人工智能大语言模型起源篇(二),从通用语言微调到驾驭LLM

上一篇:《人工智能大语言模型起源篇(一),从哪里开始》
(5)Howard 和 Ruder 于2018年发表的《Universal Language Model Fine-tuning for Text Classification》,https://arxiv.org/abs/1801.06146
这篇论文从历史的角度来看非常有意思。尽管它是在原始的《Attention Is All You Need》变换器发布一年后写的,但它并没有涉及变换器,而是专注于递归神经网络。然而,它仍然值得注意,因为它有效地提出了语言模型的预训练和迁移学习,用于下游任务。
尽管迁移学习在计算机视觉中已经被确立,但在自然语言处理(NLP)中还不普遍。ULMFit 是首批展示预训练语言模型并对其进行微调,从而在许多NLP任务中取得最先进成果的论文之一。
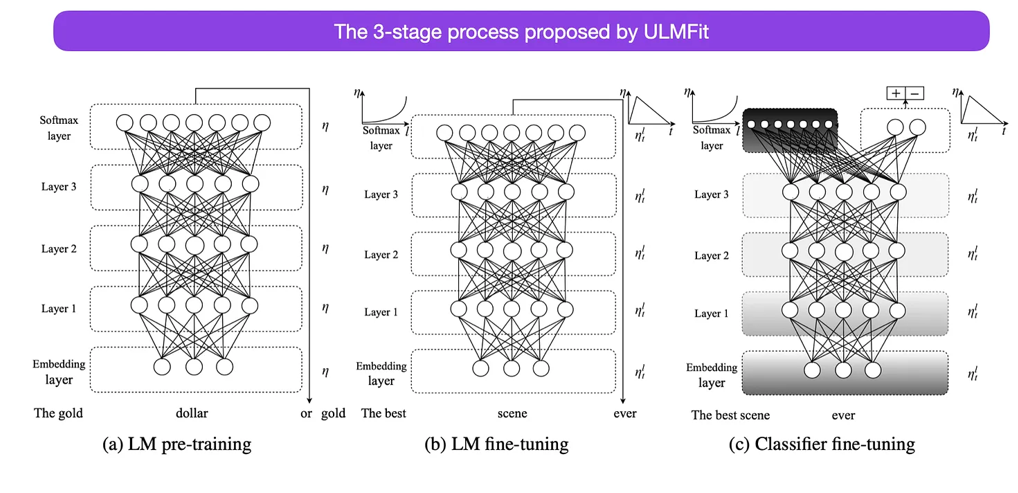
ULMFit 提出的微调语言模型的三阶段过程如下:
在大规模文本语料库上训练语言模型。
在任务特定的数据上微调这个预训练的语言模型,使其能够适应文本的特定风格和词汇。
在任务特定数据上微调分类器,并逐步解冻各层,以避免灾难性遗忘。
这个过程——在大规模语料库上训练语言模型,然后在下游任务上进行微调——是基于变换器的模型和像BERT、GPT-2/3/4、RoBERTa等基础模型所使用的核心方法。
然而,ULMFiT的关键部分——逐步解冻,通常在实践中不会常规进行,尤其是在使用变换器架构时,通常会一次性微调所有层。
来源:https://arxiv.org/abs/1801.06146
(6)Devlin、Chang、Lee 和 Toutanova 于2018年发表的《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》,https://arxiv.org/abs/1810.04805
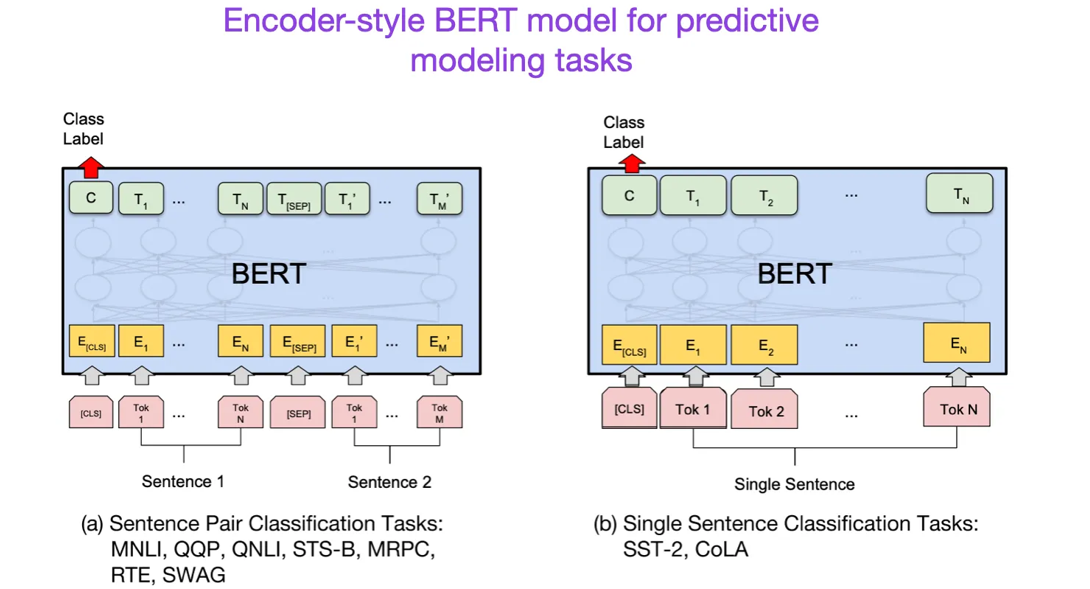
