hive操作 -- zeppelin安装及配置
当时写hive用的是zeppelin,这个工具可以直接在页面上写sql语句,操作服务器上的hive库,还挺方便的
通过zeppelin实现hive的查询结果的可视化
启动过程中会报错:User: tong is not allowed to impersonate root
修改hadoop的配置文件core-site.xml,增加如下内容:
其中livy修改成自己的用户名
<property>
<name>hadoop.proxyuser.livy.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.livy.hosts</name>
<value>*</value>
</property>
下载好了以后拖拽到用户的home文件夹下打开终端cd到用户home文件夹下,解压缩
tar -zxvf zeppelin-0.7.3-bin-all.tgz
↓
进入到zeppelin的配置文件夹下
cd ~/zeppelin-0.7.3-bin-all/conf
编辑配置文件
cp zeppelin-env.sh.template zeppelin-env.sh
vi zeppelin-env.sh
在文件末尾添加代码段
JAVA_HOME为你的Java jdk路径
HADOOP_CONF_DIR是你的Hadoop的配置文件目录
(Hadoop2的配置文件目录一般在安装目录的etc的Hadoop目录下)
export JAVA_HOME=/usr/java/jdk1.7.0_71/
export HADOOP_CONF_DIR=~/hadoop-2.5.2/etc/hadoop
↓
如果hive没有登录用户则需在配置文件中添加,并把你的hive的配置文件 hive-site.xml 复制到zeppelin的conf配置文件夹下,hive的安装可以看之前的文章
cd ~/apache-hive-0.13.1-bin/conf
gedit hive-site.xml
添加代码
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hadoop</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
</property>
其中 hadoop 是新建的用户名和密码
cp ~/apache-hive-0.13.1-bin/conf/hive-site.xml ~/zeppelin-0.7.3-bin-all/conf
↓
打开一个单独的终端,进入hive的安装目录(我这里是在apache-hive-0.13.1-bin目录),开启metastore和hiveserver2服务,关闭服务时直接 Ctrl+c 。开启的时候可能会有些延时。
