复杂查询so easy ,GaussDB(for Cassandra)推Lucene引擎全新解决方案
摘要:复杂查询so easy!GaussDB(for Cassandra)新特性来袭。
本文分享自华为云社区《来了!GaussDB(for Cassandra)新特性亮相》,作者:GaussDB 数据库 。
今天,华为云GaussDB(for Cassandra)携Lucene引擎全新解决方案来啦!
当前,互联网、大数据飞速发展,数据量呈爆发式增长,在高并发、高可用、高扩展的业务需求推动下,NoSQL数据库成为了越来越多业务场景的刚需。但在查询方面,传统的NoSQL却有一定的局限性,严格来说,像开源MongoDB、Cassandra、Hbase等都不具备海量数据的多维查询、文本检索、统计分析等能力。多数企业仍然在寻求一套更完美的NoSQL解决方案。
华为云原生多模数据库GaussDB NoSQL拥有强大的生态体系,支持键值、宽表、文档、时序四种引擎接口。其中,宽表引擎接口GaussDB(for Cassandra)现已发布Lucene二级索引功能,既具备NoSQL的优势,又能支持多种复杂查询场景,全面提升用户在海量数据场景下的查询体验,凭实力宠粉!相信大家一定有很多疑问,GaussDB(for Cassandra)是什么?二级索引如何使用?Lucene二级索引又有哪些区别?别着急,接下来让我们一一解读。
什么是GaussDB(for Cassandra)?
GaussDB(for Cassandra)是一款华为自研、采用计算存储分离架构的分布式云数据库,在高性能、高可用、高可靠、高安全、可弹性扩缩容的基础上,提供了一键部署、备份恢复、监控告警等服务能力;并高度兼容开源Cassandra接口,提供高读写性能。当前已经广泛应用于IoT、气象、互联网、游戏等诸多领域。
什么是二级索引?
我们先来了解下索引的概念。索引是为了加快数据检索速度而创建的一种存储结构,是一种以空间换时间的设计思想。作用可以理解为书的目录,通过目录可快速定位到所需要的内容。
在Cassandra中,Primary Key就是索引(也被称为一级索引),在查询的时候,根据Primary Key可以直接检索到对应的记录。而二级索引又称辅助索引,是为了帮助定位到一级索引,然后再根据一级索引找到对应记录。我们平时使用CREATE INDEX语句建立的就是二级索引。
当前Cassandra二级索引的痛点有哪些?
原生Cassandra中二级索引的实现其实是创建了一张隐式的表,该表的Primary Key是创建索引的列,值为对应的Primary Key,实现相对简单,因此不可避免地带来了一些约束条件:
1.第一主键只能用“=”查询;
2.第二主键可以使用“=、>、<、>=、<=”;
3.索引列只支持“=”查询;
4.删除、更新太过频繁的列不适合建立索引;
5.High-cardinality列不适合做索引;
基于以上约束,Cassandra二级索引能提供的查询功能非常有限。
Why Lucene?
Lucene是当下最火的开源全文检索引擎工具,具有以下特点:
1.稳定、索引性能高;
2.是高效、准确、高性能的搜索算法;
3.具备丰富的查询类型:支持短语查询、通配符查询、近似查询、范围查询等;
4.有强大的开源社区支持,可维护性好;
因此,用集成Lucene引擎来补充Cassandra查询能力的弱点是最佳选择,毕竟谁又会拒绝一款性能稳定、持续成长、又更新迭代的搜索引擎呢?
Lucene引擎强大的倒排索引和列式存储能力,赋予了GaussDB(for Cassandra)高效的多维查询、文本检索、统计分析等能力,在使用体验上和原生二级索引相似,但同时拥有了更为丰富的语法支持。
使用Lucene二级索引后,我的查询发生了哪些变化?
