增补博客 第八篇 python 中国大学排名数据分析与可视化
【题目描述】以软科中国最好大学排名为分析对象,基于requests库和bs4库编写爬虫程序,对2015年至2019年间的中国大学排名数据进行爬取:
(1)按照排名先后顺序输出不同年份的前10位大学信息,并要求对输出结果的排版进行优化;
(2)结合matplotlib库,对2015-2019年间前10位大学的排名信息进行可视化展示。
(3附加)编写一个查询程序,根据从键盘输入的大学名称和年份,输出该大学相应的排名信息。如果所爬取的数据中不包含该大学或该年份信息,则输出相应的提示信息,并让用户选择重新输入还是结束查询;
【练习要求】请给出源代码程序和运行测试结果,源代码程序要求添加必要的注释。
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
from sympy.physics.control.control_plots import matplotlib plt.rcParams['font.sans-serif']=['SimHei'] # 用来设置字体样式以正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 默认是使用Unicode负号,设置正常显示字符,如正常显示负号 # 设置请求头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"
} def get_ranking(year):
url = f'https://www.shanghairanking.cn/rankings/bcur/{year}.html'
# 发送HTTP请求以获取网页内容
response = requests.get(url, headers=headers)
# 检查请求是否成功
if response.status_code == 200:
# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(response.content, 'html.parser')
# 找到包含大学信息的表格
table = soup.find('table', class_='rk-table')
# 提取前10所大学的信息
universities = table.find_all('tr', {'data-v-90b0d2ac': True})[1:11] # 排除表头行
# 存储排名数据的列表
ranking_data = []
for university in universities:
rank_element = university.find('td', {'data-v-90b0d2ac': True})
# 检查排名元素是否存在
if rank_element:
rank = rank_element.text.strip()
name = university.find('a').text.strip()
# 将排名数据存储到列表中
ranking_data.append({"排名": rank, "名称": name})
return ranking_data
else:
print("请求失败。状态码:", response.status_code) def main():
# 1. 获取并输出前10位大学信息
for year in range(2015, 2020):
ranking_data = get_ranking(year)
if ranking_data:
print(f"{year}年前10所大学:")
for data in ranking_data:
print(f"{data['排名']}. {data['名称']}")
print()
# 创建一个表格的figure
fig, ax = plt.subplots()
# 隐藏坐标轴
ax.axis('off')
# 创建表格
table = ax.table(cellText=[list(data.values()) for data in ranking_data], colLabels=list(ranking_data[0].keys()), loc='center')
# 调整表格字体大小
table.auto_set_font_size(False)
