KubeSphere 核心架构浅析
作者简介:万宏明,KubeSphere 核心贡献者,专注于云原生安全领域。
KubeSphere 是在 Kubernetes 之上构建的面向云原生应用的容器混合云管理系统。支持多云与多集群管理,提供全栈的自动化运维能力,帮助企业用户简化 DevOps 工作流,提供了运维友好的向导式操作界面,帮助企业快速构建一个强大和功能丰富的容器云平台。
KubeSphere 为用户提供构建企业级 Kubernetes 环境所需的多项功能,例如多云与多集群管理、Kubernetes 资源管理、DevOps、应用生命周期管理、微服务治理(服务网格)、日志查询与收集、服务与网络、多租户管理、监控告警、事件与审计查询、存储管理、访问权限控制、GPU 支持、网络策略、镜像仓库管理以及安全管理等。
得益于 Kubernetes 优秀的架构与设计,KubeSphere 取长补短采用了更为轻量的架构模式,灵活的整合资源,进一步丰富了 K8s 生态。
KubeSphere 核心架构
KubeSphere 的核心架构如下图所示:
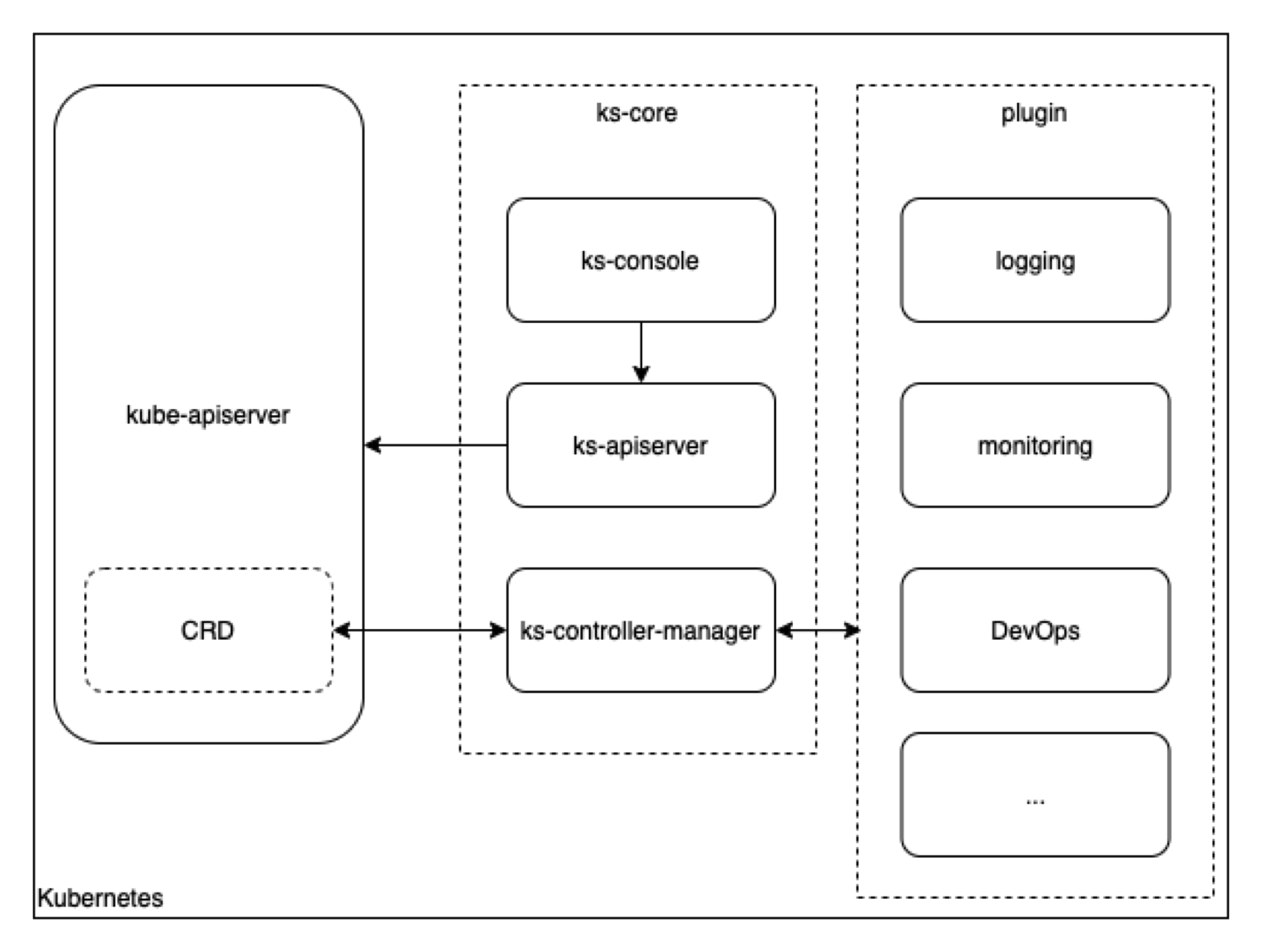
核心组件主要有三个:
- ks-console 前端服务组件
- ks-apiserver 后端服务组件
- ks-controller-manager 资源状态维护组件
KubeSphere 的后端设计中沿用了 K8s 声明式 API 的风格,所有可操作的资源都尽可能的抽象成为 CustomResource。与命令式 API 相比,声明性 API 的使用更加简洁,并且提供了更好的抽象性, 告诉程序最终的期望状态(做什么),而不关心怎么做。
典型地,在声明式 API 中:
- 你的 API 包含相对而言为数不多的、尺寸较小的对象(资源)。
- 对象定义了应用或者基础设施的配置信息。
- 对象更新操作频率较低。
- 通常需要人来读取或写入对象。
- 对象的主要操作是 CRUD 风格的(创建、读取、更新和删除)。
- 不需要跨对象的事务支持:API 对象代表的是期望状态而非确切实际状态。
命令式 API(Imperative API)与声明式有所不同。 以下迹象表明你的 API 可能不是声明式的:
- 客户端发出“做这个操作”的指令,之后在该操作结束时获得同步响应。
- 客户端发出“做这个操作”的指令,并获得一个操作 ID,之后需要判断请求是否成功完成。
- 你会将你的 API 类比为 RPC。
- 直接存储大量数据。
- 在对象上执行的常规操作并非 CRUD 风格。
- API 不太容易用对象来建模。
借助 kube-apiserver、etcd 实现数据同步和数据持久化,通过 ks-controller-manager 维护这些资源的状态,以达到最终状态的一致性。如果你熟悉 K8s,可以很好的理解声明式 API 带来的好处,这也是 KubeSphere 最为核心的部分。
例如 KubeSphere 中的流水线、用户凭证、用户实体、告警通知的配置,都可以抽象为资源实体,借助 K8s 成熟的架构与工具链,可以方便的与 K8s 进行结合,降低各组件之间的耦合,降低系统的复杂度。
ks-apiserver 的核心架构
ks-apiserver 是 KubeSphere 核心的后端组件,负责前后端数据的交互、请求的代理分发、认证与鉴权。下图是 ks-apiserver 的核心架构:
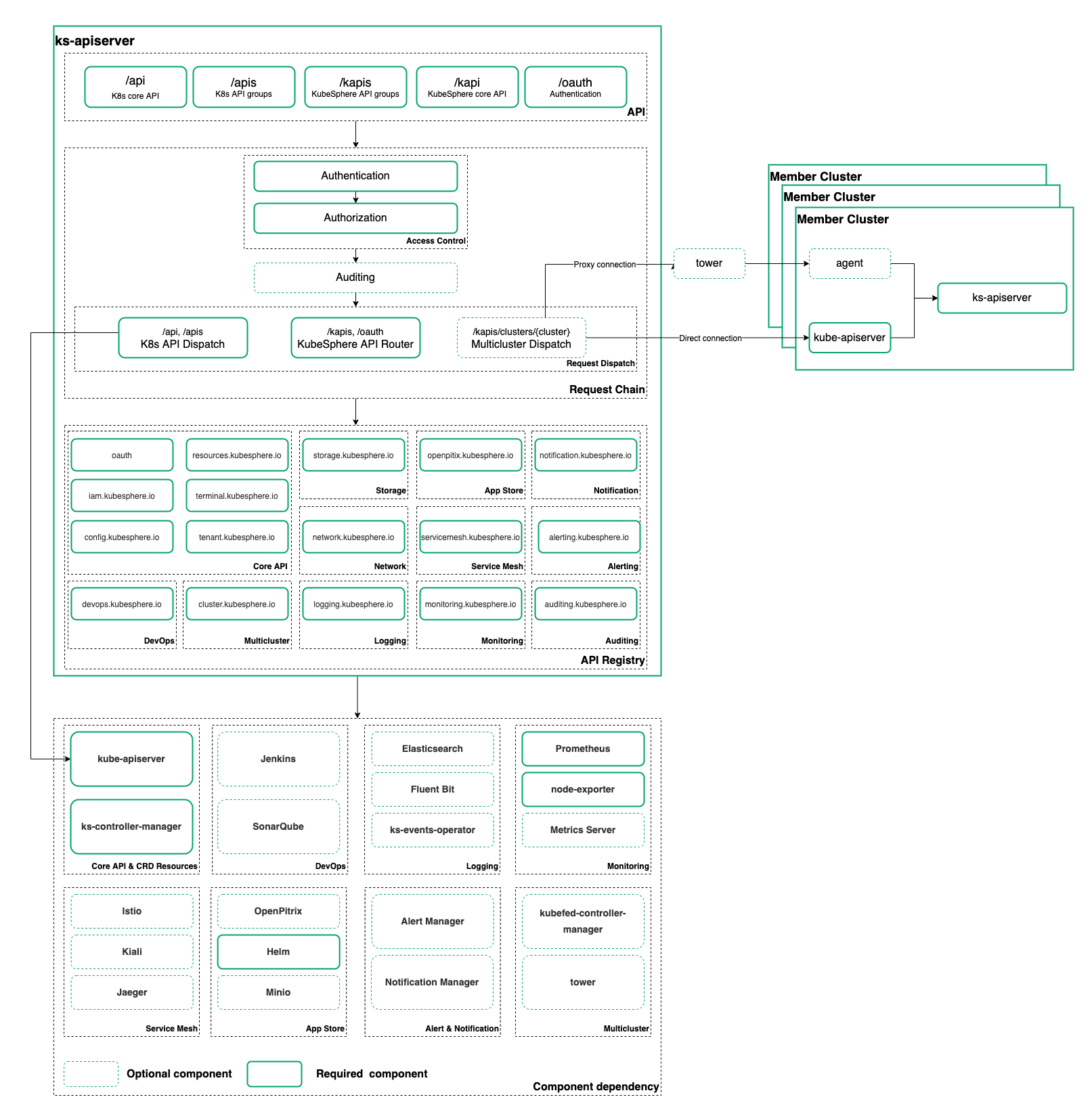
ks-apiserver 的开发使用了 go-restful 框架,可以在请求链路中增加多个 Filter 用于动态的拦截请求和响应,实现认证、鉴权、审计逻辑转发和反向代理功能,KubeSphere 的 API 风格也尽可能的学习 K8s 的模式,方便使用 RBAC 进行权限控制。