更加灵活的查询、过滤方式:
所有查询均可不带PK或者带部分PK,并且索引列支持 “>、<、in”等操作符,用户不需要再局限于只使用“=”。
强大的文本检索能力:
文本检索能力正是Lucene最擅长的,使用起来十分方便,只需要通过关键词like即可实现。
你可以这样:
SELECT * FROM example WHERE field LIKE 'test%'; // 前缀查询
也可以这样:
SELECT * FROM example WHERE field LIKE 'start*end'; // 正则匹配
还可以这样:
SELECT * FROM example WHERE field LIKE '%+lucene +index%'; // 全文搜索功能,性能高效,稳定
支持超万亿规格的大数据量统计:
select count(*) from example where pk > 1 and expr(lucene_index, 'count');
多种删除方式:
支持single单行删除、partition分区删除、range范围删除,全方位覆盖各种删除场景。
DELETE FROM example WHERE pk1='a' AND field=1; // single单行删除
DELETE FROM example WHERE pk1='a' AND pk2=5000; // partition分区删除
DELETE FROM example WHERE pk1='a' AND pk2=3000 AND ck1=2 AND ck2>'a' AND ck2<'c'; // range范围删除
支持扩展json查询接口,轻松应对各种复杂查询场景:
扩展的json查询接口提供了丰富的查询语法,用法更多样化。以下是关键字列表:
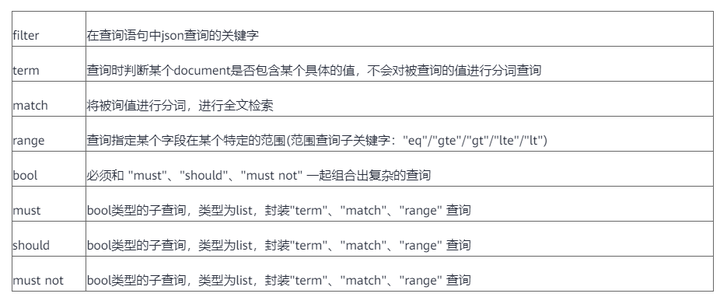
举个栗子:
SELECT * FROM example WHERE EXPR(index_field, '{"filter": {"bool": {"should": [{"bool": {"should": [{"bool": {"must": [{"bool": {"should": [{"range": {"ck1": {"lt": 2}, "ck1": {"gte": 4}}}]}}, {"bool": {"should": [{"range": {"field1": {"lt": 2}, "field1": {"gt": 3}}}]}}]}}, {"bool": {"should": [{"term": {"pk1": "a", "pk1": "b", "pk1": "c"}}]}}]}}, {"bool": {"must": [{"range": {"field2": {"gte":5, "lte": 15}, "pk2": {"gt": 2000}}}]}}]}}}')
通过条件组合加嵌套,您可以DIY符合自身业务的sql语句,并且最高支持200层json嵌套,再复杂的场景也能处理!
华为云GaussDB(for Cassandra)搭载Lucene引擎,通过Lucene二级索引将搜索能力下沉至底层,从根本上解放了应用层查询,兼具多维查询、文本检索、统计分析等多种能力,可以完美地弥补NoSQL弱查询功能的短板,让企业从容应对海量数据的复杂查询场景。还等什么,速来体验吧!
附录
本文作者:华为云高斯Cassandra团队
更多技术文章,请关注高斯Cassandra官方博客:https://bbs.huaweicloud.com/community/usersnew/id_1563519101830986
复杂查询so easy ,GaussDB(for Cassandra)推Lucene引擎全新解决方案的更多相关文章
- 华为云数据库GaussDB(for Cassandra)揭秘第二期:内存异常增长的排查经历
摘要:华为云数据库GaussDB(for Cassandra) 是一款基于计算存储分离架构,兼容Cassandra生态的云原生NoSQL数据库:它依靠共享存储池实现了强一致,保证数据的安全可靠. 本文 ...
- 转型?还是延伸?开源建站系统近乎推整套SNS社区解决方案
转型?还是延伸?开源建站系统近乎推整套SNS社区解决方案 近乎(英文:Spacebuilder),作为.net领域的SNS社区建站系统代表之一,一直在技术开发领域算是兢兢业业,在Discuz!和Php ...
- SpringBoot里mybatis查询结果为null的列不返回问题的解决方案
对于mybatis里查询结果为null的列不返回的问题解决方案 在配置文件application.properties里增加 Mybatis.configuration.call-setters-on ...
- lucene复合条件查询案例——查询name域 或 description域 包含lucene关键字的两种方式
方式一:使用语法表达式查询 //查询name域 或 description域包含lucene关键字 QueryParser queryParser = new QueryParser("na ...
- Android第三方推送引擎比较
所了解的第三方推送引擎有极光推送(JPush), 百度, 个推,腾讯信鸽等.根据了解,最专业的据说是极光推送,先看极光推送. 一.极光推送 https://www.jpush.cn/ 配置: 1.JP ...