./bin/hive --service metastore &
./bin/hiveserver2 &
↓
打开一个新的终端,进入zeppelin的bin目录下,开启程序
cd ~/zeppelin-0.7.3-bin-all/bin
./zeppelin-daemon.sh start 开启程序
./zeppelin-daemon.sh stop 停止程序
./zeppelin-daemon.sh restart 重启程序
↓
打开浏览器,输入URL ,出现下图界面则为成功,请确保你的电脑可以联网,并且8080端口没有被占用,如果被占用可以更改配置目录conf下,zeppelin-env.sh的参数
http://localhost:8080/
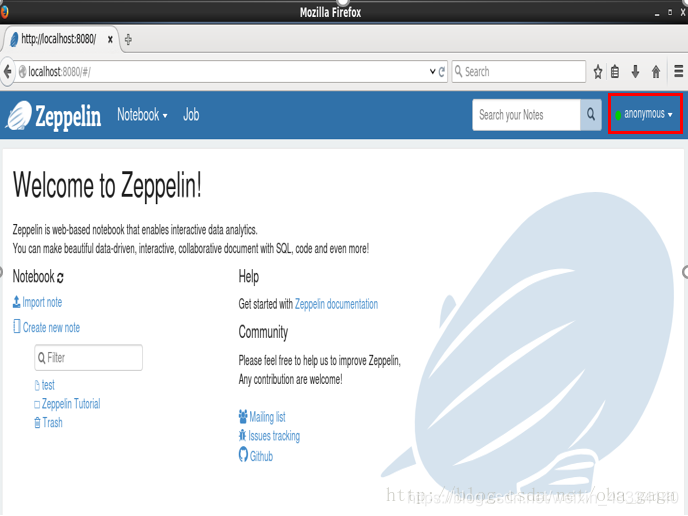
↓
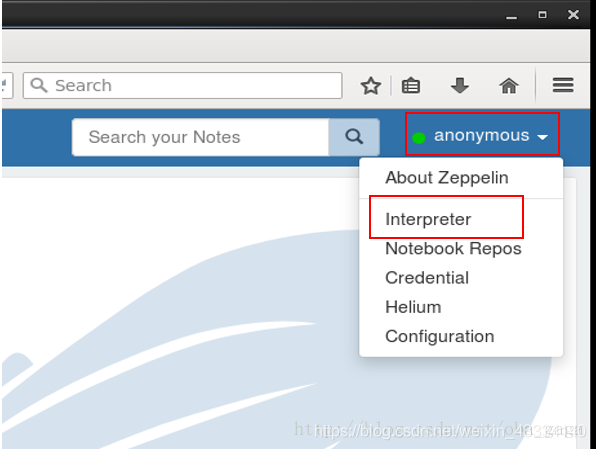
编辑通用编辑器 jdbc
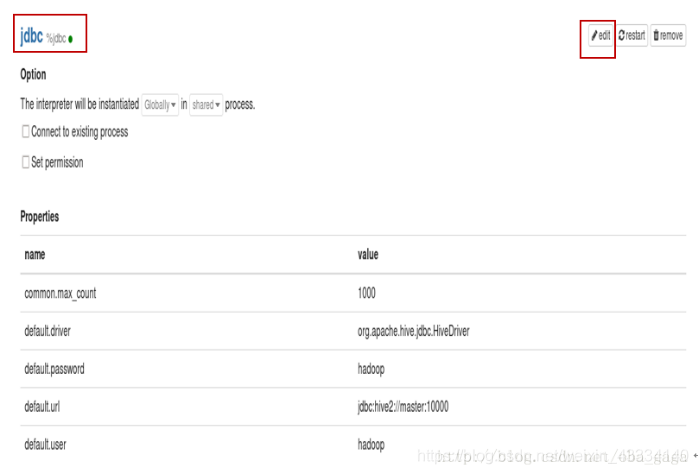
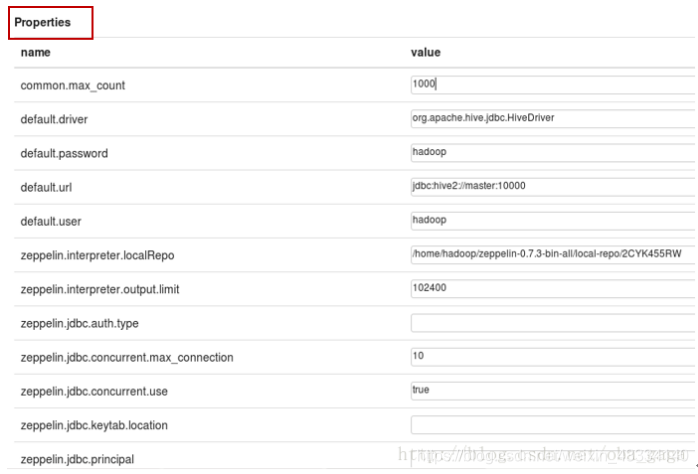
需要修改的地方
default.driver org.apache.hive.jdbc.HiveDriver
default.url jdbc:hive2://master:10000
default.user 你的hive的用户名
default.password 你的hive的用户密码
添加两个依赖包
org.apache.hadoop:hadoop-common:2.6.0(注意修改成自己Hadoop的版本)
org.apache.hive:hive-jdbc:0.14.0(注意修改成自己hive的版本)
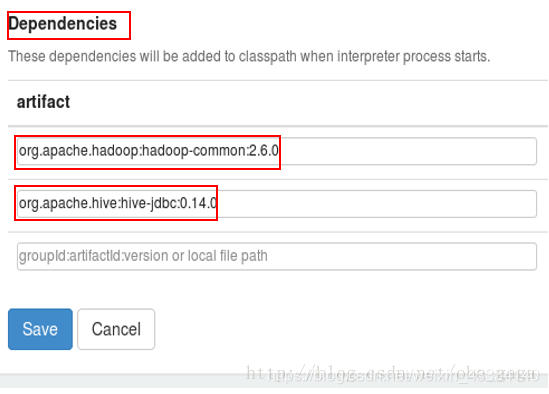
注意Hadoop和hibe的版本
修改完以后保存并重启一下jdbc,可能会有些延迟。
启动完成后如果出先权限报错。查看hdfs dfs -ls / 修改文件权限
以后每次进入程序
1、打开Hadoop
start-all.sh 开启
stop-all.sh 关闭
2、进入hive安装目录,开启hiveserver2服务
./bin/hiveserver2 &
ctrl+c 关闭
3、进入zeppelin安装目录,运行zeppelin程序
./zeppelin-daemon.sh start
./zeppelin-daemon.sh stop
关机前把程序全部关闭。
hive操作 -- zeppelin安装及配置的更多相关文章
- Hive 教程(一)-安装与配置解析
安装就安装 ,不扯其他的 hive 依赖 在 hive 安装前必须具备如下条件 1. 一个可连接的关系型数据库,如 Mysql,postgresql 等,用于存储元数据 2. hadoop,并启动 h ...