借助 CRD + controller 的方式进行解耦,可以极大的简化与第三方工具、软件的集成方式。
K8s 社区也提供了丰富的工具链,借助 controller-runtime 和 kubebuiler 可以迅速的搭建起开发脚手架。
API 聚合与权限控制
可以通过拓展 ks-apiserver 实现 API 的聚合,进一步实现功能拓展、聚合查询等功能。在 API 的开发过程中中需要遵循以下规范,以便与 KubeSphere 的租户体系、资源体系进行整合。
- API 聚合
- 权限控制
- CRD + controller
API 规范
# 通过 api group 进行分组
/apis/{api-group}/{version}/{resources}
# 示例
/apis/apps/v1/deployments
/kapis/iam.kubesphere.io/v1alpha2/users
# api core
/api/v1/namespaces
# 通过 path 区分不同的动作
/api/{version}/watch/{resources}
/api/{version}/proxy/{resources}/{resource}
# 通过 path 区分不同的资源层级
/kapis/{api-group}/{version}/workspaces/{workspace}/{resources}/{resource}
/api/{version}/namespaces/{namespace}/{resource}
规范 API 的目的:
- 更好的对资源进行抽象,抽象为 Object 更适合声明式 API
- 更好的对 API 进行管理,版本、分组、分层,更方便 API 的拓展
- 更好的与权限控制进行整合,可以方便的从请求中获取元数据,apigroup,scope,version,verb
权限控制
KubeSphere 权限控制的核心是 RBAC 基于角色的访问控制。
关键的对象有: Role、User、RoleBinding。
Role 定义了一个角色可以访问的资源。
角色是根据资源层级进行划分的,cluster role、workspace role、namespace role 不同层级的角色定义了该角色在当前层级可以访问的资源。
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: role-grantor
rules:
- apiGroups: ["rbac.authorization.k8s.io"]
resources: ["rolebindings"]
verbs: ["create"]
- apiGroups: ["rbac.authorization.k8s.io"]
resources: ["clusterroles"]
verbs: ["bind"]
# 忽略 resourceNames 意味着允许绑定任何 ClusterRole
resourceNames: ["admin","edit","view"]
- nonResourceURLs: ["/healthz", "/healthz/*"] # nonResourceURL 中的 '*' 是一个全局通配符
verbs: ["get", "post"]
RoleBinding 可绑定角色到某主体(Subject)上。 主体可以是组,用户或者服务账户。
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: role-grantor-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: role-grantor
