场景下列存以及HStore表相比行存都有很好的查询性能。但在索引点查询场景下,列存是比不上行存的,这里不再做详细对比。
HStore表注意事项
1.参数设置
HStore依赖后台常驻线程对HStore表进行MERGE清理操作,才能保证查询性能与压缩效率,所以使用HStore表务必设置相关GUC,推荐的配置如下:
autovacuum_max_workers_hstore=3
autovacuum_max_workers=6
autovacuum=true
2.并发同一行:
当前HStore并发更新同一行仍然是不支持的,其中同一行上并发update/delete操作会先等锁然后报错,同一行上的并发upsert操作会先等锁然后继续执行。由于等待开销也是会影响业务的入库性能,甚至可能产生死锁,所以需要在入库时保证不会并发更新到同一行或者同一个key。
3.索引相关
索引会占用额外的空间,同时带来的点查性能提升有限,所以HStore表只建议在需要做Upsert或者有点查(这里指唯一性与接近唯一的点查)的诉求下创建一个主键或者btree索引。
4.MERGE相关
由于HStore表依赖后台autovacuum来将操作MERGE到主表,所以入库速度不能超过MERGE速度,否则会导致delta表的膨胀,可以通过控制入库的并发来控制入库速度。同时由于Delta表本身的空间复用受oldestXmin的影响,如果有老事务存在可能会导致Delta空间复用不及时而产生膨胀。
5.UPSERT性能
HStore表虽然相比普通列存,并发upsert入库性能得到了很大提升,但相比行存还是有差距,大概只有行存的1/3。所以在不追求压缩率以及批量查询性能、只追求单点查询性能的场景下,还是推荐行存表入库。
HStore表全了解:实时入库与高效查询利器的更多相关文章
- 利用Flume将MySQL表数据准实时抽取到HDFS
转自:http://blog.csdn.net/wzy0623/article/details/73650053 一.为什么要用到Flume 在以前搭建HAWQ数据仓库实验环境时,我使用Sqoop抽取 ...
- 一次快速改写 SQL Server 高效查询的范例
原文:一次快速改写 SQL Server 高效查询的范例 最近線上系統突然出現匯出資料超過 10 筆時,查詢逾時的狀況,在仔細查找之後. 發現了問題原因,透過應用端與數據端兩邊同時調整,將查詢的效率提 ...
- 表查询语句及使用-连表(inner join-left join)-子查询
一.表的基本查询语句及方法 from. where. group by(分组).having(分组后的筛选).distinct(去重).order by(排序). limit(限制) 1.单表查询: ...
- (转)MySQL数据表中带LIKE的字符匹配查询
MySQL数据表中带LIKE的字符匹配查询 2014年07月15日09:56 百科369 MySQL数据表中带LIKE的字符匹配查询 LIKE关键字可以匹配字符串是否相等. 如果字段的值与指定的 ...
- MySQL 高效查询
在“现场加号&预约排队”项目中,“号贩子排查任务”在线下测试的时候没有问题,但是线上后,由于线上的数据量较大,导致在执行查询的时系统崩溃:后来经过查找,发现写的sql不合理,查出了许多用不到的 ...
- 天气类API调用的代码示例合集:全国天气预报、实时空气质量数据查询、PM2.5空气质量指数等
以下示例代码适用于 www.apishop.net 网站下的API,使用本文提及的接口调用代码示例前,您需要先申请相应的API服务. 全国天气预报:数据来自国家气象局,可根据地名.经纬度GPS.IP查 ...
- mysql进阶(五)数据表中带OR的多条件查询
MySQL数据表中带OR的多条件查询 OR关键字可以联合多个条件进行查询.使用OR关键字时: 条件 1) 只要符合这几个查询条件的其中一个条件,这样的记录就会被查询出来. 2) 如果不符合这些查询条件 ...
- SQL注入——知表名不知列明情景下查询数据
场景 有某些情况,可以查找到表名,但查找不到列名. MySQL < 5 或 web过滤 information_scema 详解 select `1` from (select 1,2,3,4, ...
- {MySQL的逻辑查询语句的执行顺序}一 SELECT语句关键字的定义顺序 二 SELECT语句关键字的执行顺序 三 准备表和数据 四 准备SQL逻辑查询测试语句 五 执行顺序分析
MySQL的逻辑查询语句的执行顺序 阅读目录 一 SELECT语句关键字的定义顺序 二 SELECT语句关键字的执行顺序 三 准备表和数据 四 准备SQL逻辑查询测试语句 五 执行顺序分析 一 SEL ...
- Oracle 表结构、索引以及分区信息查询
Oracle 表结构.索引以及分区信息查询 /* 获取表:*/ select table_name from user_tables; --当前用户的表 select table_name from ...
随机推荐
- 基于开源的 ChatGPT Web UI 项目,快速构建属于自己的 ChatGPT 站点
作为一个技术博主,了不起比较喜欢各种折腾,之前给大家介绍过 ChatGPT 接入微信,钉钉和知识星球(如果没看过的可以翻翻前面的文章),最近再看开源项目的时候,发现了一个 ChatGPT Web UI ...
- 端口转发、Http Tunnel、内网穿透
原文链接:https://www.yuque.com/tec-nine/architecture/mgxc71 SSH 命令帮助 命令行选项有: -a 禁止转发认证代理的连接. -A 允许转发认证代理 ...
- ggplot2图形可视化应用集锦
数据可视化就是将我们从数据中探索的信息与图形要素对应起来的过程.数据可视化,先要理解数据,再去掌握可视化的方法,这样才能实现高效的数据可视化.数据可视化技术的基本思想,是将数据库中每一个数据项作为单个 ...
- 大语言模型快速推理: 在 Habana Gaudi2 上推理 BLOOMZ
本文将展示如何在 Habana Gaudi2 上使用 Optimum Habana.Optimum Habana 是 Gaudi2 和 Transformers 库之间的桥梁.本文设计并实现了一个大模 ...
- kubernetes核心实战(五)--- StatefulSets
7.StatefulSets StatefulSet 是用来管理有状态应用的工作负载 API 对象. StatefulSet 用来管理 Deployment 和扩展一组 Pod,并且能为这些 Pod ...
- 【LeetCode回溯算法#extra01】集合划分问题【火柴拼正方形、划分k个相等子集、公平发饼干】
火柴拼正方形 https://leetcode.cn/problems/matchsticks-to-square/ 你将得到一个整数数组 matchsticks ,其中 matchsticks[i] ...
- okio中数据存储的基本单位Segment
1.Segment是Buffer缓冲区存储数据的基本单位,每个Segment能存储的最大字节是8192也就是8k的数据 /** The size of all segments in bytes. * ...
- 零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程。
零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程. 1.通用文本分类技术UTC介绍 本项目提供基于通用文本分类 UTC(Universal Text C ...
- MQTT-会话
MQTT会话 为什么需要会话 假如有以下场景,客户端A发送消息到服务端,服务端转发给客户端B,如果这个时候服务端和客户端B的网络连接断开,那么就无法保证消息到达,并且客户端A不知道B连接断开,还会 ...
- 【Ubuntu】3.配置下载源与更新
在 Ubuntu 中,更改下载源可以加快下载速度.以下是更改 Ubuntu 下载源的步骤: 方法一: 备份之前的 sources.list 文件: sudo cp /etc/apt/sources.l ...