继原始的变换器架构之后,大型语言模型的研究开始分为两个方向:一种是用于预测建模任务(如文本分类)的编码器风格变换器,另一种是用于生成建模任务(如翻译、总结和其他形式的文本生成)的解码器风格变换器。
上面的BERT论文介绍了掩蔽语言模型(masked-language modeling)和下一句预测(next-sentence prediction)这一原始概念。它仍然是最具影响力的编码器风格架构。如果你对这一研究方向感兴趣,我推荐你进一步了解RoBERTa,它通过去除下一句预测任务,简化了预训练目标。
来源:https://arxiv.org/abs/1810.04805
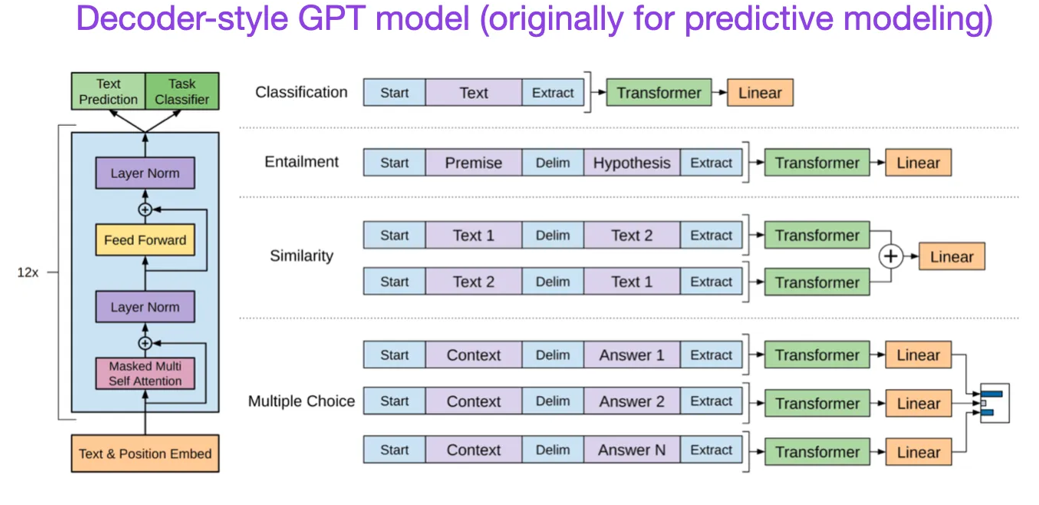
(7)Radford 和 Narasimhan 于2018年发表的《Improving Language Understanding by Generative Pre-Training》,https://www.semanticscholar.org/paper/Improving-Language-Understanding-by-Generative-Radford-Narasimhan/cd18800a0fe0b668a1cc19f2ec95b5003d0a5035
原始的GPT论文介绍了流行的解码器风格架构,并通过下一个词预测进行预训练。BERT可以被看作是一个双向变换器,因为它的预训练目标是掩蔽语言模型,而GPT是一个单向的、自回归模型。虽然GPT的嵌入也可以用于分类任务,但GPT方法是当今最具影响力的大型语言模型(LLM)的核心,例如ChatGPT。
如果你对这个研究方向感兴趣,我建议你进一步阅读GPT-2 https://www.semanticscholar.org/paper/Language-Models-are-Unsupervised-Multitask-Learners-Radford-Wu/9405cc0d6169988371b2755e573cc28650d14dfe和GPT-3 https://arxiv.org/abs/2005.14165的论文。