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: user-1
CRD + controller
自定义资源(Custom Resource) 是对 Kubernetes API 的扩展,可以通过动态注册的方式拓展 K8s API。用户可以使用 kubectl 来创建和访问其中的对象,就像操作内置资源一样。
通过 CRD 对资源进行抽象,再通过 controller 监听资源变化维护资源状态, controller 的核心是 Reconcile,与他的意思一样,通过被动、定时触发的方式对资源状态进行维护,直至达到声明的状态。
以 User 资源为例,我们可以定义一下结构的 CRD 对 User 进行抽象:
apiVersion: iam.kubesphere.io/v1alpha2
kind: User
metadata:
annotations:
iam.kubesphere.io/last-password-change-time: "2021-05-12T05:50:07Z"
name: admin
resourceVersion: "478503717"
selfLink: /apis/iam.kubesphere.io/v1alpha2/users/admin
uid: 9e438fcc-f179-4254-b534-e913dfd7a727
spec:
email: admin@kubesphere.io
lang: zh
description: 'description'
password: $2a$10$w312tzLTvXObnfEYiIrk9u5Nu/reJpwQeI66vrM1XJETWtpjd1/q2
status:
lastLoginTime: "2021-06-08T06:37:36Z"
state: Active
对应的 API 为:
# 创建
POST /apis/iam.kubesphere.io/v1alpha2/users
# 删除
DELETE /apis/iam.kubesphere.io/v1alpha2/users/{username}
# 修改
PUT /apis/iam.kubesphere.io/v1alpha2/users/{username}
PATCH /apis/iam.kubesphere.io/v1alpha2/users/{username}
# 查询
GET /apis/iam.kubesphere.io/v1alpha2/users
GET /apis/iam.kubesphere.io/v1alpha2/users/{username}
ks-apiserver 负责将这些数据写入 K8s 再由 informer 同步到各个副本中。
ks-controller-manager 通过监听数据变化,对资源状态进行维护,以创建用户为例, 通过 POST /apis/iam.kubesphere.io/v1alpha2/users 创建用户之后, user controller 会对用户资源状态进行同步。
func (c *userController) reconcile(key string) error {
// Get the user with this name
user, err := c.userLister.Get(key)
if err != nil {
// The user may no longer exist, in which case we stop
// processing.