- Easy APNs Provider 消息推送测试工具
1.Easy APNs Provider 简介 Easy APNs Provider 是一款为 iOS.Mac App 提供推送测试的小工具. App Store 下载地址 Easy APNs Pro ...
- 【C#】【MySQL】C# 查询数据库语句@Row:=@Row+1以及执行存储过程失败解决方案
如何实现数据库查询产生虚拟的一列序号的功能: ) )AS r; 该语句可以实现产生虚拟的一列数据在MySQL中运行没有问题. 但是在C#里面调用去出现了错误"Parameter '@ROW' ...
- iOS 推送角标解决方案
在App启动时:didFinishLaunchingWithOptions 方法中:application.applicationIconBadgeNumber = ; //角标清零 在读消息时: a ...
- 揭秘华为云GaussDB(for Influx)最佳实践:hint查询
摘要:GaussDB(for Influx)通过提供hint功能,在单时间线的查询场景下,性能有大幅度的提升,能有效满足客户某些特定场景的查询需求. 本文分享自华为云社区<华为云GaussDB( ...
- RDS、DDS 和 GaussDB 理不清?看这一篇足够了!
当前,华为云提供的数据库服务主要包括三大类:关系型数据库服务,非关系型数据库服务以及数据库工具服务.如下图所示: 关系型数据库和非关系型数据库均可分为开源和自研两大类.其中,自研数据库统一为Gauss ...
随机推荐
- C++中const和constexpr的多文件链接问题
C++语言支持分离编译,在多文件编程中:变量或函数可以被声明多次,但却只能被定义一次.如果要在多个文件中使用同一个变量,变量的定义能且只能出现在一个文件中,在其他使用该变量的文件中需要声明该变量.如果 ...
- 揭秘计算机指令执行的神秘过程:CPU内部的绝密操作
计算机指令 从软件工程师的角度来看,CPU是执行计算机指令的逻辑机器.计算机指令可以看作是CPU能够理解的语言,也称为机器语言. 不同的CPU能理解的语言不同.例如,个人电脑使用Intel的CPU,苹 ...
- Jenkins软件平台安装部署
1.Jenkins软件平台概念剖解: 基于主流的Hudson/Jenkins平台工具实现全自动网站部署.网站测试.网站回滚会大大的减轻网站部署的成本,Jenkins的前身为Hudson,Hudson主 ...
- Unity - UIWidgets 1. 从Hello world开始
安装参照github的README.UIWidgets相当于Flutter的一个Unity实现(后面表示UIWidgets和UGUI区别时直接称"Flutter"),是把承载的所有 ...
- C++基础杂记(1)
结构体中的位字段 共用体 烦人的枚举 枚举的声明与赋值 枚举的取值范围与强制类型转换 枚举的注意事项 指针 为什么是 int* ptr 而不是 int *ptr ? 避免危险的指针 使用array和v ...
- C#判断字符串的显示宽度
C#判断字符串的显示宽度 起因: 公司有一个使用项目使用HTML转换为PDF,其中有一个表格,表格的最后一列中的单元格,其字符串超长后会被丢弃,而不是换行到下一行展示(HtmlToPdf渲染引擎导致的 ...
- 题解 CF637B
题目大意: 维护个栈,去重保留最上层 题目分析: 啥也不是,数组模拟 \(\text{stack} + \text{unordered\_map}\) 直接秒掉. 复杂度 \(O(n)\) 代码实现: ...
- Istio:微服务开发的终极利器,你还在为繁琐的通信和部署流程烦恼吗?
引言 在前面的讲解中,我们已经提及了微服务的一些弊端,并介绍了Istio这样的解决方案.那么,对于我们开发人员来说,Istio究竟会带来哪些变革呢?今天我们就来简要探讨一下! Kubernetes简单 ...
- .NET领域性能最好的对象映射框架Mapster使用方法
Mapster是一个开源的.NET对象映射库,它提供了一种简单而强大的方式来处理对象之间的映射.在本文中,我将详细介绍如何在.NET中使用Mapster,并提供一些实例和源代码. 和其它框架性能对比: ...
- 热烈祝贺:薪火数据(https://www.datainside.com.cn 数据中心低代码搭建平台)参加教育博览会取得圆满成功。