机器学习策略篇:详解开发集和测试集的大小(Size of dev and test sets)
在深度学习时代,设立开发集和测试集的方针也在变化。
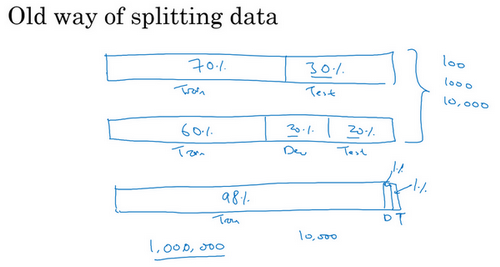
可能听说过一条经验法则,在机器学习中,把取得的全部数据用70/30比例分成训练集和测试集。或者如果必须设立训练集、开发集和测试集,会这么分60%训练集,20%开发集,20%测试集。在机器学习的早期,这样分是相当合理的,特别是以前的数据集大小要小得多。所以如果总共有100个样本,这样70/30或者60/20/20分的经验法则是相当合理的。如果有几千个样本或者有一万个样本,这些做法也还是合理的。
但在现代机器学习中,更习惯操作规模大得多的数据集,比如说有1百万个训练样本,这样分可能更合理,98%作为训练集,1%开发集,1%测试集,用\(D\)和\(T\)缩写来表示开发集和测试集。因为如果有1百万个样本,那么1%就是10,000个样本,这对于开发集和测试集来说可能已经够了。所以在现代深度学习时代,有时拥有大得多的数据集,所以使用小于20%的比例或者小于30%比例的数据作为开发集和测试集也是合理的。而且因为深度学习算法对数据的胃口很大,可以看到那些有海量数据集的问题,有更高比例的数据划分到训练集里,那么测试集呢?
要记住,测试集的目的是完成系统开发之后,测试集可以帮评估投产系统的性能。方针就是,令的测试集足够大,能够以高置信度评估系统整体性能。所以除非需要对最终投产系统有一个很精确的指标,一般来说测试集不需要上百万个例子。对于的应用程序,也许想,有10,000个例子就能给足够的置信度来给出性能指标了,也许100,000个之类的可能就够了,这数目可能远远小于比如说整体数据集的30%,取决于有多少数据。
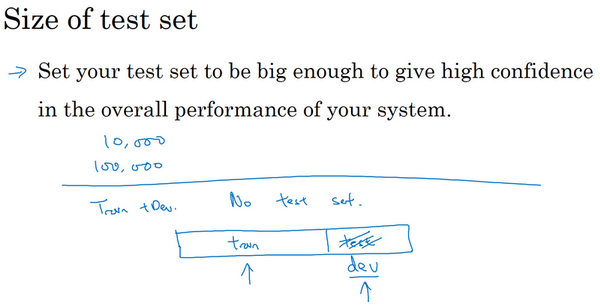
对于某些应用,也许不需要对系统性能有置信度很高的评估,也许只需要训练集和开发集。认为,不单独分出一个测试集也是可以的。事实上,有时在实践中有些人会只分成训练集和测试集,他们实际上在测试集上迭代,所以这里没有测试集,他们有的是训练集和开发集,但没有测试集。如果真的在调试这个集,这个开发集或这个测试集,这最好称为开发集。
不过在机器学习的历史里,不是每个人都把术语定义分得很清的,有时人们说的开发集,其实应该看作测试集。但如果只要有数据去训练,有数据去调试就够了。打算不管测试集,直接部署最终系统,所以不用太担心它的实际表现,觉得这也是很好的,就将它们称为训练集、开发集就好。然后说清楚没有测试集,这是不是有点不正常?绝对不建议在搭建系统时省略测试集,因为有个单独的测试集比较令安心。因为可以使用这组不带偏差的数据来测量系统的性能。但如果的开发集非常大,这样就不会对开发集过拟合得太厉害,这种情况,只有训练集和测试集也不是完全不合理的。不过一般不建议这么做。
总结一下,在大数据时代旧的经验规则,这个70/30不再适用了。现在流行的是把大量数据分到训练集,然后少量数据分到开发集和测试集,特别是当有一个非常大的数据集时。以前的经验法则其实是为了确保开发集足够大,能够达到它的目的,就是帮评估不同的想法,然后选出\(A\)还是\(B\)更好。测试集的目的是评估最终的成本偏差,只需要设立足够大的测试集,可以用来这么评估就行了,可能只需要远远小于总体数据量的30%。
所以希望本随笔能给们一点指导和建议,知道如何在深度学习时代设立开发和测试集。
机器学习策略篇:详解开发集和测试集的大小(Size of dev and test sets)的更多相关文章
- 机器学习入门06 - 训练集和测试集 (Training and Test Sets)
原文链接:https://developers.google.com/machine-learning/crash-course/training-and-test-sets 测试集是用于评估根据训练 ...