if errors.IsNotFound(err) {
utilruntime.HandleError(fmt.Errorf("user '%s' in work queue no longer exists", key))
return nil
}
klog.Error(err)
return err
}
if user, err = c.encryptPassword(user); err != nil {
klog.Error(err)
return err
}
if user, err = c.syncUserStatus(user); err != nil {
klog.Error(err)
return err
}
// synchronization through kubefed-controller when multi cluster is enabled
if c.multiClusterEnabled {
if err = c.multiClusterSync(user); err != nil {
c.recorder.Event(user, corev1.EventTypeWarning, controller.FailedSynced, fmt.Sprintf(syncFailMessage, err))
return err
}
}
c.recorder.Event(user, corev1.EventTypeNormal, successSynced, messageResourceSynced)
return nil
}
通过声明式的 API 将复杂的逻辑放到 controller 进行处理,方便解耦。可以很方便的与其他系统、服务进行集成,例如:
/apis/devops.kubesphere.io/v1alpha2/namespaces/{namespace}/pipelines
/apis/devops.kubesphere.io/v1alpha2/namespaces/{namespace}/credentials
/apis/openpitrix.io/v1alpha2/namespaces/{namespace}/applications
/apis/notification.kubesphere.io/v1alpha2/configs
对应的权限控制策略:
定义一个可以增删改查 user 资源的角色。
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: user-manager
rules:
- apiGroups: ["iam.kubesphere.io"]
resources: ["users"]
verbs: ["create","delete","patch","update","get","list"]
定义一个可以创建 pipeline 资源的角色。
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: devops-manager
rules:
- apiGroups: ["devops.kubesphere.io"]
resources: ["pipelines"]
verbs: ["create","delete","patch","update","get","list"]
本文由博客一文多发平台 OpenWrite 发布!
KubeSphere 核心架构浅析的更多相关文章
- boost.asio源码剖析(二) ---- 架构浅析
* 架构浅析 先来看一下asio的0层的组件图. (图1.0) io_object是I/O对象的集合,其中包含大家所熟悉的socket.deadline_tim ...
