教你如何用Keepalived和HAproxy配置高可用 Kubernetes 集群
本文分享自华为云社区《使用 Keepalived 和 HAproxy 创建高可用 Kubernetes 集群》,作者:江晚正愁余。
高可用 Kubernetes 集群能够确保应用程序在运行时不会出现服务中断,这也是生产的需求之一。为此,有很多方法可供选择以实现高可用。
本教程演示了如何配置 Keepalived 和 HAproxy 使负载均衡、实现高可用。步骤如下:
- 准备主机。
- 配置 Keepalived 和 HAproxy。
- 使用 KubeKey 创建 Kubernetes 集群,并安装 KubeSphere。
集群架构
示例集群有三个主节点,三个工作节点,两个用于负载均衡的节点,以及一个虚拟 IP 地址。本示例中的虚拟 IP 地址也可称为“浮动 IP 地址”。这意味着在节点故障的情况下,该 IP 地址可在节点之间漂移,从而实现高可用。
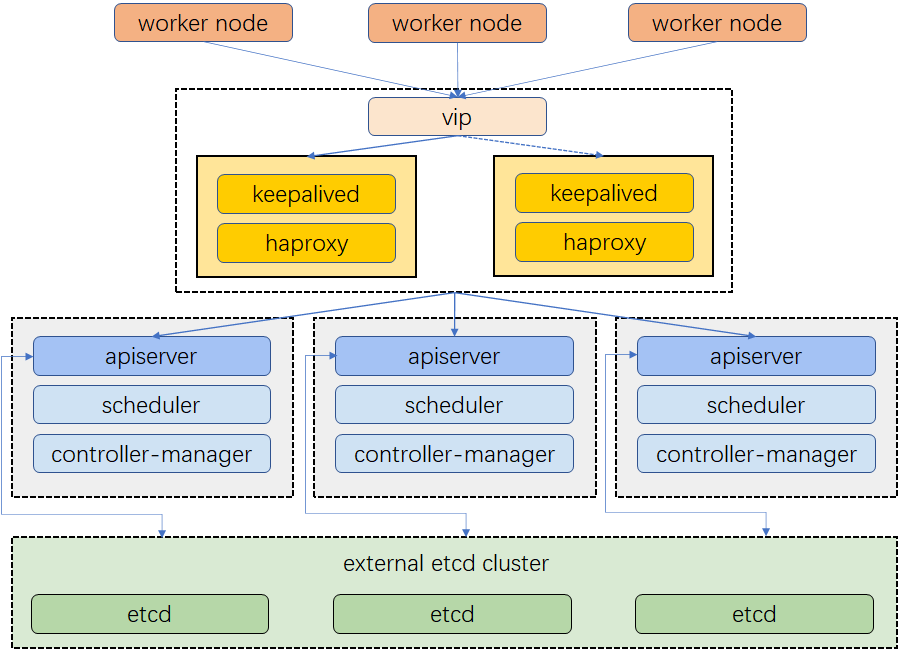
请注意,在本示例中,Keepalived 和 HAproxy 没有安装在任何主节点上。但您也可以这样做,并同时实现高可用。然而,配置两个用于负载均衡的特定节点(您可以按需增加更多此类节点)会更加安全。这两个节点上只安装 Keepalived 和 HAproxy,以避免与任何 Kubernetes 组件和服务的潜在冲突。
准备主机
|
IP 地址 |
主机名 |
角色 |
|---|---|---|
|
172.16.0.2 |
lb1 |
Keepalived & HAproxy |
|
172.16.0.3 |
lb2 |
Keepalived & HAproxy |
|
172.16.0.4 |
master1 |
master, etcd |
|
172.16.0.5 |
master2 |
master, etcd |
|
172.16.0.6 |
master3 |
master, etcd |
|
172.16.0.7 |
worker1 |
worker |
|
172.16.0.8 |
worker2 |
worker |
|
172.16.0.9 |
worker3 |
worker |
|
172.16.0.10 |
虚拟 IP 地址 |
有关更多节点、网络、依赖项等要求的信息,请参见多节点安装。
配置负载均衡
Keepalived 提供 VRRP 实现,并允许您配置 Linux 机器使负载均衡,预防单点故障。HAProxy 提供可靠、高性能的负载均衡,能与 Keepalived 完美配合。
由于 lb1 和 lb2 上安装了 Keepalived 和 HAproxy,如果其中一个节点故障,虚拟 IP 地址(即浮动 IP 地址)将自动与另一个节点关联,使集群仍然可以正常运行,从而实现高可用。若有需要,也可以此为目的,添加更多安装 Keepalived 和 HAproxy 的节点。
先运行以下命令安装 Keepalived 和 HAproxy。
yum install keepalived haproxy psmisc -y
HAproxy
1.在两台用于负载均衡的机器上运行以下命令以配置 Proxy(两台机器的 Proxy 配置相同):
vi /etc/haproxy/haproxy.cfg
2.以下是示例配置,供您参考(请注意 server 字段。请记住 6443 是 apiserver 端口):
global log /dev/log local0 warning chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon stats socket /var/lib/haproxy/stats defaults log global option httplog option dontlognull timeout connect 5000 timeout client 50000 timeout server 50000 frontend kube-apiserver bind *:6443 mode tcp option tcplog default_backend kube-apiserver backend kube-apiserver mode tcp option tcplog option tcp-check balance roundrobin default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100 server kube-apiserver-1 172.16.0.4:6443 check # Replace the IP address with your own. server kube-apiserver-2 172.16.0.5:6443 check # Replace the IP address with your own. server kube-apiserver-3 172.16.0.6:6443 check # Replace the IP address with your own.