- 斯坦福大学公开课机器学习:advice for applying machine learning | model selection and training/validation/test sets(模型选择以及训练集、交叉验证集和测试集的概念)
怎样选用正确的特征构造学习算法或者如何选择学习算法中的正则化参数lambda?这些问题我们称之为模型选择问题. 在对于这一问题的讨论中,我们不仅将数据分为:训练集和测试集,而是将数据分为三个数据组:也 ...
- sklearn获得某个参数的不同取值在训练集和测试集上的表现的曲线刻画
from sklearn.svm import SVC from sklearn.datasets import make_classification import numpy as np X,y ...
- 随机切分csv训练集和测试集
使用numpy切分训练集和测试集 觉得有用的话,欢迎一起讨论相互学习~Follow Me 序言 在机器学习的任务中,时常需要将一个完整的数据集切分为训练集和测试集.此处我们使用numpy完成这个任务. ...
- sklearn学习3----模型选择和评估(1)训练集和测试集的切分
来自链接:https://blog.csdn.net/zahuopuboss/article/details/54948181 1.sklearn.model_selection.train_test ...
- sklearn——train_test_split 随机划分训练集和测试集
sklearn——train_test_split 随机划分训练集和测试集 sklearn.model_selection.train_test_split随机划分训练集和测试集 官网文档:http: ...
- Sklearn-train_test_split随机划分训练集和测试集
klearn.model_selection.train_test_split随机划分训练集和测试集 官网文档:http://scikit-learn.org/stable/modules/gener ...
- csv数据集按比例分割训练集、验证集和测试集,即分层抽样的方法
一.一种比较通俗理解的分割方法 1.先读取总的csv文件数据: import pandas as pd data = pd.read_csv('D:\BaiduNetdiskDownload\weib ...
- 将dataframe分割为训练集和测试集两部分
data = pd.read_csv("./dataNN.csv",',',error_bad_lines=False)#我的数据集是两列,一列字符串,一列为0,1的labelda ...
- 用python制作训练集和测试集的图片名列表文本
# -*- coding: utf-8 -*- from pathlib import Path #从pathlib中导入Path import os import fileinput import ...
随机推荐
- KingbaseESV8R6普通用户无权限执行vacuum
背景 数据库日志有如下提示: WARNING: skipping "pivot_t1" --- only table or database owner can vacuum it ...
- MyBatis 简介、优缺点
40)谈谈 MyBatis Mybatis 是一个半自动化的 ORM 框架,它对 jdbc 的操作数据库的过程进行封装,使得开发者只需要专注于 SQL 语句本身,而不用去关心注册驱动,创建 conne ...
- C++设计模式 - 模板方法(Template Method)
组件协作模式: 现代软件专业分工之后的第一个结果是"框架与应用程序的划分","组件协作"模式通过晚期绑定,来实现框架与应用程序之间的松耦合,是二者之间协作时常用 ...
- #平衡树#洛谷 1110 [ZJOI2007]报表统计
题目 分析 最小值只需要开两棵平衡树,一棵维护所有元素,一棵维护相邻最小值, 对于全局最小值,对于每次插入查找前驱后继更新最小值即可, 相邻最小值,对于每个原数列的数维护它的开头和结尾是什么数, 然后 ...
- 面向OpenHarmony终端的密码安全关键技术
本文转载自 OpenHarmony TSC 官方微信公众号<峰会回顾第17期 | 面向OpenHarmony终端的密码安全关键技术> 演讲嘉宾 | 何道敬 回顾整理 | 廖 涛 排 ...
- 战“码”先锋直播预告丨如何成为一名优秀的OpenHamrony贡献者?
OpenAtom OpenHarmony(以下简称"OpenHarmony")工作委员会首度发起「OpenHarmony开源贡献者计划」,旨在鼓励开发者参与OpenHarmony开 ...
- XML文档节点导航与选择指南
XPath(XML Path Language)是XSLT标准的主要组成部分.它用于在XML文档中浏览元素和属性,提供了一种强大的定位和选择节点的方式. XPath的基本特点 代表XML路径语言: X ...
- 【FAQ】接入华为帐号服务过程中常见问题总结
华为帐号服务(Account Kit)为开发者提供简单.安全的登录授权功能,用户不必输入帐号.密码和繁琐验证,就可以通过华为帐号快速登录应用,即刻使用App.这篇文章收集了开发者们集成华为帐号服务中会 ...
- Windows Server 2008 R2之升级IE8
前言 先需求将Windows Server 2008 R2的IE8升级至IE9,需要安装系统补丁. 安装补丁 补丁包版本 KB2454826 下载地址 https://www.catalog.upda ...
- docker 应用篇————容器共享数据卷[十五]
前言 简单介绍一下多个容器间容器卷共享. 正文 先启动上一节的test:2.0 这个镜像. docker run --name test01 -it test:2.0 /bin/bash 然后 ctr ...