- Camera服务之--架构浅析
Camera服务之--架构浅析 分类: Camera 分析2011-12-22 11:17 7685人阅读 评论(3) 收藏 举报 android硬件驱动框架jnilinux内核平台 一.应用层 Ca ...
- 浅谈 jQuery 核心架构设计
jQuery对于大家而言并不陌生,因此关于它是什么以及它的作用,在这里我就不多言了,而本篇文章的目的是想通过对源码简单的分析来讨论 jQuery 的核心架构设计,以及jQuery 是如何利用javas ...
- 谈一谈jQuery核心架构设计(转)
jQuery对于大家而言并不陌生,因此关于它是什么以及它的作用,在这里我就不多言了,而本篇文章的目的是想通过对源码简单的分析来讨论 jQuery 的核心架构设计,以及jQuery 是如何利用javas ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- netty源码解解析(4.0)-1 核心架构
netty是java开源社区的一个优秀的网络框架.使用netty,我们可以迅速地开发出稳定,高性能,安全的,扩展性良好的服务器应用程序.netty封装简化了在服务器开发领域的一些有挑战性的问题:jdk ...
- Others-大数据平台Lambda架构浅析(全量计算+增量计算)
大数据平台Lambda架构浅析(全量计算+增量计算) 2016年12月23日 22:50:53 scuter_victor 阅读数:1642 标签: spark大数据lambda 更多 个人分类: 造 ...
- Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
转自:http://blog.csdn.net/iamdll/article/details/20998035 分类: 分布式 2014-03-11 10:31 156人阅读 评论(0) 收藏 举报 ...
- Hadoop核心架构(1)
在大数据的发展过程中,出现了一批专门应用与大数据的处理分析工具,如Hadoop,Hbase,Hive,Spark等,我们先从最基础的Hadoop开始进行介绍 Hadoop是apache基金会下所开发的 ...
- Scrapy研究探索(三)——Scrapy核心架构与代码执行分析
学习曲线总是这样,简单样例"浅尝".在从理论+实践慢慢攻破.理论永远是基础,切记"勿在浮沙筑高台". 一. 核心架构 关于核心架构.在官方文档中阐述的非常清晰, ...
随机推荐
- 蔡磊公布渐冻症诊断报告 5月住进ICU一度考虑气切
原文地址: https://baijiahao.baidu.com/s?id=1801485780372006198
- deepin国产操作系统 nvidia-docker2 的安装
====================================== 平时偶尔使用deepin系统,突然有个 nvidia-docker 的程序需要运行,平时工作都是在用Ubuntu,所以对d ...
- C# 委托和闭包
前言 本文只是为了复习,巩固,和方便查阅,一些知识点的详细知识会通过相关链接和文献标记出来. 委托是什么 大部分的解释是 委托是一个对方法的引用,可以不用自己执行,而是转交给其他对象.就好比每天都有一 ...
- Inno Setup 寻找 AppId 的方法
背景 有时候打包后,会遗失AppId.这样会导致下一次打包时没办法和之前统一.为了避免这个问题,所以最好是打包时记下来,可以根据注册表去查 解决办法 可以根据任意查找注册表的工具,我这里使用 Regi ...
- 如何利用HMMER鉴定基因家族成员
通常我们用的都是通过blast比对来确定我们需要的家族成员,首先是比对序列,再次是需要目标物种的蛋白序列,来进行比对,通常比对的时候我们都需要设定e-value值.今天我们来学习一下利用HMMER来鉴 ...
- CH03_运算符
CH03_运算符 算术运算符 作用:用于处理四则运算 示例: #include <iostream> using namespace std; int main() { int a = 1 ...
- liunx下安装Nginx
Linux下nginx的安装以及环境配置 https://blog.csdn.net/qq_42815754/article/details/82980326 第一步:下载nginx压缩包 在这里可以 ...
- 记 某List.sort()后排序结果异常
背景:某次查看日志,发现数据不符合预期,希望获取的是降序排序,但是部分数据是乱序的 已知List.sort()方法应该不会出异常,所以应该是判断先后方法出问题了 果然,因为一开始写代码时,没有考虑到差 ...
- 【YashanDB知识库】yac修改参数后关闭数据库hang住
[标题]yac修改参数后关闭数据库hang住 [问题分类]性能优化 [关键词]YashanDB, yac, shutdown hang [问题描述]修改yac参数后执行shutdown immedia ...
- sicp每日一题[1.40]
Exercise 1.40 Define a procedure cubic that can be used together with the newtons-method procedure i ...