3.保存文件并运行以下命令以重启 HAproxy。
systemctl restart haproxy
4.使 HAproxy 在开机后自动运行:
systemctl enable haproxy
5.确保您在另一台机器 (lb2) 上也配置了 HAproxy。
Keepalived
两台机器上必须都安装 Keepalived,但在配置上略有不同。
1.运行以下命令以配置 Keepalived。
vi /etc/keepalived/keepalived.conf
2.以下是示例配置 (lb1),供您参考:
global_defs {
notification_email {
}
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 2
weight 2
}
vrrp_instance haproxy-vip {
state BACKUP
priority 100
interface eth0 # Network card
virtual_router_id 60
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
unicast_src_ip 172.16.0.2 # The IP address of this machine
unicast_peer {
172.16.0.3 # The IP address of peer machines
}
virtual_ipaddress {
172.16.0.10/24 # The VIP address
}
track_script {
chk_haproxy
}
}
备注
- 对于 interface 字段,您必须提供自己的网卡信息。您可以在机器上运行 ifconfig 以获取该值。
- 为 unicast_src_ip 提供的 IP 地址是您当前机器的 IP 地址。对于也安装了 HAproxy 和 Keepalived 进行负载均衡的其他机器,必须在字段 unicast_peer 中输入其 IP 地址。
3.保存文件并运行以下命令以重启 Keepalived。
systemctl restart keepalived
4.使 Keepalived 在开机后自动运行:
systemctl enable keepalived
5.确保您在另一台机器 (lb2) 上也配置了 Keepalived。
验证高可用
在开始创建 Kubernetes 集群之前,请确保已经测试了高可用。
1.在机器 lb1 上,运行以下命令:
[[email protected] ~]# ip a s 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 52:54:9e:27:38:c8 brd ff:ff:ff:ff:ff:ff inet 172.16.0.2/24 brd 172.16.0.255 scope global noprefixroute dynamic eth0 valid_lft 73334sec preferred_lft 73334sec inet 172.16.0.10/24 scope global secondary eth0 # The VIP address valid_lft forever preferred_lft forever inet6 fe80::510e:f96:98b2:af40/64 scope link noprefixroute valid_lft forever preferred_lft forever
2.如上图所示,虚拟 IP 地址已经成功添加。模拟此节点上的故障:
systemctl stop haproxy
3.再次检查浮动 IP 地址,您可以看到该地址在 lb1 上消失了。
[[email protected] ~]# ip a s 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 52:54:9e:27:38:c8 brd ff:ff:ff:ff:ff:ff inet 172.16.0.2/24 brd 172.16.0.255 scope global noprefixroute dynamic eth0 valid_lft 72802sec preferred_lft 72802sec inet6 fe80::510e:f96:98b2:af40/64 scope link noprefixroute valid_lft forever preferred_lft forever
4.理论上讲,若配置成功,该虚拟 IP 会漂移到另一台机器 (lb2) 上。在 lb2 上运行以下命令,这是预期的输出:
[[email protected] ~]# ip a s 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 52:54:9e:3f:51:ba brd ff:ff:ff:ff:ff:ff inet 172.16.0.3/24 brd 172.16.0.255 scope global noprefixroute dynamic eth0 valid_lft 72690sec preferred_lft 72690sec inet 172.16.0.10/24 scope global secondary eth0 # The VIP address valid_lft forever preferred_lft forever inet6 fe80::f67c:bd4f:d6d5:1d9b/64 scope link noprefixroute valid_lft forever preferred_lft forever
5.如上所示,高可用已经配置成功。
使用 KubeKey 创建 Kubernetes 集群
KubeKey 是一款用来创建 Kubernetes 集群的工具,高效而便捷。请按照以下步骤下载 KubeKey。
从 GitHub Release Page 下载 KubeKey 或者直接使用以下命令。
curl -sfL https://get-kk.kubesphere.io | VERSION=v2.0.0 sh -
首先运行以下命令,以确保您从正确的区域下载 KubeKey。
export KKZONE=cn
运行以下命令来下载 KubeKey:
curl -sfL https://get-kk.kubesphere.io | VERSION=v2.0.0 sh -
备注
下载 KubeKey 之后,如果您将其转移到访问 Googleapis 受限的新机器上,请务必再次运行 export KKZONE=cn,然后继续执行以下步骤。
