【K8S系列】快速初始化⼀个最⼩集群
序言
走得最慢的人,只要不丧失目标,也比漫无目的地徘徊的人走得快。
文章标记颜色说明:
- 黄色:重要标题
- 红色:用来标记结论
- 绿色:用来标记一级重要
- 蓝色:用来标记二级重要
希望这篇文章能让你不仅有一定的收获,而且可以愉快的学习,如果有什么建议,都可以留言和我交流
写在前面
k8s作为⼀个相对⽐较复杂的系统,它有⼀定的⼊⻔⻔槛,我曾浏览它的⽂档很多次,光是在安装的环节上就耗费很久,劝退指数极⾼,但是我们不需要⼀开始就花费很多的时间从安装开始接触它
所以我们可以借⽤Docker-Desktop快速启动⼀个本地化最⼩集群,能让我们快速上⼿演练,随着对k8s的理解加深,安装的部分也就迎刃⽽解了。
1 安装
打开Docker-desktop,进⼊设置,可以看到有kubernetes选项,注意不同的docker版本,这⾥的k8s版本也有区别,
你可以直接点击Enable的话,等一会,如果成功的话,就直接安装就行了,安装成功,可以看到这一个信息
安装成功
kubectl get nodes
不成功情况
如果不成功,⼤概率因为k8simage拉取问题,导致是⽆法启动的,所以这⾥要先解决镜像
可以从国内镜像源拉取,然后修改镜像名称,这样就可以了
⽐如这台电脑,⿊苹果由于系统版本10.15.7,⽀持的docker-desktop版本⽐较⽼⼀点,所以这⾥的k8s版本是v1.24.0,
修改镜像源
下⾯就可以通过写好的脚本从阿⾥云拉取镜像,注意替换你的k8s版本,关于etcd,coredns的版本可以查⼀下ChatGPT,让它快速告诉你指定k8s对应的这两者的版本,或者保持不动,因为理论上这两个基础组件在1.24和1.25变化不⼤的,应该可以兼容:
- #!/bin/bash
- set -e
- KUBE_VERSION=v1.24.0
- KUBE_PAUSE_VERSION=3.5
- ETCD_VERSION=3.4.13-0
- COREDNS_VERSION=1.8.0
- GCR_URL=k8s.gcr.io
- ALIYUN_URL=registry.cn-hangzhou.aliyuncs.com/google_containers
- # get images
- images=(kube-proxy:${KUBE_VERSION}
- kube-scheduler:${KUBE_VERSION}
- kube-controller-manager:${KUBE_VERSION}
- kube-apiserver:${KUBE_VERSION}
- pause:${KUBE_PAUSE_VERSION}
- etcd:${ETCD_VERSION}
- coredns:${COREDNS_VERSION})
- for imageName in ${images[@]} ; do
- docker pull $ALIYUN_URL/$imageName
- docker tag $ALIYUN_URL/$imageName $GCR_URL/$imageName
- docker rmi $ALIYUN_URL/$imageName
- done
- # show images
- docker images

执⾏等待拉取完毕后检查⼀下,然后就可以点击Enable了,需要等待⼏分钟。
K8S显⽰运⾏成功后,你可以在shell中运⾏kubectl命令查看节点状态:
kubectl get nodes
2 测试
部署Nginx
可以看到⼀个单节点的集群就运⾏起来了,下⾯我们简单跑⼀个development容器看⼀下集群⼯作状态是否正常,这⾥可以先不管这些yaml⽂件描述的什么,
部署 Deployment
可以使用Kubernetes来部署Nginx。以下是一个简单的Deployment示例:
- apiVersion: apps/v1
- kind: Deployment
- metadata:
- name: nginx-deployment
- spec:
- replicas: 1
- selector:
- matchLabels:
