机器学习策略篇:详解开发集和测试集的大小(Size of dev and test sets)
在深度学习时代,设立开发集和测试集的方针也在变化。
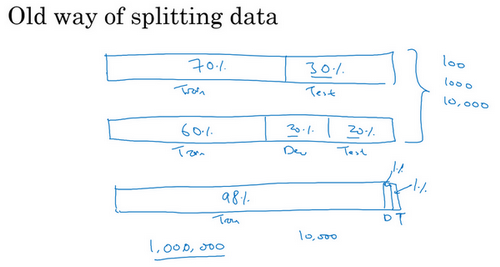
可能听说过一条经验法则,在机器学习中,把取得的全部数据用70/30比例分成训练集和测试集。或者如果必须设立训练集、开发集和测试集,会这么分60%训练集,20%开发集,20%测试集。在机器学习的早期,这样分是相当合理的,特别是以前的数据集大小要小得多。所以如果总共有100个样本,这样70/30或者60/20/20分的经验法则是相当合理的。如果有几千个样本或者有一万个样本,这些做法也还是合理的。
但在现代机器学习中,更习惯操作规模大得多的数据集,比如说有1百万个训练样本,这样分可能更合理,98%作为训练集,1%开发集,1%测试集,用\(D\)和\(T\)缩写来表示开发集和测试集。因为如果有1百万个样本,那么1%就是10,000个样本,这对于开发集和测试集来说可能已经够了。所以在现代深度学习时代,有时拥有大得多的数据集,所以使用小于20%的比例或者小于30%比例的数据作为开发集和测试集也是合理的。而且因为深度学习算法对数据的胃口很大,可以看到那些有海量数据集的问题,有更高比例的数据划分到训练集里,那么测试集呢?
要记住,测试集的目的是完成系统开发之后,测试集可以帮评估投产系统的性能。方针就是,令的测试集足够大,能够以高置信度评估系统整体性能。所以除非需要对最终投产系统有一个很精确的指标,一般来说测试集不需要上百万个例子。对于的应用程序,也许想,有10,000个例子就能给足够的置信度来给出性能指标了,也许100,000个之类的可能就够了,这数目可能远远小于比如说整体数据集的30%,取决于有多少数据。
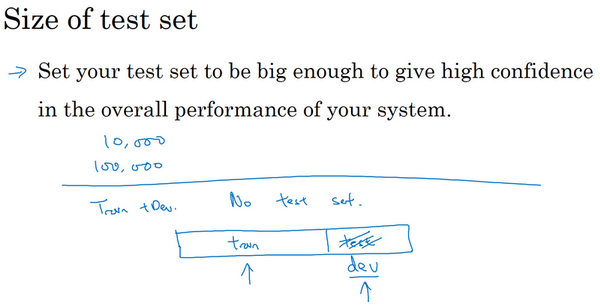
对于某些应用,也许不需要对系统性能有置信度很高的评估,也许只需要训练集和开发集。认为,不单独分出一个测试集也是可以的。事实上,有时在实践中有些人会只分成训练集和测试集,他们实际上在测试集上迭代,所以这里没有测试集,他们有的是训练集和开发集,但没有测试集。如果真的在调试这个集,这个开发集或这个测试集,这最好称为开发集。
不过在机器学习的历史里,不是每个人都把术语定义分得很清的,有时人们说的开发集,其实应该看作测试集。但如果只要有数据去训练,有数据去调试就够了。打算不管测试集,直接部署最终系统,所以不用太担心它的实际表现,觉得这也是很好的,就将它们称为训练集、开发集就好。然后说清楚没有测试集,这是不是有点不正常?绝对不建议在搭建系统时省略测试集,因为有个单独的测试集比较令安心。因为可以使用这组不带偏差的数据来测量系统的性能。但如果的开发集非常大,这样就不会对开发集过拟合得太厉害,这种情况,只有训练集和测试集也不是完全不合理的。不过一般不建议这么做。
总结一下,在大数据时代旧的经验规则,这个70/30不再适用了。现在流行的是把大量数据分到训练集,然后少量数据分到开发集和测试集,特别是当有一个非常大的数据集时。以前的经验法则其实是为了确保开发集足够大,能够达到它的目的,就是帮评估不同的想法,然后选出\(A\)还是\(B\)更好。测试集的目的是评估最终的成本偏差,只需要设立足够大的测试集,可以用来这么评估就行了,可能只需要远远小于总体数据量的30%。
所以希望本随笔能给们一点指导和建议,知道如何在深度学习时代设立开发和测试集。
机器学习策略篇:详解开发集和测试集的大小(Size of dev and test sets)的更多相关文章
- 机器学习入门06 - 训练集和测试集 (Training and Test Sets)
原文链接:https://developers.google.com/machine-learning/crash-course/training-and-test-sets 测试集是用于评估根据训练 ...