这两篇论文展示了LLM能够进行零-shot和少-shot学习,并突出了LLM的突现能力。GPT-3仍然是当前一代LLM(如ChatGPT)训练的流行基准和基础模型——我们稍后会作为单独的条目讨论导致ChatGPT的InstructGPT方法。
来源: https://www.semanticscholar.org/paper/Improving-Language-Understanding-by-Generative-Radford-Narasimhan/cd18800a0fe0b668a1cc19f2ec95b5003d0a5035
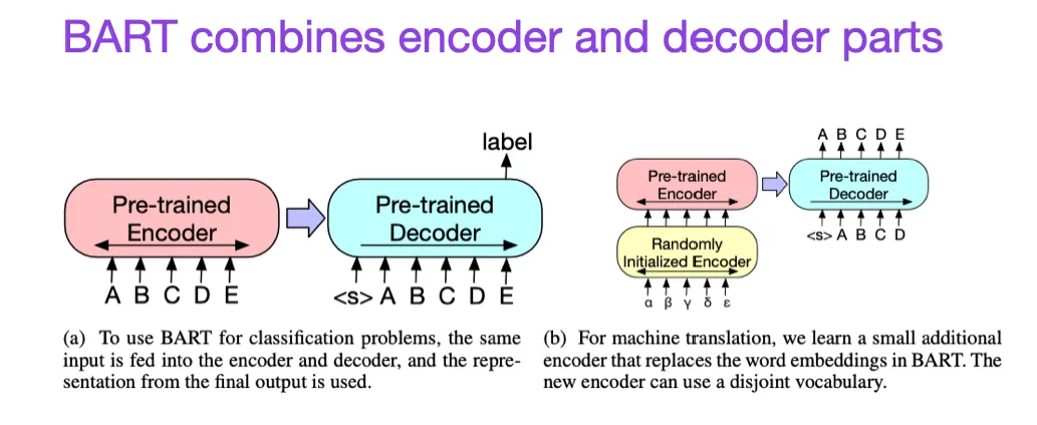
(8)Lewis、Liu、Goyal、Ghazvininejad、Mohamed、Levy、Stoyanov 和 Zettlemoyer 于2019年发表的《BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension》,https://arxiv.org/abs/1910.13461
如前所述,BERT类型的编码器风格LLM通常更适用于预测建模任务,而GPT类型的解码器风格LLM则更擅长生成文本。为了兼顾两者的优点,上面的BART论文将编码器和解码器部分结合在一起(这与原始的变换器架构(本清单中的第二篇论文)并无太大区别)。
来源:https://arxiv.org/abs/1910.13461
(9)Yang、Jin、Tang、Han、Feng、Jiang、Yin 和 Hu 于2023年发表的《Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond》,https://arxiv.org/abs/2304.13712
这不是一篇研究论文,但可能是迄今为止最好的架构综述,展示了不同架构的演变过程。然而,除了讨论BERT风格的掩蔽语言模型(编码器)和GPT风格的自回归语言模型(解码器)外,它还提供了关于预训练和微调数据的有用讨论和指导。