- app: nginx
- template:
- metadata:
- labels:
- app: nginx
- spec:
- containers:
- - name: nginx
- image: nginx:latest
- ports:
- - containerPort: 80
- - containerPort: 443
解释一下上述的YAML文件:
kind: Deployment表示创建一个Deployment。metadata.name:指定Deployment的名称。spec.replicas:设置replica数量为1。selector.matchLabels:定义了应该匹配哪些Pod,使用app: nginx标签匹配。template.metadata.labels:为此Deployment创建一个独立的Pod。spec.containers:定义了一个名为nginx的容器,在此容器中运行Nginx镜像。ports:将容器的80公开。
执行以下命令创建Deployment:
kubectl apply -f deployment.yaml
在Kubernetes中使用
kubectl get deployments命令可以看到Deployment已经成功创建了。我们还可以使用以下命令查看Pod运行状态:
kubectl get pods
如果一切正常,你应该能够看到类似下面的输出:
- NAME READY STATUS RESTARTS AGE
- nginx-deployment-6b67fd5895-p8qs8 1/1 Running 0 25s
部署service
现在,Nginx已经在Kubernetes中以Deployment的方式部署好了。如果需要通过外部IP访问Nginx服务,还需要创建一个Service。
可以通过创建一个Service将Nginx服务暴露给集群外部IP。
以下是一个简单的Service示例,将Nginx Service暴露的端口设置为NodePort类型,
使用NodePort类型的Service可以将集群内部的服务端口映射到集群外部的一个随机端口上:
- apiVersion: v1
- kind: Service
- metadata:
- name: nginx-service
- spec:
- selector:
- app: nginx
- ports:
- - name: http
- protocol: TCP
- port: 80
- targetPort: 80
- nodePort: 30001
- type: NodePort
解释一下上述的YAML文件:
kind: Service表示创建一个Service。metadata.name:指定Service的名称。spec.selector:将Service绑定到定义了app: nginx标签的Pod列表。spec.ports:定义了Nginx服务的端口信息。type: NodePort表示Service类型为NodePort,将指定的端口暴露给集群外部IP以供访问。
执行以下命令创建Service:
kubectl apply -f service.yaml
现在,我们可以通过以下命令查看创建的Service:
kubectl get services
如果一切正常,你应该能够看到类似下面的输出:
- NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
- nginx-service NodePort 10.108.90.45 <none> 80:30001/TCP
在上面的输出结果中,
30001端口对应着Nginx的HTTP端口,如果你使用的是云服务提供商的集群,可以找到具体的EXTERNAL-IP地址,然后在浏览器中输入
EXTERNAL-IP:30001来访问Nginx服务。
如果你使用的是本地单节点的集群,可以在本地使用
localhost:30001访问Nginx服务。
完整脚本:
- apiVersion: apps/v1
- kind: Deployment
