hive操作 -- zeppelin安装及配置
当时写hive用的是zeppelin,这个工具可以直接在页面上写sql语句,操作服务器上的hive库,还挺方便的
通过zeppelin实现hive的查询结果的可视化
启动过程中会报错:User: tong is not allowed to impersonate root
修改hadoop的配置文件core-site.xml,增加如下内容:
其中livy修改成自己的用户名
<property>
<name>hadoop.proxyuser.livy.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.livy.hosts</name>
<value>*</value>
</property>
下载好了以后拖拽到用户的home文件夹下打开终端cd到用户home文件夹下,解压缩
tar -zxvf zeppelin-0.7.3-bin-all.tgz
↓
进入到zeppelin的配置文件夹下
cd ~/zeppelin-0.7.3-bin-all/conf
编辑配置文件
cp zeppelin-env.sh.template zeppelin-env.sh
vi zeppelin-env.sh
在文件末尾添加代码段
JAVA_HOME为你的Java jdk路径
HADOOP_CONF_DIR是你的Hadoop的配置文件目录
(Hadoop2的配置文件目录一般在安装目录的etc的Hadoop目录下)
export JAVA_HOME=/usr/java/jdk1.7.0_71/
export HADOOP_CONF_DIR=~/hadoop-2.5.2/etc/hadoop
↓
如果hive没有登录用户则需在配置文件中添加,并把你的hive的配置文件 hive-site.xml 复制到zeppelin的conf配置文件夹下,hive的安装可以看之前的文章
cd ~/apache-hive-0.13.1-bin/conf
gedit hive-site.xml
添加代码
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hadoop</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
</property>
其中 hadoop 是新建的用户名和密码
cp ~/apache-hive-0.13.1-bin/conf/hive-site.xml ~/zeppelin-0.7.3-bin-all/conf
↓
打开一个单独的终端,进入hive的安装目录(我这里是在apache-hive-0.13.1-bin目录),开启metastore和hiveserver2服务,关闭服务时直接 Ctrl+c 。开启的时候可能会有些延时。
./bin/hive --service metastore &
./bin/hiveserver2 &
↓
打开一个新的终端,进入zeppelin的bin目录下,开启程序
cd ~/zeppelin-0.7.3-bin-all/bin
./zeppelin-daemon.sh start 开启程序
./zeppelin-daemon.sh stop 停止程序