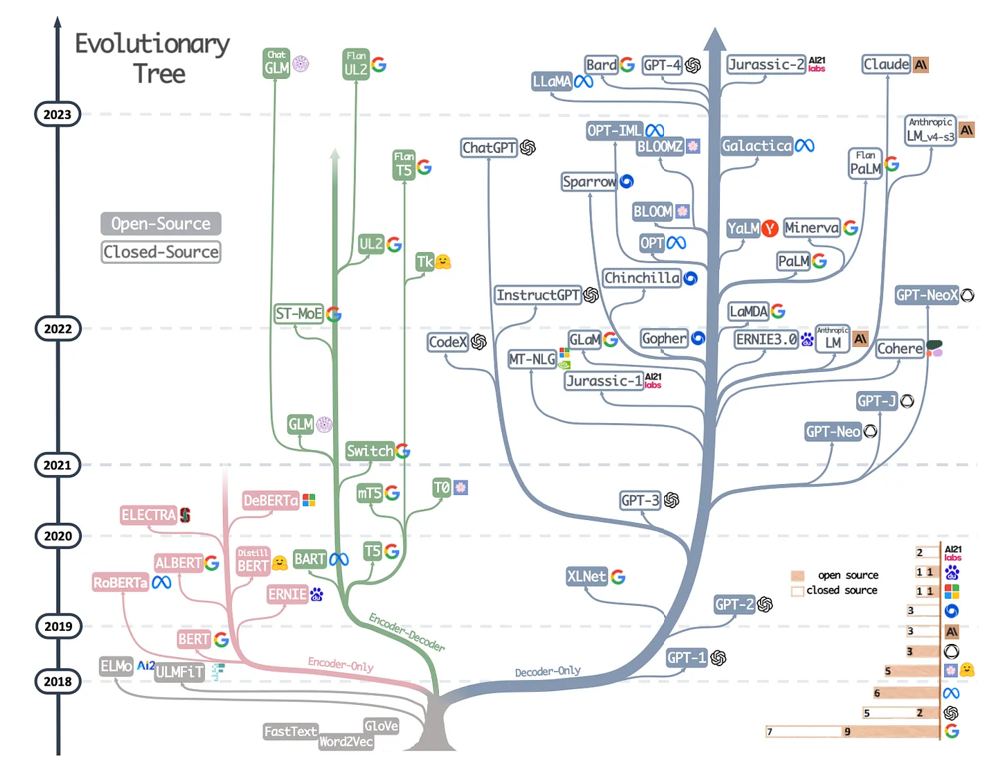
现代 LLM 的进化树,来自 https://arxiv.org/abs/2304.13712。
人工智能大语言模型起源篇(二),从通用语言微调到驾驭LLM的更多相关文章
- 本地推理,单机运行,MacM1芯片系统基于大语言模型C++版本LLaMA部署“本地版”的ChatGPT
OpenAI公司基于GPT模型的ChatGPT风光无两,眼看它起朱楼,眼看它宴宾客,FaceBook终于坐不住了,发布了同样基于LLM的人工智能大语言模型LLaMA,号称包含70亿.130亿.330亿 ...
- 看过《大湿教我写.net通用权限框架(1)之菜单导航篇》之后发生的事(续)——主界面
引言 在UML系列学习中的小插曲:看过<大湿教我写.net通用权限框架(1)之菜单导航篇>之后发生的事 在上篇中只拿登录界面练练手,不把主界面抠出来,实在难受,严重的强迫症啊.之前一直在总 ...
- 【基于WinForm+Access局域网共享数据库的项目总结】之篇二:WinForm开发扇形图统计和Excel数据导出
篇一:WinForm开发总体概述与技术实现 篇二:WinForm开发扇形图统计和Excel数据导出 篇三:Access远程连接数据库和窗体打包部署 [小记]:最近基于WinForm+Access数据库 ...
- 人工智能大数据,公开的海量数据集下载,ImageNet数据集下载,数据挖掘机器学习数据集下载
人工智能大数据,公开的海量数据集下载,ImageNet数据集下载,数据挖掘机器学习数据集下载 ImageNet挑战赛中超越人类的计算机视觉系统微软亚洲研究院视觉计算组基于深度卷积神经网络(CNN)的计 ...
- zz【清华NLP】图神经网络GNN论文分门别类,16大应用200+篇论文最新推荐
[清华NLP]图神经网络GNN论文分门别类,16大应用200+篇论文最新推荐 图神经网络研究成为当前深度学习领域的热点.最近,清华大学NLP课题组Jie Zhou, Ganqu Cui, Zhengy ...