- metadata:
- name: nginx-deployment
- spec:
- replicas: 1
- selector:
- matchLabels:
- app: nginx
- template:
- metadata:
- labels:
- app: nginx
- spec:
- containers:
- - name: nginx
- image: nginx:latest
- ports:
- - containerPort: 80
- - containerPort: 443
- ---
- apiVersion: v1
- kind: Service
- metadata:
- name: nginx-service
- spec:
- selector:
- app: nginx
- ports:
- - name: http
- protocol: TCP
- port: 80
- targetPort: 80
- nodePort: 30001
- type: NodePort
执行命令
kubectl apply -f nginx.yml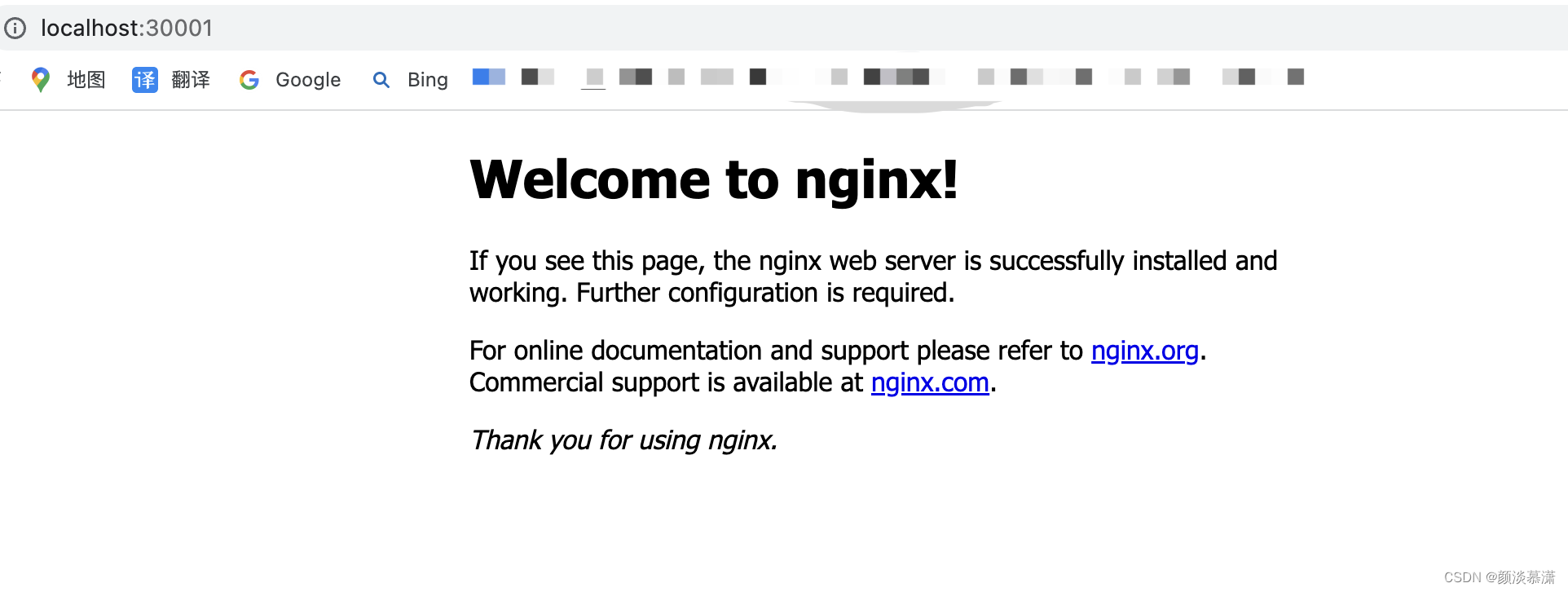
图书推荐
图书名称:《ChatGPT时代:ChatGPT全能应用一本通》

内容简介
本书从ChatGPT等自然语言大模型基础知识讲起,重点介绍了ChatGPT等语言大模型在生活中的实际应用,让每一个人都能了解未来的生活和工作。
本书分为16章,涵盖的主要内容有人工智能、OpenAI、ChatGPT的介绍、ChatGPT的使用技巧,向大家展现ChatGPT在学术教育、商业管理、新媒体、办公、求职、法律、电商等不同领域的应用,以及ChatGPT当下的问题、大模型的未来。
本书通俗易懂,用最简单的语言解释人工智能的入门知识,案例丰富,实用性强,适合每一个想要了ChatGPT等自然语言处理大模型的读者和进阶爱好者阅读,也适合想要通过API打造新时代语言模型应用的开发者。
作者简介
江涵丰,10年科技行业从业者,科技/人工智能领域知名自媒体人。北美工商管理学硕士,获麻省理工人工智能与商业战略相关认证,注册供应链管理师。曾是硅谷科技企业运营管理层,后担任前亚洲第一科技展会CES Asia项目主管,拥有丰富的北美与国内科技行业市场研究、运营管理、数字营销等领域的理论基础和实战经验。
等不及的小伙伴。可以点击下方链接先睹为快
参与方式
图书数量:本次送出 3 本 !!!️️️
活动时间:截止到 2023-05-16 12:00:00抽奖方式:
- 2本,留言+该留言论赞数的前两名各获得一本!
- 1本,评论区随机挑选一位小伙伴送书一本!
- 留言内容:“时间永远是旁观者,所有的过程和结果,都需要我们自己去承担。”
参与方式:关注博主、点赞、收藏,评论区留言
中奖名单
获奖名单
中奖名单:请关注博主动态
名单公布时间:2023-05-16 下午
中奖用户:
【评论点赞前2名】
1.[30]几分醉意.@几分醉意.️️️
1.[29]陈老老老板@陈老老老板️️
【随机抽取】
3.Anitalin00@Anitalin00️
恭喜以上中奖的小伙伴,请及时联系博主!!为防止错过中奖信息,可根据文章底部信息添加博主,添加时请备注csdn-[昵称]


微信名片

【K8S系列】快速初始化⼀个最⼩集群的更多相关文章
- kubernetes(K8S)快速安装与配置集群搭建图文教程
kubernetes(K8S)快速安装与配置集群搭建图文教程 作者: admin 分类: K8S 发布时间: 2018-09-16 12:20 Kubernetes是什么? 首先,它是一个全新的基于容 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- mongo 3.4分片集群系列之三:搭建分片集群--哈希分片 + 安全
这个系列大致想跟大家分享以下篇章: 1.mongo 3.4分片集群系列之一:浅谈分片集群 2.mongo 3.4分片集群系列之二:搭建分片集群--哈希分片 3.mongo 3.4分片集群系列之三:搭建 ...