./zeppelin-daemon.sh restart 重启程序
↓
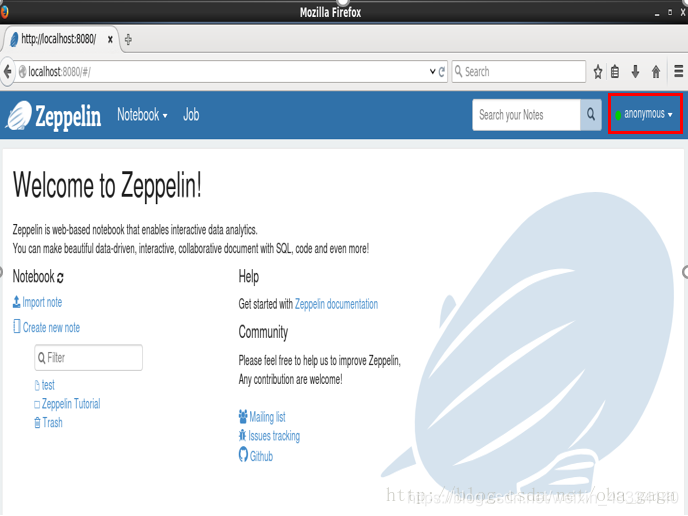
打开浏览器,输入URL ,出现下图界面则为成功,请确保你的电脑可以联网,并且8080端口没有被占用,如果被占用可以更改配置目录conf下,zeppelin-env.sh的参数
http://localhost:8080/
↓
编辑通用编辑器 jdbc
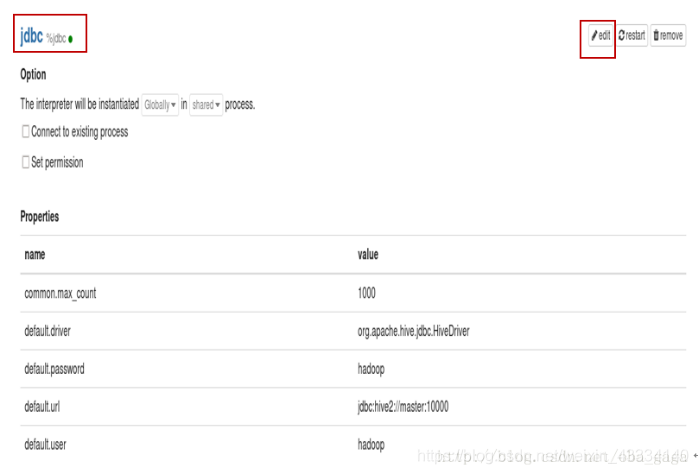
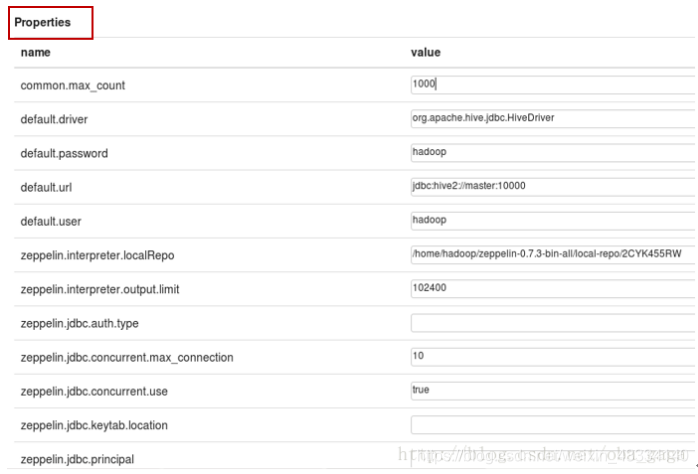
需要修改的地方
default.driver org.apache.hive.jdbc.HiveDriver
default.url jdbc:hive2://master:10000
default.user 你的hive的用户名
default.password 你的hive的用户密码
添加两个依赖包
org.apache.hadoop:hadoop-common:2.6.0(注意修改成自己Hadoop的版本)
org.apache.hive:hive-jdbc:0.14.0(注意修改成自己hive的版本)
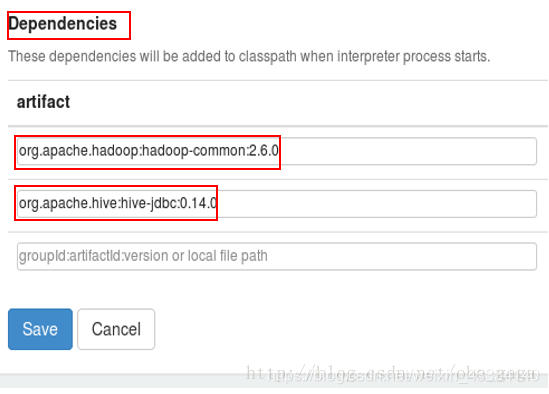
注意Hadoop和hibe的版本
修改完以后保存并重启一下jdbc,可能会有些延迟。
启动完成后如果出先权限报错。查看hdfs dfs -ls / 修改文件权限
以后每次进入程序
1、打开Hadoop
start-all.sh 开启
stop-all.sh 关闭
2、进入hive安装目录,开启hiveserver2服务
./bin/hiveserver2 &
ctrl+c 关闭
3、进入zeppelin安装目录,运行zeppelin程序
./zeppelin-daemon.sh start
./zeppelin-daemon.sh stop
关机前把程序全部关闭。
hive操作 -- zeppelin安装及配置的更多相关文章
- Hive 教程(一)-安装与配置解析
安装就安装 ,不扯其他的 hive 依赖 在 hive 安装前必须具备如下条件 1. 一个可连接的关系型数据库,如 Mysql,postgresql 等,用于存储元数据 2. hadoop,并启动 h ...
- zeppelin安装及配置
1.下载安装包,zepplin下载地址:http://zeppelin.apache.org/download.html #创建解压目录 mkdir -p /opt/software #解压 tar ...
- 安装和配置hive
1.上传hive.mysql.mysql driver到服务器/mnt目录下: [root@chavin mnt]# ll mysql-5.6.24-linux-glibc2.5-x86_64.tar ...
- 【Hive一】Hive安装及配置
Hive安装及配置 下载hive安装包 此处以hive-0.13.1-cdh5.3.6版本的为例,包名为:hive-0.13.1-cdh5.3.6.tar.gz 解压Hive到安装目录 $ tar - ...