table.set_fontsize(12)
# 调整单元格高度
table.scale(1, 1.5)
# 显示表格
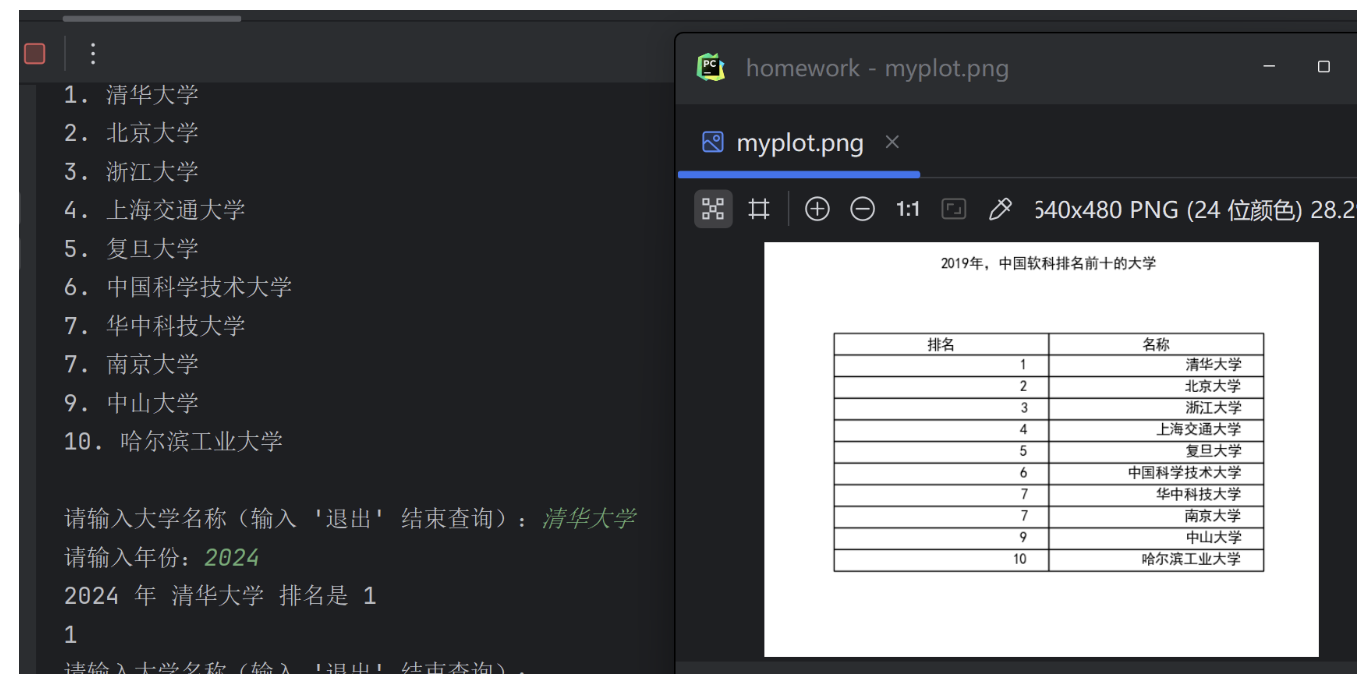
plt.title(f"{year}年,中国软科排名前十的大学", pad=20)
plt.show()
else:
print(f"未能获取{year}年的大学排名数据。") def get_specific_ranking(university, year): # Renamed the function
# 构建URL
url = f'https://www.shanghairanking.cn/rankings/bcur/{year}.html' # 发送HTTP请求
response = requests.get(url) # 检查响应状态码
if response.status_code == 200:
# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(response.content, 'html.parser')
# 找到包含大学信息的表格
table = soup.find('table', class_='rk-table')
# 提取前30所大学的信息
universities = table.find_all('tr', {'data-v-90b0d2ac': True})[1:31] # 排除表头行
# 存储排名数据的列表
ranking_data = []
for university_row in universities:
name_element = university_row.find('a')
# 检查大学名称元素是否存在
if name_element:
name = name_element.text.strip()
# 检查大学名称是否与输入的大学名称匹配
if name == university:
rank_element = university_row.find('td', {'data-v-90b0d2ac': True})
if rank_element:
rank = rank_element.text.strip()
print(f"{year} 年 {university} 排名是 {rank}")
return rank
# 如果未找到匹配的大学名称,打印消息
print(f"找不到 {university} 在 {year} 年的排名信息。")
else:
print("请求失败。状态码:", response.status_code) if __name__ == "__main__":
main()
while True:
university = input("请输入大学名称(输入 '退出' 结束查询):")
if university.lower() == '退出':
break
year = input("请输入年份:")
print(get_specific_ranking(university, year))
增补博客 第八篇 python 中国大学排名数据分析与可视化的更多相关文章
- Python 中国大学排名定向爬虫
代码来自于中国大学Mooc北京理工大学Pythont教学团队:https://www.icourse163.org/learn/BIT-1001870001#/learn/content?type=d ...
- 一鼓作气 博客--第八篇 note8
0.,222] list[33] except IndexError as e : print('index error ') except ValueError as e : print('valu ...
- Scrum 冲刺博客第八篇
一.当天站立式会议照片一张 二.每个人的工作 (有work item 的ID),并将其记录在码云项目管理中 昨天已完成的工作 对界面进行美化 今天计划完成的工作 连接数据库实现排行榜的基本功能 工作中 ...
- [转]有哪些值得关注的技术博客(Java篇)
有哪些值得关注的技术博客(Java篇) 大部分程序员在自学的道路上不知道走了多少坑,这个视频那个网站搞得自己晕头转向.对我个人来说我平常在学习的过程中喜欢看一些教程式的博客.这些博客的特点: 1. ...