- 简单了解一下K8S,并搭建自己的集群
距离上次更新已经有一个月了,主要是最近工作上的变动有点频繁,现在才暂时稳定下来.这篇博客的本意是带大家从零开始搭建K8S集群的.但是我后面一想,如果是我看了这篇文章,会收获什么?就是跟着步骤一步一走吗 ...
- K8s 实践 | 如何解决多租户集群的安全隔离问题?
作者 | 匡大虎 阿里巴巴技术专家 导读:如何解决多租户集群的安全隔离问题是企业上云的一个关键问题,本文主要介绍 Kubernetes 多租户集群的基本概念和常见应用形态,以及在企业内部共享集群的业 ...
- lvs+keepalived部署k8s v1.16.4高可用集群
一.部署环境 1.1 主机列表 主机名 Centos版本 ip docker version flannel version Keepalived version 主机配置 备注 lvs-keepal ...
- Centos7.6部署k8s v1.16.4高可用集群(主备模式)
一.部署环境 主机列表: 主机名 Centos版本 ip docker version flannel version Keepalived version 主机配置 备注 master01 7.6. ...
- 用Docker swarm快速部署Nebula Graph集群
用Docker swarm快速部署Nebula Graph集群 一.前言 本文介绍如何使用 Docker Swarm 来部署 Nebula Graph 集群. 二.nebula集群搭建 2.1 环境准 ...
- 使用kubeadm初始化IPV4/IPV6集群
使用kubeadm初始化IPV4/IPV6集群 图片 CentOS 配置YUM源 cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kube ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
随机推荐
- Java新特性中的Preview功能如何运行和调试
在每个Java新版本发布的特性中,都会包含一些Preview(预览)功能,这些功能主要用来给开发者体验并收集建议.所以,Preview阶段的功能并不是默认开启的. 如果想体验某个Java版本中的Pre ...
- Dubbo3应用开发—Dubbo服务管理平台DubboAdmin介绍、安装、测试
Dubbo服务管理平台 DubboAdmin的介绍 Dubbo Admin是Apache Dubbo服务治理和管理系统的一部分. Dubbo Admin提供了一套用于服务治理的Web界面,让我们可以更 ...
- 第一次git上传的完整流程
第一次git上传的完整流程 使用git简单命令上传代码push到远程仓库 + 简单介绍了一个.git文件结构. 代码上传到gitee和github流程一样的,不过你上传到github可能网不行失败,所 ...
- Python网络编程——TCP套接字通信、通信循环、链接循环、UDP通信
文章目录 基于TCP的套接字通信 加上通信循环 加上链接循环 基于UDP协议的套接字通信 基于TCP的套接字通信 以买手机的过程为例 服务端代码 import socket # 1.买手机 phone ...
- Python学习 —— 初步认知
写在前面 Python是一种流行的高级编程语言,具有简单易学.代码可读性高.应用广泛等优势.它是一种解释型语言,可以直接在终端或集成开发环境(IDE)中运行,而无需事先编译. Python的安装 Py ...
- 触发器引起的ADG备库同步错误
数据库alert日志报错ORA-16000,查看对应的trc文件,大致如下报错: *** 2020-10-27 14:09:03.340*** SESSION ID:(3340.75) 2020-10 ...
- Jackson--FastJson--XStream--代码执行&&反序列化
Jackson--FastJson--XStream--代码执行&&反序列化 Jackson代码执行 (CVE-2020-8840) 影响范围 2.0.0 <= FasterXM ...
- 21.1 Python 使用PEfile分析PE文件
PeFile模块是Python中一个强大的便携式第三方PE格式分析工具,用于解析和处理Windows可执行文件.该模块提供了一系列的API接口,使得用户可以通过Python脚本来读取和分析PE文件的结 ...
- js闭包使用之处
1.循环绑定 No Use: var lists = document.getElementsByTagName('li'); for(var i=0;i<lists.length;i& ...
- GameFramework摘录 - 1. ReferencePool
GameFramework是一个结构很优秀的Unity游戏框架,但意图似乎在构建可跨引擎的框架?对要求不高的小型个人(不专业)开发来说有些设计过度了,但其中的设计精华很值得学习. 首先来说一下其中的R ...