- 保姆级教程:用GPU云主机搭建AI大语言模型并用Flask封装成API,实现用户与模型对话
导读 在当今的人工智能时代,大型AI模型已成为获得人工智能应用程序的关键.但是,这些巨大的模型需要庞大的计算资源和存储空间,因此搭建这些模型并对它们进行交互需要强大的计算能力,这通常需要使用云计算服务 ...
- 【基于WPF+OneNote+Oracle的中文图片识别系统阶段总结】之篇二:基于OneNote难点突破和批量识别
篇一:WPF常用知识以及本项目设计总结:http://www.cnblogs.com/baiboy/p/wpf.html 篇二:基于OneNote难点突破和批量识别:http://www.cnblog ...
- SQL Server调优系列玩转篇二(如何利用汇聚联合提示(Hint)引导语句运行)
前言 上一篇我们分析了查询Hint的用法,作为调优系列的最后一个玩转模块的第一篇.有兴趣的可以点击查看:SQL Server调优系列玩转篇(如何利用查询提示(Hint)引导语句运行) 本篇继续玩转模块 ...
- 大数据工具篇之Hive与MySQL整合完整教程
大数据工具篇之Hive与MySQL整合完整教程 一.引言 Hive元数据存储可以放到RDBMS数据库中,本文以Hive与MySQL数据库的整合为目标,详细说明Hive与MySQL的整合方法. 二.安装 ...
- 大数据工具篇之Hive与HBase整合完整教程
大数据工具篇之Hive与HBase整合完整教程 一.引言 最近的一次培训,用户特意提到Hadoop环境下HDFS中存储的文件如何才能导入到HBase,关于这部分基于HBase Java API的写入方 ...
随机推荐
- MyBatisPlus——代码生成器
代码生成器 快速生成各项代码 步骤 创建Generator类,并创建main方法 创建代码生成器 AutoGenerator autoGenerator = new AutoGenerator(); ...
- JavaScript——事件监听
事件监听 1.事件绑定 2.常见事件
- 从0到1搭建权限管理系统系列四 .net8 中Autofac的使用(附源码)
说明 该文章是属于OverallAuth2.0系列文章,每周更新一篇该系列文章(从0到1完成系统开发). 该系统文章,我会尽量说的非常详细,做到不管新手.老手都能看懂. 说明:OverallAuth2 ...
- std::vector 和 std::map 都支持以下比较运算符
在 C++ 标准库中,std::vector 和 std::map 都支持以下比较运算符: ==(相等运算符) !=(不等运算符) <(小于运算符) <=(小于等于运算符) >(大于 ...
- /proc/buddyinfo
在应用程序设计过程中,内存是很重要的资源,而计算机主机的内存资源时有限的.一般而言我们可以申请到的内存是有限的,并不是想申请多大就有多大就可以申请多大的./proc/buddyinfo文件里,就记录着 ...
- KubeSphere 社区双周报|2024.02.29-03.14
KubeSphere 社区双周报主要整理展示新增的贡献者名单和证书.新增的讲师证书以及两周内提交过 commit 的贡献者,并对近期重要的 PR 进行解析,同时还包含了线上/线下活动和布道推广等一系列 ...
- 带你一起看看nginx如何部署安装
nginx部署安装 Linux安装 源码构建Nginx 管理器安装 windows安装 首先需要下载Nginx软件包 nginx软件官方下载地址: nginx官方下载连接 建议选择稳定的软件版本,如果 ...
- nginx实现资源文件动静分离的记录
Nginx 动静分离简单来说就是把动态跟静态请求分开,不能理解成只是单纯的把动态页面和静态页面物理分离.严格意义上说应该是动态请求跟静态请求分开,可以理解成使用 Nginx 处理静态页面,Tomcat ...
- 什么DevOps方法论?
最近项目组事情越来越多,人员管理和项目事项管理成为了重点关注的问题,无意间听到同事间讨论DevOps方法论可以有效提升项目管理能力,实现组织精益化管理,运维一体化.于是我上网查了一下"Dev ...
- Linux环境下非GUI制作图形界面方法
Linux环境下非GUI制作图形界面方法 如题,即就是仅仅使用ANSI转义字符实现Linux环境的页面效果,如字体颜色.背景颜色.高亮.固定位置光标.将光标放到指定位置.隐藏字符串等等. 具体实现方法 ...