- Django 系列博客(八)
Django 系列博客(八) 前言 本篇博客介绍 Django 中的模板层,模板都是Django 使用相关函数渲染后传输给前端在显式的,为了想要渲染出我们想要的数据,需要学习模板语法,相关过滤器.标签 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - 终结篇之发布项目
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- 年度十佳 DevOps 博客文章(前篇)
如果说 15 年你还没有将 DevOps 真正应用起来,16 年再不实践也未免太落伍了.国内 ITOM 领军企业 OneAPM 工程师为您翻译整理了,2015 年十佳 DevOps 文章,究竟是不是深 ...
- # Do—Now——团队冲刺博客_总结篇
Do-Now--团队冲刺博客_总结篇 目录 博客链接 作者 1. 第一篇(领航篇) @仇夏 2. 第二篇 @侯泽洋 3. 第三篇 @仇夏 4. 第四篇 @周亚杰 5. 第五篇 @唐才铭 6. 第六篇 ...
- 为了确认是您本人在申请搬家,请在原博客发表一 篇标题为《将博客搬至CSDN》的文章,并将文章地址填写在上方的"搬家通知地址"中
为了确认是您本人在申请搬家,请在原博客发表一 篇标题为<将博客搬至CSDN>的文章,并将文章地址填写在上方的"搬家通知地址"中
- thinkphp5项目--个人博客(八)
thinkphp5项目--个人博客(八) 项目地址 fry404006308/personalBlog: personalBloghttps://github.com/fry404006308/per ...
随机推荐
- 一种命令行解析的新思路(Go 语言描述)
简介: 本文通过打破大家对命令行的固有印象,对命令行的概念解构后重新梳理,开发出一种功能强大但使用极为简单的命令行解析方法.这种方法支持任意多的子命令,支持可选和必选参数,对可选参数可提供默认值,支 ...
- 所有前端都要看的2D游戏化互动入门基础知识
简介: 在非游戏环境中将游戏的思维和游戏的机制进行整合运用,以引导用户互动和使用 本文作者:淘系前端团队-Eva.js作者-明非 背景 现在越来越多的公司和 App 开始使用游戏化的方式去做产品了,所 ...
- Javascript 机器学习的四个层次
简介: Atwood定律说,凡是可以用Javascript实现的应用,最终都会用Javascript实现掉.作为最热门的机器学习领域,服务端是Python的主场,但是到了手机端呢?Android和i ...
- CMDB开发(三)
6.API验证 # 加密复习 #1.简单的对称加密,token是固定的 客户端请求: import requests # 1.自定义token值 token = 'cxiong_token' # to ...
- 通俗易懂的生产环境Web应用架构介绍
前言 看见一篇非常通俗易懂且适合新手阅读的Web应用架构文章,我将其手工翻译了出来,分享给大家. 也可以去阅读英文原文,标题为,贴出链接: https://stephenmann.io/post/wh ...
- Data LakeHouse_理解湖仓一体
Data Lakehouse(湖仓一体)是数据管理领域中的一种新架构范例,结合了Data Warehouse和Data Lakes的最佳特性.数据分析师和数据科学家可以在同一个数据存储中对数据进行操作 ...
- goland dlv在远程linux里运行代码开发,并debug调适
一.配置好ssh自动同步代码 参考下面连接: https://www.cnblogs.com/haima/p/13257524.html 二.配置devbug监听运行 GO Remote 填写配置 l ...
- 记一次线上Redis内存占用过高、大Key问题的排查
问题背景 在一个风和日丽的下午,公司某项目现场运维同学反馈,生产环境3个Redis的Sentinel集群节点内存占用都很高,达到了17GB的内存占用量. 稍加思索,应该是某些Key的Value数据体量 ...
- cesium问题-关于不同时间模型亮度不一致问题
项目中遇到发布的bim模型在当天不同时间的模型亮度发生变化,尤其是晚上的时候会出现模型很暗.尴了个尬,一度怀疑是自己眼睛有问题,连续几天出现同样的情况,想到可能是时间问题导致的模型亮度不同,于是测试了 ...
- Gitee千Star优质项目解析: ng-form-element低开引擎解析
好家伙, 在写项目的时候,我发现自己的平台的组件写的实在是太难看了,于是想去gitee上偷点东西,于是我们本期的受害者出现了 gitee项目地址 https://gitee.com/jjxliu306 ...