- Ubuntu16.04下Hive的安装与配置
一.系统环境 os : Ubuntu 16.04 LTS 64bit jdk : 1.8.0_161 hadoop : 2.6.4mysql : 5.7.21 hive : 2.1.0 在配置hive ...
- CentOS6安装各种大数据软件 第八章:Hive安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- Hive安装、配置和使用
Hive概述 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能. Hive本质是:将HQL转化成MapReduce程序. Hive处理的数据存储 ...
- Spark2.0集成Hive操作的相关配置与注意事项
前言 已完成安装Apache Hive,具体安装步骤请参照,Linux基于Hadoop2.8.0集群安装配置Hive2.1.1及基础操作 补充说明 Hive中metastore(元数据存储)的三种方式 ...
- 基于Hadoop集群搭建Hive安装与配置(yum插件安装MySQL)---linux系统《小白篇》
用到的安装包有: apache-hive-1.2.1-bin.tar.gz mysql-connector-java-5.1.49.tar.gz 百度网盘链接: 链接:https://pan.baid ...
- 本地电脑安装和配置Redis操作客户端
下载需要的文件:http://pan.baidu.com/s/1gdfQePl 把这个下载下来解压就可以了,如图所示 第一步(配置本地服务) 点击run这个DOS执行命令 因为是自己的电脑测试 ...
随机推荐
- Docker Engine在Centos下的安装
实践环境 Centos7.8 先决条件 CentOS 7.8. 必须开启 centos-extrasyum仓库源.默认是开启的,如果关闭了,需要重新开启,如下 编辑 /etc/yum.repos.d/ ...
- whk随记
金刚烷,实际上是p4把磷换成碳,然后在每两个碳之间再加一个碳,氢再补齐,由于碳都是sp3杂化,所以画出来并不对称,但实际上是对称的,一氯代物只有两种,像p4o6一样,而p4o10实际上是每个磷外面再连 ...
- 腾讯云免费申请SSL证书配置https
证书申请 1.进入腾讯云官网,在上方直接搜索SSL,搜索到后点击立即选购: 2.点击进去后选择自定义配置,加密标准选择默认的国际标准,证书种类选择域名免费版(DV),勾选同意服务条款后选择免费快速申请 ...
- 遥遥领先!鲲鹏ARM架构下国产数据同步能力大幅提升16.9倍
在上篇文章<2.6倍!WhaleTunnel客户POC实景对弈DataX>发布之后,一个客户突然向我们控诉其苦DataX久矣,因为是在信创的鲲鹏ARM CPU上运行 ,每天同步需要很长时间 ...
- RabbitMq高级特性之TTL 存活时间/过期时间 通俗易懂 超详细 【内含案例】
RabbitMq高级特性之TTL 存活时间/过期时间 介绍 RabbitMQ支持消息的过期时间, 在消息发送时可以进行指定 RabbitMQ支持队列的过期时间, 从消息入队列开始计算, 只要超过了队列 ...
- Meissel_Lehmer模板
复杂度 \(O(n^\frac 23)\),计算 \(1\sim n\) 的素数个数 #define div(a, b) (1.0 * (a) / (b)) #define half(x) (((x) ...
- 学习SSD—day1_20240814
1.SSD的基本概念以及结构 SSD是一种以半导体(半导体闪存)作为存储介质吗,使用纯电子电路实现的存储设备. SSD硬件包括几大组成部分:主控.闪存.缓存芯片DRAM(可选,有些SSD上可能只有SR ...
- Linux信号量(3)-内核信号量
概念 Linux内核的信号量在概念和原理上和用户态的System V的IPC机制信号量是相同的,不过他绝不可能在内核之外使用,因此他和System V的IPC机制信号量毫不相干. 如果有一个任务想要获 ...
- 2024-08-17:用go语言,给定一个从0开始的整数数组nums和一个整数k, 每次操作可以删除数组中的最小元素。 你的目标是通过这些操作,使得数组中的所有元素都大于或等于k。 请计算出实现这个目
2024-08-17:用go语言,给定一个从0开始的整数数组nums和一个整数k, 每次操作可以删除数组中的最小元素. 你的目标是通过这些操作,使得数组中的所有元素都大于或等于k. 请计算出实现这个目 ...
- dfs剪枝与优化
搜索树 剪枝方法 1.优化搜索顺序 2.排除等效冗余 3.可行性 4.最优性(估价) 5.记忆化(树形不会重复计算时不需要) A.针对每个维度边界信息缩放.推倒 B.计算未来最少花费 C.结合各维度的 ...