- zeppelin安装及配置
1.下载安装包,zepplin下载地址:http://zeppelin.apache.org/download.html #创建解压目录 mkdir -p /opt/software #解压 tar ...
- 安装和配置hive
1.上传hive.mysql.mysql driver到服务器/mnt目录下: [root@chavin mnt]# ll mysql-5.6.24-linux-glibc2.5-x86_64.tar ...
- 【Hive一】Hive安装及配置
Hive安装及配置 下载hive安装包 此处以hive-0.13.1-cdh5.3.6版本的为例,包名为:hive-0.13.1-cdh5.3.6.tar.gz 解压Hive到安装目录 $ tar - ...
- Ubuntu16.04下Hive的安装与配置
一.系统环境 os : Ubuntu 16.04 LTS 64bit jdk : 1.8.0_161 hadoop : 2.6.4mysql : 5.7.21 hive : 2.1.0 在配置hive ...
- CentOS6安装各种大数据软件 第八章:Hive安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- Hive安装、配置和使用
Hive概述 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能. Hive本质是:将HQL转化成MapReduce程序. Hive处理的数据存储 ...
- Spark2.0集成Hive操作的相关配置与注意事项
前言 已完成安装Apache Hive,具体安装步骤请参照,Linux基于Hadoop2.8.0集群安装配置Hive2.1.1及基础操作 补充说明 Hive中metastore(元数据存储)的三种方式 ...
- 基于Hadoop集群搭建Hive安装与配置(yum插件安装MySQL)---linux系统《小白篇》
用到的安装包有: apache-hive-1.2.1-bin.tar.gz mysql-connector-java-5.1.49.tar.gz 百度网盘链接: 链接:https://pan.baid ...
- 本地电脑安装和配置Redis操作客户端
下载需要的文件:http://pan.baidu.com/s/1gdfQePl 把这个下载下来解压就可以了,如图所示 第一步(配置本地服务) 点击run这个DOS执行命令 因为是自己的电脑测试 ...
随机推荐
- 关于elementUI的select组件回显问题
最近接受了一个后台项目,需求是这样的,点击表单项,弹出的弹出层显示该表单项目的信息.但是回显的时候,关于弹出层中的级联显示有问题,如图: 回显结果为: 回显代码为: 弹框为: 我就不明白了,分明分公司 ...
- 2023/4/18 SCRUM个人博客
1.我昨天的任务 初步学习dlib的安装,了解dlib的基础组件 2.遇到了什么困难 对pandas库了解不到位,需要学习其中的基础 3.我今天的任务 初步了解了pandas库,对series和dat ...
- SQL提高查询性能的几种方式
创建索引,提高性能 索引可以极大地提高查询性能,其背后的原理: 索引是的数据库引擎能够快速的找到表中的数据,它们类似于书籍的目录,使得你不需要逐页查找所需要的信息 索引能够帮助数据库引擎直接定位到所需 ...
- Apache COC闪电演讲总结【OSGraph】
大家能看到我最近一直在折腾与OSGraph这个产品相关的事情,之前在文章<妙用OSGraph:发掘GitHub知识图谱上的开源故事>中向大家阐述过这个产品的设计理念和应用价值.比方说以下问 ...
- 如何在Windows10电脑上打开3D建模STL文件
相关: https://www.bilibili.com/video/BV1gD4y1h7tj/
- 很好用的python游戏环境(续):强化学习算法走迷宫游戏环境(导航问题 navigation):分享一个python语言的迷宫游戏环境
相关: 很好用的python游戏环境:强化学习算法走迷宫游戏环境(导航问题 navigation):分享一个python语言的迷宫游戏环境 前文分享了一个python下的maze游戏环境,本文再给出一 ...
- tensorflow_probability.python.bijectors的一些使用
网上见到一个TensorFlow的代码,没见过这个形式的,是概率编程的代码: # coding=utf-8 # Copyright 2020 The TF-Agents Authors. # # Li ...
- python语言:将多张图片压成一段视频——利用opencv-python库实现
相关代码例子参见: All_finished_Demo.py ========================================= 这里将的功能就是用python语言实现将多张照片压成一 ...
- C# 导出表格时表头优化思路
众所周知 众所周知,如果使用DataTable.一般的思路是这么写的 var exprotData = new DataTable("Datas"); exprotData.Col ...
- vue&element项目实战 之element使用&用户&字典模块实现
6.用户模块 用户模块api import request from '@/utils/request' export function login(data) { return request({ ...