- 斯坦福大学公开课机器学习:advice for applying machine learning | model selection and training/validation/test sets(模型选择以及训练集、交叉验证集和测试集的概念)
怎样选用正确的特征构造学习算法或者如何选择学习算法中的正则化参数lambda?这些问题我们称之为模型选择问题. 在对于这一问题的讨论中,我们不仅将数据分为:训练集和测试集,而是将数据分为三个数据组:也 ...
- sklearn获得某个参数的不同取值在训练集和测试集上的表现的曲线刻画
from sklearn.svm import SVC from sklearn.datasets import make_classification import numpy as np X,y ...
- 随机切分csv训练集和测试集
使用numpy切分训练集和测试集 觉得有用的话,欢迎一起讨论相互学习~Follow Me 序言 在机器学习的任务中,时常需要将一个完整的数据集切分为训练集和测试集.此处我们使用numpy完成这个任务. ...
- sklearn学习3----模型选择和评估(1)训练集和测试集的切分
来自链接:https://blog.csdn.net/zahuopuboss/article/details/54948181 1.sklearn.model_selection.train_test ...
- sklearn——train_test_split 随机划分训练集和测试集
sklearn——train_test_split 随机划分训练集和测试集 sklearn.model_selection.train_test_split随机划分训练集和测试集 官网文档:http: ...
- Sklearn-train_test_split随机划分训练集和测试集
klearn.model_selection.train_test_split随机划分训练集和测试集 官网文档:http://scikit-learn.org/stable/modules/gener ...
- csv数据集按比例分割训练集、验证集和测试集,即分层抽样的方法
一.一种比较通俗理解的分割方法 1.先读取总的csv文件数据: import pandas as pd data = pd.read_csv('D:\BaiduNetdiskDownload\weib ...
- 将dataframe分割为训练集和测试集两部分
data = pd.read_csv("./dataNN.csv",',',error_bad_lines=False)#我的数据集是两列,一列字符串,一列为0,1的labelda ...
- 用python制作训练集和测试集的图片名列表文本
# -*- coding: utf-8 -*- from pathlib import Path #从pathlib中导入Path import os import fileinput import ...
随机推荐
- verilog之基本结构
verilog语法的基本结构 1.verilog的定义 verilog,一种硬件描述语言,致力于提高数字电路,尤其是大规模数字电路的描述规范.从描述就可以看出,这个语言和C不同,不是高级语言.但是,这 ...
- PSS:你距离NMS-free+提点只有两个卷积层 | 2021论文
论文提出了简单高效的PSS分支,仅需在原网络的基础上添加两个卷积层就能去掉NMS后处理,还能提升模型的准确率,而stop-grad的训练方法也挺有意思的,值得一看 来源:晓飞的算法工程笔记 公众号 ...
- java实战字符串1:给定两个字符串 s 和 t,判断他们的编辑距离是否为 1。
题目描述给定两个字符串 s 和 t,判断他们的间距是否为 1.(满足以下三个条件) 往 s 中插入一个字符得到 t从 s 中删除一个字符得到 t在 s 中替换一个字符得到 t 例1 输入: ab ac ...
- Scala 函数至简原则
(1)return 可以省略,Scala 会使用函数体的最后一行代码作为返回值(2)如果函数体只有一行代码,可以省略花括号(3)返回值类型如果能够推断出来,那么可以省略(:和返回值类型一起省略)(4) ...
- 【开源三方库】crypto-js加密算法库的使用方法
OpenAtom OpenHarmony(简称"OpenHarmony")三方库,是经过验证可在OpenHarmony系统上可重复使用的软件组件,可帮助开发者快速开发OpenHa ...
- Sqlite数据库联合查询及表复制等详述
外键:一般在两个表之间要建立关联时候,创建一个列创建 为外键(UserInfos-DeptId),它在另一个表必须是主键(DeptInfos-DeptId) 元素约束:主键约束:主要区别内容相同的行, ...
- openGauss事务机制中MVCC技术的实现分析
openGauss 事务机制中 MVCC 技术的实现分析 概述 事务 事务是为用户提供的最核心.最具吸引力的数据库功能之一.简单地说,事务是用户定义的一系列数据库操作(如查询.插入.修改或删除等)的集 ...
- 详解K8s 镜像缓存管理kube-fledged
本文分享自华为云社区<K8s 镜像缓存管理 kube-fledged 认知>,作者: 山河已无恙. 我们知道 k8s 上的容器调度需要在调度的节点行拉取当前容器的镜像,在一些特殊场景中, ...
- k8s 深入篇———— k8s 的本质[四]
前言 简单整理一下k8s的本质. 正文 首先,Kubernetes 项目要解决的问题是什么? 编排?调度?容器云?还是集群管理? 实际上,这个问题到目前为止都没有固定的答案.因为在不同的发展阶段,Ku ...
- 重新整理 .net core 实践篇——— 测试控制器[四十九]
前言 其实就是官方的例子,只是在此收录整理一下. 正文 测试控制器测试的是什么呢? 测试的是避开筛选器.路由.模型绑定,就是只测试控制器的逻辑,但是不测试器依赖项. 代码部分: https://git ...