备注
通过以上命令,可以下载 KubeKey 的最新版本 (v2.0.0)。您可以更改命令中的版本号来下载特定的版本。
使 kk 成为可执行文件:
chmod +x kk
使用默认配置创建一个示例配置文件。此处以 Kubernetes v1.21.5 作为示例。
./kk create config --with-kubesphere v3.2.1 --with-kubernetes v1.21.5
备注
- 安装 KubeSphere 3.2.1 的建议 Kubernetes 版本:v1.19.x、v1.20.x、v1.21.x 或 v1.22.x(实验性支持)。如果不指定 Kubernetes 版本,KubeKey 将默认安装 Kubernetes v1.21.5。有关受支持的 Kubernetes 版本的更多信息,请参见支持矩阵。
- 如果您没有在本步骤的命令中添加标志 --with-kubesphere,那么除非您使用配置文件中的 addons 字段进行安装,或者稍后使用 ./kk create cluster 时再添加该标志,否则 KubeSphere 将不会被部署。
- 如果您添加标志 --with-kubesphere 时未指定 KubeSphere 版本,则会安装最新版本的 KubeSphere。
部署 KubeSphere 和 Kubernetes
运行上述命令后,将创建配置文件 config-sample.yaml。编辑文件以添加机器信息、配置负载均衡器等。
备注
如果自定义文件名,那么文件名可能会有所不同。
config-sample.yaml 示例
...
spec:
hosts:
- {name: master1, address: 172.16.0.4, internalAddress: 172.16.0.4, user: root, password: Testing123}
- {name: master2, address: 172.16.0.5, internalAddress: 172.16.0.5, user: root, password: Testing123}
- {name: master3, address: 172.16.0.6, internalAddress: 172.16.0.6, user: root, password: Testing123}
- {name: worker1, address: 172.16.0.7, internalAddress: 172.16.0.7, user: root, password: Testing123}
- {name: worker2, address: 172.16.0.8, internalAddress: 172.16.0.8, user: root, password: Testing123}
- {name: worker3, address: 172.16.0.9, internalAddress: 172.16.0.9, user: root, password: Testing123}
roleGroups:
etcd:
- master1
- master2
- master3
master:
- master1
- master2
- master3
worker:
- worker1
- worker2
- worker3
controlPlaneEndpoint:
domain: lb.kubesphere.local
address: 172.16.0.10 # The VIP address
port: 6443
...
备注
- 请使用您自己的 VIP 地址来替换 controlPlaneEndpoint.address 的值。
- 有关更多本配置文件中不同参数的信息,请参见多节点安装。
开始安装
完成配置之后,可以执行以下命令开始安装:
./kk create cluster -f config-sample.yaml
验证安装
1.运行以下命令以检查安装日志。
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
2.看到以下信息时,表明高可用集群已成功创建。
##################################################### ### Welcome to KubeSphere! ### ##################################################### Console: http://172.16.0.4:30880 Account: admin Password: [email protected] NOTES: 1. After you log into the console, please check the monitoring status of service components in the "Cluster Management". If any service is not ready, please wait patiently until all components are up and running. 2. Please change the default password after login. ##################################################### https://kubesphere.io 2020-xx-xx xx:xx:xx #####################################################
教你如何用Keepalived和HAproxy配置高可用 Kubernetes 集群的更多相关文章
- 搭建高可用kubernetes集群(keepalived+haproxy)
序 由于单master节点的kubernetes集群,存在master节点异常之后无法继续使用的缺陷.本文参考网管流程搭建一套多master节点负载均衡的kubernetes集群.官网给出了两种拓扑结 ...
- Keepalived+Nginx+Tomcat 实现高可用Web集群
https://www.jianshu.com/p/bc34f9101c5e Keepalived+Nginx+Tomcat 实现高可用Web集群 0.3912018.01.08 20:28:59字数 ...
- Nginx 配置高可用的集群
1.什么是 nginx 高可用 (1)需要两台 nginx 服务器 (2)需要 keepalived (3)需要虚拟 ip 2.配置高可用的准备工作 (1)需要两台服务器 192.168.17.129 ...
- centos7使用kubeadm配置高可用k8s集群
CountingStars_ 关注 2018.08.12 09:06* 字数 464 阅读 88评论 0喜欢 0 简介 使用kubeadm配置多master节点,实现高可用. 安装 实验环境说明 实验 ...
- kubeadm配置高可用etcd集群
操作系统为ubuntu18 kubernetes版本为v1.15.1 k8s默认在控制平面节点上的kubelet管理的静态pod中运行单个成员的etcd集群,但这不是高可用的方案. etcd高可用集群 ...
- 一键配置高可用Hadoop集群(hdfs HA+zookeeper HA)
准备环境 3台节点,主节点 建议 2G 内存,两个从节点 1.5G内存, 桥接网络 关闭防火墙 配置ssh,让节点之间能够相互 ping 通 准备 软件放到 autoInstall 目录下,已存放 ...
- Nginx笔记总结十五:nginx+keepalive+proxy_cache配置高可用nginx集群和高速缓存
nginx编译 wget http://labs.frickle.com/files/ngx_cache_purge-2.3.tar.gz ./configure --prefix=/usr/loca ...
- Keepalived之高可用LVS集群
前文我们聊了下keepalived的邮件通知相关配置,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/13645163.html:今天我们来说说keepalive ...
- 搭建高可用mongodb集群(一)——配置mongodb
在大数据的时代,传统的关系型数据库要能更高的服务必须要解决高并发读写.海量数据高效存储.高可扩展性和高可用性这些难题.不过就是因为这些问题Nosql诞生了. NOSQL有这些优势: 大数据量,可以通过 ...
- Redis高可用之集群配置(六)
0.Redis目录结构 1)Redis介绍及部署在CentOS7上(一) 2)Redis指令与数据结构(二) 3)Redis客户端连接以及持久化数据(三) 4)Redis高可用之主从复制实践(四) 5 ...
随机推荐
- JVM 堆外内存查看方法
JVM 堆外内存查看方法 JVM 堆外内存查看方法 1.概述 是否曾经想过为什么Java应用程序通过众所周知的*-Xms和-Xmx调整标志消耗的内存比指定的数量大得多 ?由于各种原因和可能的优化,JV ...
- linux 查看系统计划任务相关的命令
最近公司排查计划任务: for i in `ls /etc/cron.d` ; do cat /etc/cron.d/$i |grep -v "#" ; done for i in ...
- CentOS上面阿里源的设置过程
1. 移除已经有的yum仓库 #原因: 公司内部部分境外网站不能访问,会提示异常. rm -rf /etc/yum.repos.d/* 2. 使用阿里源进行处理. #主要有两个, 一个是base的一个 ...
- 2024了,我不想再用AOP收集业务操作日志了 | 京东云技术团队
0.背景 在近期的项目中,系统涉及到针对系统的业务操作日志统计功能,由于本系统位于业务链路的中心环节,负责接收上游系统的数据,并将基于用户操作产生的数据传递至下游系统,鉴于业务链路的复杂性和操作场景的 ...
- 一文带你搞懂如何优化慢SQL
作者:京东科技 宋慧超 一.前言 最近通过SGM监控发现有两个SQL的执行时间占该任务总执行时间的90%,通过对该SQL进行分析和优化的过程中,又重新对SQL语句的执行顺序和SQL语句的执行计划进行了 ...
- vue中$children的理解
官网介绍 $children $children 获取当前实例的直接子组件 .需要注意 $children 并不保证顺序,也不是响应式的.[特别重要] 如果你发现自己正在尝试使用 $children ...
- 【发现一个问题】使用 fastcgo 导致额外的 `runtime._System` 调用的消耗
作者:张富春(ahfuzhang),转载时请注明作者和引用链接,谢谢! cnblogs博客 zhihu Github 公众号:一本正经的瞎扯 为了避免 cgo 调用浪费太多资源,因此使用了 fastc ...
- 每日一库:Memcache
Memcache 是一个高性能.分布式的内存缓存系统,常用于缓存数据库查询结果.API调用结果.页面内容等,以提升应用程序的性能和响应速度.下面详细介绍一些 Memcache 的特点和使用方式: 内存 ...
- 手撕Vue-提取元素到内存
接着上一篇文章,我们已经实现了构建Vue实例的过程,接下来我们要实现的是提取元素到内存. 主要是通过文档碎片来实现,文档碎片是一个轻量级的文档,可以包含和控制节点,但是不会像真实的DOM那样占用内存, ...
- Rsync+Inotify 实现数据同步
Rsync 是UNIX及类UNIX-Like平台下一款强大的数据镜像备份软件,它不像FTP或其他文件传输服务那样需要进行全备份,Rsync 可以根据数据的变化进行差异备份,从而减少数据流量,提高工作效 ...